基于MacBook Pro M1芯片运行chatglm2-6b大模型
发布时间:2024年01月22日
文章目录
1. 参考
2. ChatGLM2-6B 介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能。
- 更长的上下文。
- 更高效的推理。
- 更开放的协议。
详细介绍参考官方README介绍。
3. 本地运行
3.1 硬件配置
- 芯片:Apple M1 Pro
- 内存:32 GB
3.2 下载ChatGLM2-6B代码
cd /Users/joseph.wang/llm
git clone https://github.com/THUDM/ChatGLM2-6B
3.3 下载需要加载的模型
此步骤下载模型需要科学上网,同时需要耐心,因为下载的时间会比较长。
cd /Users/joseph.wang/llm/ChatGLM-6B
mkdir model
cd model
git lfs install
git clone https://huggingface.co/THUDM/chatglm2-6b
3.4 运行大模型
3.4.1 安装依赖
cd /Users/joseph.wang/llm/ChatGLM-6B
pip install -r requirements.txt
其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
3.4.2 编辑web_demo.py
cd /Users/joseph.wang/llm/ChatGLM-6B
...
...
# 修改为通过本地加载大模型,这里改本地下载后大模型的路径即可。
tokenizer = AutoTokenizer.from_pretrained("/Users/joseph.wang/llm/ChatGLM-6B/model/chatglm2-6b", trust_remote_code=True)
# 参考 [Mac M1 部署](https://github.com/THUDM/ChatGLM2-6B/blob/main/README.md#mac-%E9%83%A8%E7%BD%B2) 即可
model = AutoModel.from_pretrained("/Users/joseph.wang/llm/ChatGLM-6B/model/chatglm2-6b", trust_remote_code=True).to('mps')
...
...
# 修改本地启动的端口
demo.queue().launch(share=True, inbrowser=True, server_port=1185)
3.4.3 启动
python web_demo.py

内存消耗

4. 测试
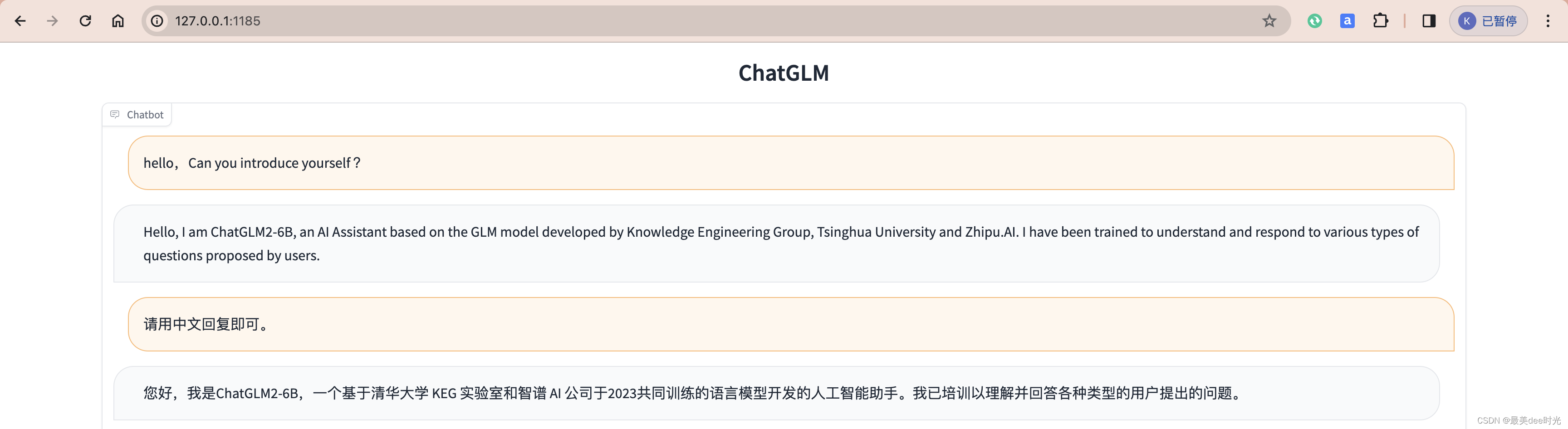
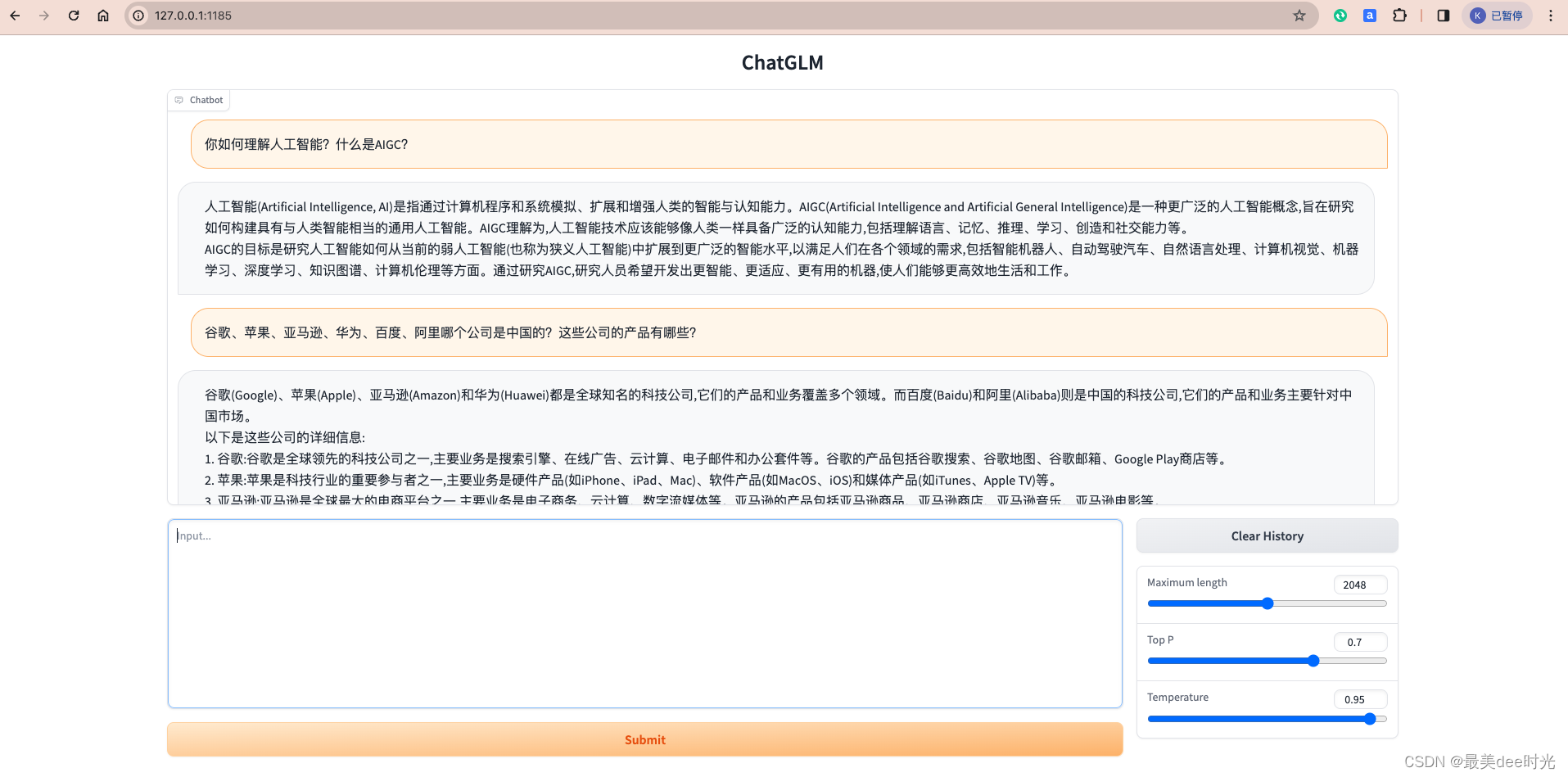
文章来源:https://blog.csdn.net/weixin_44729138/article/details/135758203
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- conda虚拟环境搭建和打包,删除,移动等全流程及相关问题汇总
- 关于:大模型的「幻觉」
- golang二分查找算法实现
- 有哪些简单、免费、适合中小型企业的 CRM 软件?
- 免费的GA/T 1400视图库服务平台
- 处理HTTP请求的gzip压缩
- NodeMCU ESP8266开发流程详解(图文并茂)
- 宠物房市场分析:到 2025 年市场规模将达到 26 亿元
- 请查收“链上天眼”2023年成绩单
- signal.find_peaks寻峰原理