MSDN:Mutually Semantic Distillation Network for Zero-Shot Learning 中文版 待更新
摘要
零样本学习(ZSL)的关键挑战是如何将潜在的语义知识融合在可见类的视觉特征和抽象特征之间,从而实现向不可见类的横向知识转移。之前的工作要么只是将图像的全局特征与其相关的类语义向量对齐,要么利用单向注意力来学习有限的潜在语义表示,这无法有效地发现视觉特征和属性特征之间的内在语义知识(如属性语义)。为了解决上述难题,我们提出了一个相互语义蒸馏网络(MSDN),它逐步蒸馏视觉和属性特征之间的内在语义表示,用于ZSL。MSDN 包含一个属性→视觉注意力子网络,学习基于属性的视觉特征,以及视觉→属性注意力子网,学习基于视觉的属性特征。通过进一步引入语义蒸馏损失,两个相互关注的子网络能够在整个训练过程中协同学习并相互教学。拟议的MSDN在强大的基线基础上取得了重大改进,在三个流行的具有挑战性的基准上取得了新的最先进性能。我们的代码可以在以下网址获得:https://github.com/shiming-chen/MSDN.
1.Introduction
最近,深度学习在目标识别方面取得了成就[12,39,40]。基于已见类别的事先知识,人类具有使用可见和不可见类别的共享和独特属性来识别新概念(类别)的卓越能力[17]。受此认知能力的启发,零样本学习(ZSL)在具有挑战性的图像分类设置下被提出,以模仿人类的认知过程[19,28]。ZSL旨在通过将语义知识从可见类转移到不可见类来解决不可见类别的识别问题。它通常基于以下假设:可见和不可见类别都可以通过共享语义描述(例如属性)来描述[18]。根据模型在测试阶段看到的类别,ZSL方法可分为传统ZSL(CZSL)和广义ZSL(GZSL)[44],其中CZSL旨在预测不可见类别,而GZSL可以预测可见和不可见类别。
ZSL已经取得了显著的进展,许多努力集中在基于嵌入的方法、生成方法和基于共同空间学习的方法上。如图2(a)所示,基于嵌入的方法旨在学习视觉→语义映射,将视觉特征映射到语义空间以进行视觉-语义交互[2,4,5,32,46,48]。基于嵌入的方法通常在GZSL设置下对可见类有较大的偏见,因为嵌入函数仅通过可见类样本学习。为了解决这个问题,提出了生成ZSL方法(参见图2(b)),旨在学习语义→视觉映射,以生成不可见类的视觉特征[3,6,8,34,35,38,43,50],从而将ZSL转化为常规分类问题。如图2(c)所示,共同空间学习学习一个共同的表示空间,其中视觉特征和语义表示都被投影以进行知识转移[7,10,23,34,37,41]。然而,它们只是利用全局特征表示,忽略了训练图像中的精细细节。
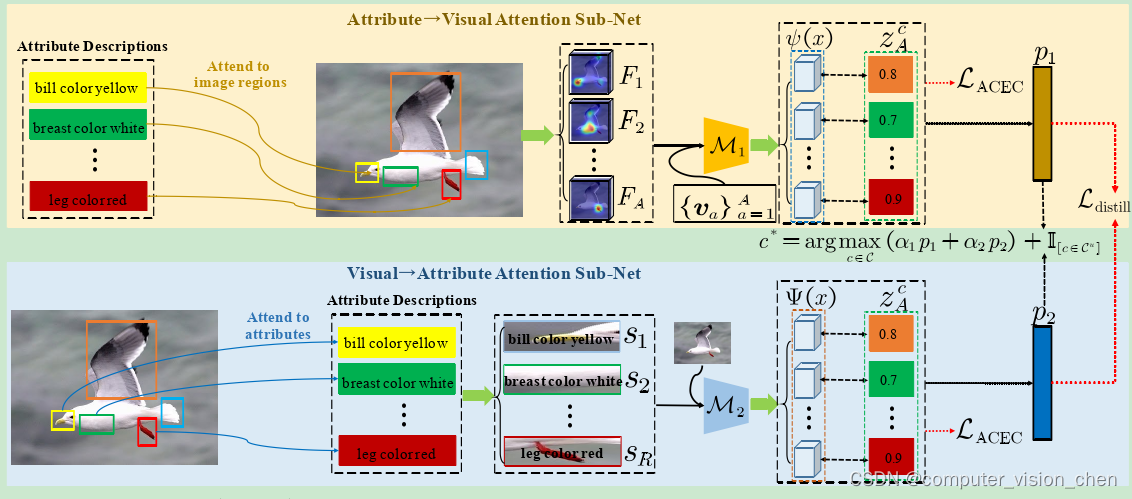
如图1所示,不可见样本与一组可见样本共享不同的部分信息,这部分信息表示为丰富的语义属性知识(例如,“喙色为黄色”、“腿色为红色”)。因此,ZSL的关键挑战是如何在可见类别上推断视觉和属性特征之间的潜在语义知识,从而实现向不可见类别的理想知识转移。最近,一些基于注意力的ZSL方法[5,25,46-48,54]利用属性描述作为指导来发现区分部分/细粒度特征,从而能够更准确地匹配语义表示。不幸的是,他们只是简单地利用单向注意力,只关注视觉和属性特征之间有限的语义对齐,而没有进行任何进一步的序列学习。因此,适当发现视觉和属性特征之间内在且更充分的语义表示(例如属性语义)对于ZSL的知识转移具有重要意义。
基于以上观察,我们提出了一种用于ZSL的互语义蒸馏网络(MSDN),如图2(d)所示,以探索视觉和属性特征之间的内在语义知识。MSDN包括一个属性→视觉注意力子网,它学习基于属性的视觉特征,和一个视觉→属性注意力子网,它学习基于视觉的属性特征。这两个相互注意力子网充当教师-学生网络,在整个训练过程中相互指导并相互学习。因此,MSDN可以探索最匹配的基于属性的视觉特征和基于视觉的属性特征,从而能够有效地提取内在语义表示,实现从可见到不可见类别的理想知识转移(图1)。具体来说,每个注意力子网都是用基于属性的交叉熵损失进行训练的[5,14,25,48,54]。为了鼓励属性→视觉注意力子网和视觉→属性注意力子网之间的相互学习,我们进一步引入了一个语义蒸馏损失,该损失对齐彼此的类后验概率。定量和定性的结果充分证明了MSDN的优势和巨大潜力。
我们的贡献总结如下:
我们提出了一个与现有ZSL方法不同的互语义蒸馏网络(MSDN),它提取了内在的语义表示,从而实现了从可见到不可见类别的有效知识转移,对于ZSL非常重要。
我们引入了一个语义蒸馏损失,使MSDN中的属性→视觉注意力子网和视觉→属性注意力子网能够相互学习。通过蒸馏内在语义知识,鼓励它们学习基于属性的视觉特征和基于视觉的属性特征,以实现语义嵌入表示。
我们进行了广泛的实验,证明我们的MSDN在三个基准数据集上取得了显著的性能提升,即CUB[42],SUN[30]和AWA2[44]。
2.Related Work
2.2.Knowledge Distillation
为了将来自大型教师网络的知识压缩到小型学生网络,提出了知识蒸馏[13]。最近,知识蒸馏被扩展到从强大的教师网络开始优化小型深度网络[29,33]。通过模仿教师的类概率和/或特征表示,蒸馏模型传达了超出常规监督学习目标的其他信息[52,53]。在这些动机的驱使下,我们设计了一个相互语义蒸馏网络,通过语义蒸馏内在知识来学习内在语义。相互语义蒸馏网络由属性→视觉注意力和视觉→属性注意力子网络组成,它们作为一个师生网络来协同学习和相互教学。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!