实现中文jieba分词
发布时间:2024年01月04日
目录
问题描述:
使用中文分词库jieba从给定的文本中提取指定范围内的前后词语。
特殊的,如果前面是‘的’即再向前取一位,这个可根据自己的实际需求做出更改。
代码实现:
import jieba
from pdb import set_trace as stop
def get_front_end_word(text, span):
text_seg_list = jieba.cut(text, cut_all=False)
span_seg_list = jieba.cut(span,cut_all=False )
text_result = " ".join(text_seg_list)
span_result = " ".join(span_seg_list)
index = text_result.find(span_result) # 获取最后一个位置
front_word =text_result[:index].split()[-1] # 获取前一个元素index
if front_word == '的':
front_front_word = text_result[:index-2].split()[-1] # 因为有一个空格,所以是-2
front_word = front_front_word+front_word
end_word = text_result[index + len(span_result):].split()[0] # 至于后面的0要不要添加,需要依据统计结果而定
return front_word, end_word
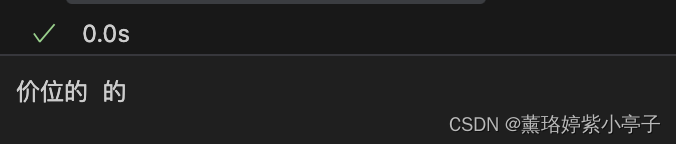
text="比同等价位的惠普华硕宏基的做功要好,但还是很粗糙,性能够用。"
span = "惠普华硕宏基"
front_index, end_index = get_front_end_word(text, span)
print(front_index, end_index)运行结果:
文章来源:https://blog.csdn.net/weixin_41862755/article/details/135390534
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!