Jmeter接口测试响应数据中文显示为Unicode码的解决方法
发布时间:2024年01月05日
问题:使用jmeter测试接口,返回响应数据汉字显示为Unicode
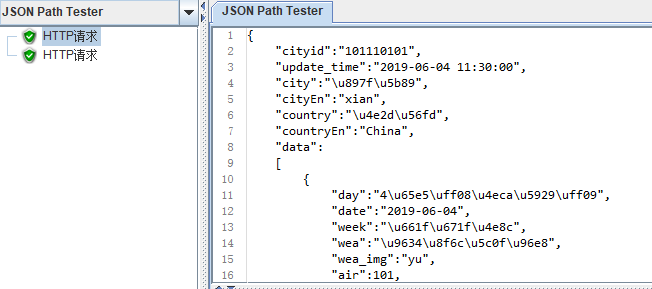
解决结果:
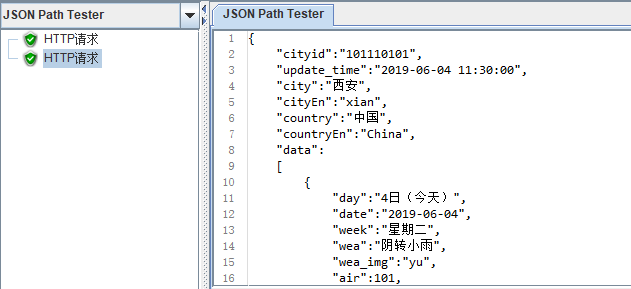
解决过程:
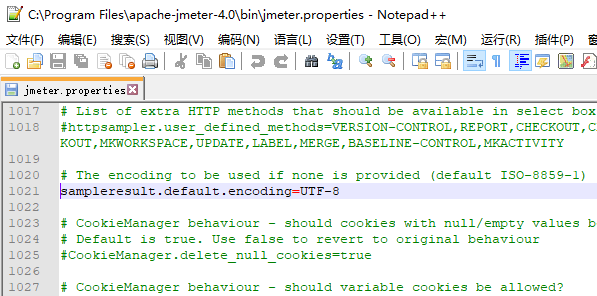
1.修改jmeter配置文件中的默认编码
在Jmeter的安装路径下打开bin文件夹下的jmeter.properties文件,搜索关键词default.encoding定位到语句【#sampleresult.default.encoding=ISO-8859-1】。
将注释#删掉,并改成utf-8编码,如下:
?2.添加后置处理器BeanShellPostProcessor和转码代码
添加后置处理器BeanShellPostProcessor,在Script中附上转码代码
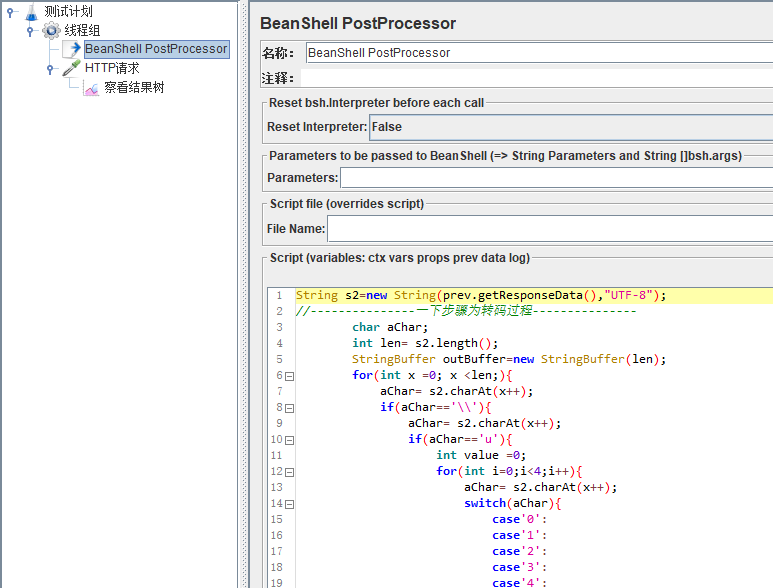
转码代码如下:
复制
//获取响应代码Unicode编码的
String s2=new String(prev.getResponseData(),"UTF-8");
//---------------以下步骤为转码过程---------------
char aChar;
int len= s2.length();
StringBuffer outBuffer=new StringBuffer(len);
for(int x =0; x <len;){
aChar= s2.charAt(x++);
if(aChar=='\\'){
aChar= s2.charAt(x++);
if(aChar=='u'){
int value =0;
for(int i=0;i<4;i++){
aChar= s2.charAt(x++);
switch(aChar){
case'0':
case'1':
case'2':
case'3':
case'4':
case'5':
case'6':
case'7':
case'8':
case'9':
value=(value <<4)+aChar-'0';
break;
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
value=(value <<4)+10+aChar-'a';
break;
case'A':
case'B':
case'C':
case'D':
case'E':
case'F':
value=(value <<4)+10+aChar-'A';
break;
default:
throw new IllegalArgumentException(
"Malformed \\uxxxx encoding.");}}
outBuffer.append((char) value);}else{
if(aChar=='t')
aChar='\t';
else if(aChar=='r')
aChar='\r';
else if(aChar=='n')
aChar='\n';
else if(aChar=='f')
aChar='\f';
outBuffer.append(aChar);}}else
outBuffer.append(aChar);}
prev.setResponseData(outBuffer.toString());?PS:
1.原理:通过BeanShell内置变量prev,获得响应数据,经过java程序编码,把Unicode代码转成中文,最后修改查看结果树中响应数据为转换完毕的中文
2.在性能试前,请把这个后置处理器删除,不然会大量消耗本机的内存和CPU,影响性能的结果
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
?
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取?

?
文章来源:https://blog.csdn.net/hlsxjh/article/details/135417193
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言编程第二章-C语言程序设计的初步知识(1)
- 爬虫学习(1)--requests模块的使用
- Codeforces Good Bye 2023 题解 | JorbanS
- 中断产生流程
- 逆向使用webpack打包的网站
- Java-枚举
- c++可调用对象、function类模板与std::bind
- 中西部翻译协会共同体执行秘书长受邀参加安徽省翻译协会23年会
- 基于SSM的游戏资源管理系统+vue论文
- 来聊聊Spring的循环依赖