YOLOv8改进 | 主干篇 | 利用MobileNetV1替换Backbone(轻量化网络结构)
一、本文介绍
本文给大家带来的改进机制是MobileNetV1,其是专为移动和嵌入式视觉应用设计的轻量化网络结构。这些模型基于简化的架构,并利用深度可分离卷积构建轻量级深度神经网络,其引入了两个简单的全局超参数,用于在延迟和准确性之间进行有效的权衡。实验表明,MobileNets在资源和准确性的权衡方面表现出色,并在多种应用(如对象检测、细粒度分类、面部属性识别和大规模地理定位)中展现了其有效性,这个模型非常适合轻量化的读者来使用。
适用检测目标:轻量化网络结构适合轻量化的读者
推荐指数:???
效果回顾展示->
 ?
?
MobileNetV2地址:
MobileNetV3地址:
目录
二、MobileNetV1的框架原理
 ?官方论文地址:?论文地址点击即可跳转
?官方论文地址:?论文地址点击即可跳转
官方代码地址:?官方代码地址

MobileNetV1的论文《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》介绍了一种高效的模型集合,专为移动和嵌入式视觉应用设计。这些模型基于简化的架构,并利用深度可分离卷积构建轻量级深度神经网络,从而适应移动和嵌入式设备的计算和存储限制。这种架构包含两个步骤:深度卷积(Depthwise Convolution)用于单独处理每个输入通道,然后是逐点卷积(Pointwise Convolution),用于整合深度卷积的输出。通过这种分解,MobileNet显著减少了模型的大小和计算复杂度,同时保持了良好的性能。论文还引入了两个全局超参数,允许在网络大小、速度和准确性之间进行灵活的权衡。
MobileNet的主要创新点包括:
1. 深度可分离卷积:该网络架构使用深度可分离卷积代替标准卷积,显著减少模型参数和计算量。
2. 宽度乘数:提供了一个超参数来调节网络的宽度,从而使得模型可以根据需要进行缩放,适应不同的性能和资源要求。
3. 分辨率乘数:允许调整输入图像的分辨率,进一步减少计算量。
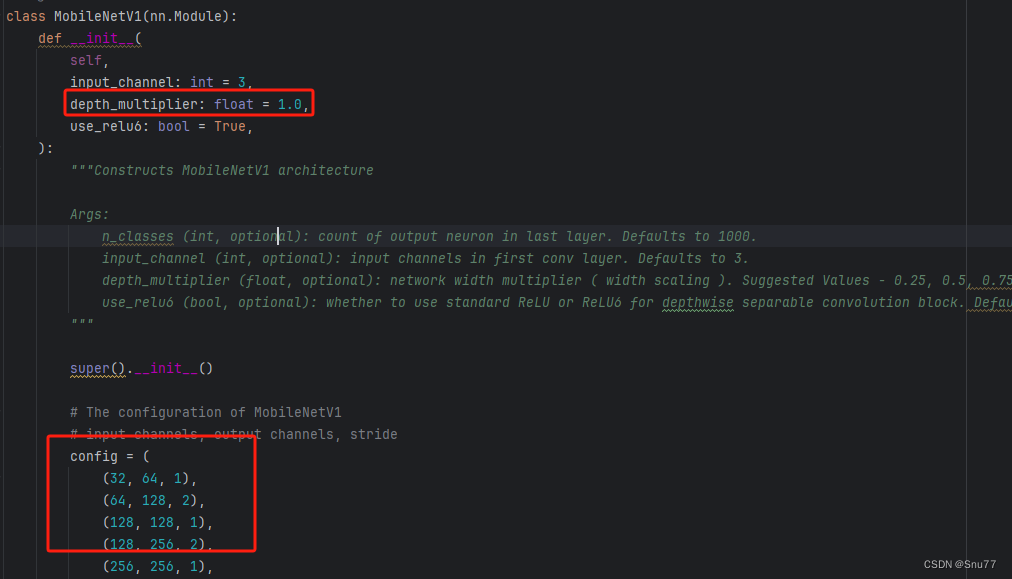
其中第二点和第三点,在代码中很清楚的就能看到如下图红框的所示,分别对应第二点和第三点。
深度可分离卷积如下图所示?
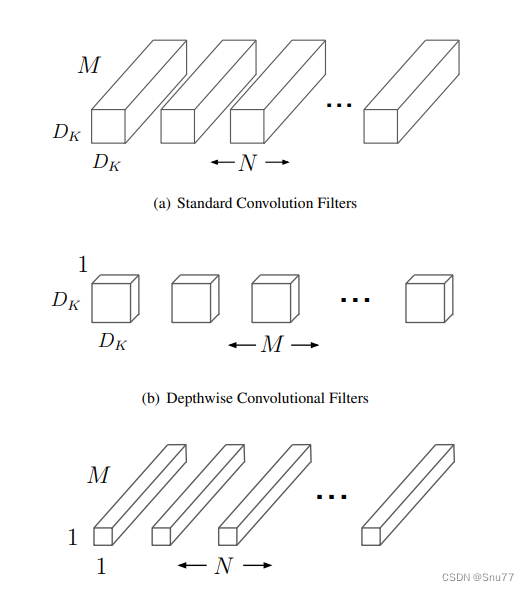
这张图片描绘了深度可分离卷积的概念,其中标准的卷积滤波器(a)被分解为两个独立的层:深度卷积(b)和逐点卷积(c)。在深度卷积中,每个输入通道独立应用一个滤波器,而逐点卷积则使用1x1的卷积核来组合深度卷积的输出。这种分解方法显著减少了计算量,因为它将卷积操作分为两个更简单的步骤:一个是应用于每个通道的滤波(深度卷积),另一个是这些滤波输出的组合(逐点卷积)。?
三、MobileNetV1的核心代码
下面的代码是整个MobileNetV1的核心代码,大家如果想学习可以和上面的框架原理对比着看一看估计会有一定的收获,使用方式看章节四。
"""A from-scratch implementation of original MobileNet paper ( for educational purposes ).
Paper
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications - https://arxiv.org/abs/1704.04861
author : shubham.aiengineer@gmail.com
"""
import torch
from torch import nn
class DepthwiseSepConvBlock(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
stride: int = 1,
use_relu6: bool = True,
):
"""Constructs Depthwise seperable with pointwise convolution with relu and batchnorm respectively.
Args:
in_channels (int): input channels for depthwise convolution
out_channels (int): output channels for pointwise convolution
stride (int, optional): stride paramemeter for depthwise convolution. Defaults to 1.
use_relu6 (bool, optional): whether to use standard ReLU or ReLU6 for depthwise separable convolution block. Defaults to True.
"""
super().__init__()
# Depthwise conv
self.depthwise_conv = nn.Conv2d(
in_channels,
in_channels,
(3, 3),
stride=stride,
padding=1,
groups=in_channels,
)
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu1 = nn.ReLU6() if use_relu6 else nn.ReLU()
# Pointwise conv
self.pointwise_conv = nn.Conv2d(in_channels, out_channels, (1, 1))
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU6() if use_relu6 else nn.ReLU()
def forward(self, x):
"""Perform forward pass."""
x = self.depthwise_conv(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.pointwise_conv(x)
x = self.bn2(x)
x = self.relu2(x)
return x
class MobileNetV1(nn.Module):
def __init__(
self,
input_channel: int = 3,
depth_multiplier: float = 1.0,
use_relu6: bool = True,
):
"""Constructs MobileNetV1 architecture
Args:
n_classes (int, optional): count of output neuron in last layer. Defaults to 1000.
input_channel (int, optional): input channels in first conv layer. Defaults to 3.
depth_multiplier (float, optional): network width multiplier ( width scaling ). Suggested Values - 0.25, 0.5, 0.75, 1.. Defaults to 1.0.
use_relu6 (bool, optional): whether to use standard ReLU or ReLU6 for depthwise separable convolution block. Defaults to True.
"""
super().__init__()
# The configuration of MobileNetV1
# input channels, output channels, stride
config = (
(32, 64, 1),
(64, 128, 2),
(128, 128, 1),
(128, 256, 2),
(256, 256, 1),
(256, 512, 2),
(512, 512, 1),
(512, 512, 1),
(512, 512, 1),
(512, 512, 1),
(512, 512, 1),
(512, 1024, 2),
(1024, 1024, 1),
)
self.model = nn.Sequential(
nn.Conv2d(
input_channel, int(32 * depth_multiplier), (3, 3), stride=2, padding=1
)
)
# Adding depthwise block in the model from the config
for in_channels, out_channels, stride in config:
self.model.append(
DepthwiseSepConvBlock(
int(in_channels * depth_multiplier), # input channels
int(out_channels * depth_multiplier), # output channels
stride,
use_relu6=use_relu6,
)
)
self.index = [128, 256, 512, 1024]
self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def forward(self, x):
"""Perform forward pass."""
results = [None, None, None, None]
for model in self.model:
x = model(x)
if x.size(1) in self.index:
position = self.index.index(x.size(1)) # Find the position in the index list
results[position] = x
return results
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 3, 224, 224)
image = torch.rand(*image_size)
# Model
mobilenet_v1 = MobileNetV1(depth_multiplier=1)
out = mobilenet_v1(image)
print(out)?四、手把手教你添加MobileNetV1网络结构
这个主干的网络结构添加起来算是所有的改进机制里最麻烦的了,因为有一些网略结构可以用yaml文件搭建出来,有一些网络结构其中的一些细节根本没有办法用yaml文件去搭建,用yaml文件去搭建会损失一些细节部分(而且一个网络结构设计很多细节的结构修改方式都不一样,一个一个去修改大家难免会出错),所以这里让网络直接返回整个网络,然后修改部分 yolo代码以后就都以这种形式添加了,以后我提出的网络模型基本上都会通过这种方式修改,我也会进行一些模型细节改进。创新出新的网络结构大家直接拿来用就可以的。下面开始添加教程->
(同时每一个后面都有代码,大家拿来复制粘贴替换即可,但是要看好了不要复制粘贴替换多了)
修改一
我们复制网络结构代码到“ultralytics/nn/modules”目录下创建一个py文件复制粘贴进去 ,我这里起的名字是MobileNetV1。
?
修改二
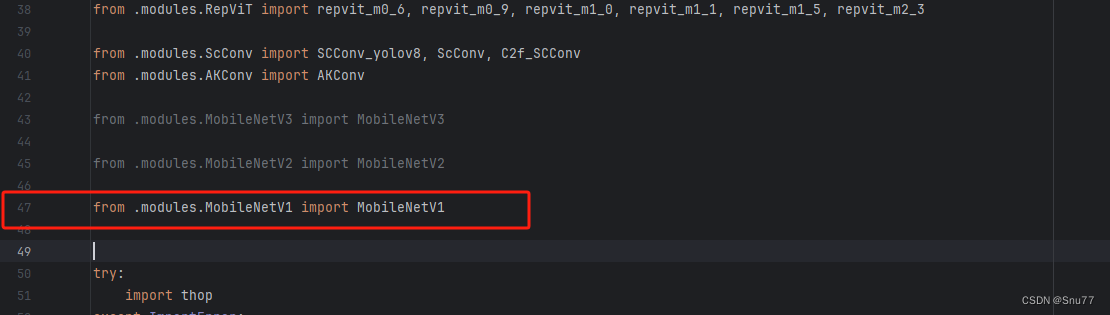
找到如下的文件"ultralytics/nn/tasks.py" 在开始的部分导入我们的模型如下图。
 ?
?
from .modules.MobileNetV1 import MobileNetV1修改三?
添加如下两行代码!!!
 ?
?
修改四
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名。
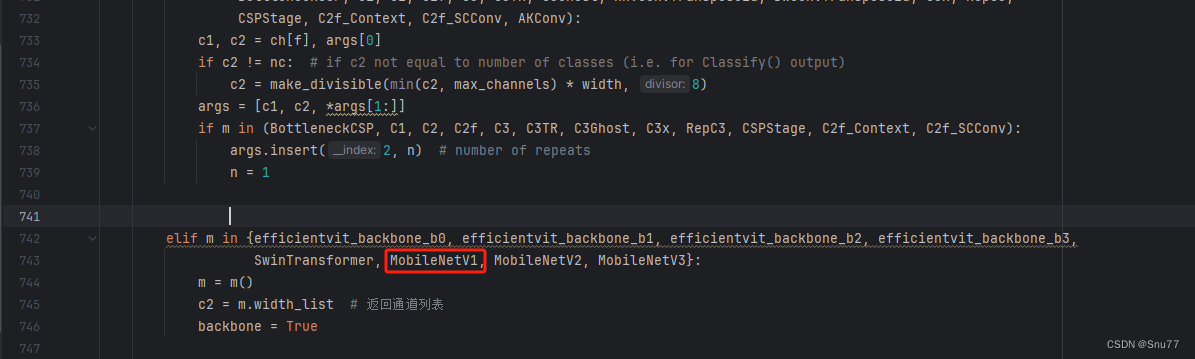 ?
?
elif m in {自行添加对应的模型即可,下面都是一样的}:
m = m()
c2 = m.width_list # 返回通道列表
backbone = True修改五?
下面的两个红框内都是需要改动的。?
 ?
?
if isinstance(c2, list):
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type修改六?
如下的也需要修改,全部按照我的来。
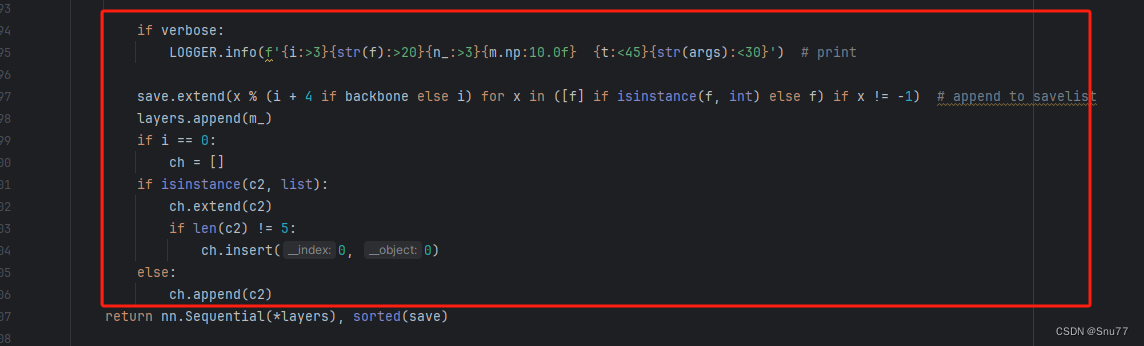 ?
?
代码如下把原先的代码替换了即可。?
if verbose:
LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
if len(c2) != 5:
ch.insert(0, 0)
else:
ch.append(c2)修改七
修改七和前面的都不太一样,需要修改前向传播中的一个部分,?已经离开了parse_model方法了。
可以在图片中开代码行数,没有离开task.py文件都是同一个文件。 同时这个部分有好几个前向传播都很相似,大家不要看错了,是70多行左右的!!!,同时我后面提供了代码,大家直接复制粘贴即可,有时间我针对这里会出一个视频。
 ?
?
代码如下->
def _predict_once(self, x, profile=False, visualize=False):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
if len(x) != 5: # 0 - 5
x.insert(0, None)
for index, i in enumerate(x):
if index in self.save:
y.append(i)
else:
y.append(None)
x = x[-1] # 最后一个输出传给下一层
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x到这里就完成了修改部分,但是这里面细节很多,大家千万要注意不要替换多余的代码,导致报错,也不要拉下任何一部,都会导致运行失败,而且报错很难排查!!!很难排查!!!?
修改八
我们找到如下文件'ultralytics/utils/torch_utils.py'按照如下的图片进行修改。
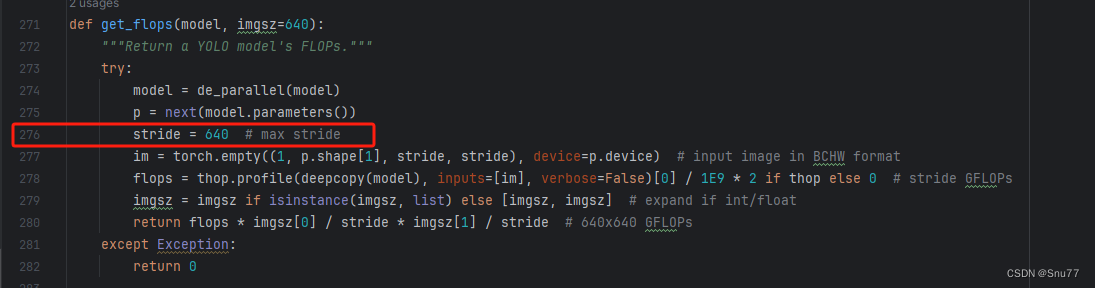 ?
?
五、MobileNetV1的yaml文件
复制如下yaml文件进行运行!!!?
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, MobileNetV1, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
六、成功运行记录?
下面是成功运行的截图,已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。? ?
?
七、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- K8S--kubectl --dry-run
- git中常用的tag命令
- GreptimeDB v0.6 发布 | 支持 Datanodes 间迁移数据表 Region
- Selenium自动化测试实战
- alertmanage调用企业微信告警(k8s内部署)
- 瑞熙贝通实验室开放预约管理系统v3.0详细介绍 原
- [python语言]数据类型
- UI 自动化测试框架:PO 模式+数据驱动
- LLM大语言模型(二):Streamlit 无需前端经验也能画web页面
- 期末考试发等级发成绩,就用易查分!