论文阅读:Lidar Annotation Is All You Need
目录
概要
? ? 论文重点在探讨利用点云的地面分割任务作为标注,直接训练Camera的精细2D分割。在以往的地面分割任务中,利用Lidar来做地面分割是目前采用激光雷达方案进行自动驾驶的常见手段。来自Evocargo LCC的学者认为在2D上直接做分割的标注(尤其是高精度的分割标注)是比较耗时耗力的,这会带来很多额外的成本,不利于大规模自动驾驶量产。作者提出使用3D的地面粗分割结果(例如patchwork++这种无需训练的模型)作为reference。解决了激光雷达点云的稀疏地面实况蒙版的问题。该方法的实验证明,在减轻注释负担的同时,能够保持与高质量图像分割模型相媲美的性能。
? ? 论文方法的关键创新是masked损失,其解决了激光雷达点云中稀疏的真值masks。
? ??论文的贡献总结如下:
- 提出了一种新型的灵活且有效的图像分割方法,使用卷积神经网络和投影的激光雷达点云数据作为真值;
- 在若干数据集上评估了所提出的方法,将其与使用标准2D真值训练的模型进行比较,并且考虑了本文方法的细节,包括混合能力以及传感器设置的差异。
Motivation
- 虽然激光雷达数据提供准确的深度信息,但它们无法精确分割场景内的对象;
- 激光雷达测量在某些情况下的精度有限;例如,当处理透明或反射表面时,反射的激光脉冲可能会被扭曲或吸收。
- 减少了标注的负担,并且能够在不损失分割质量的情况下训练图像分割模型。
整体架构流程
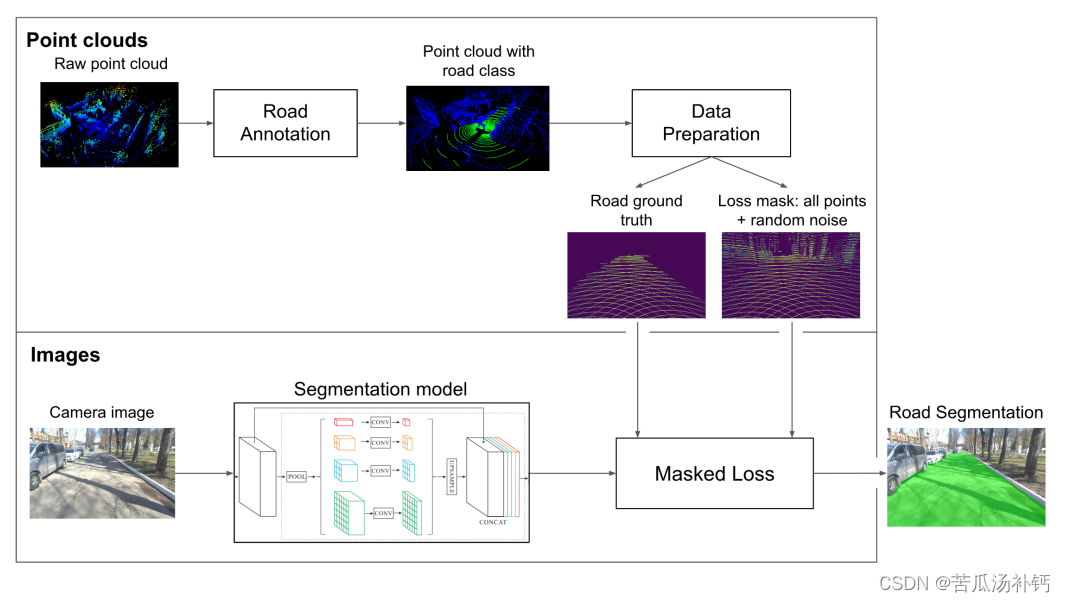
? ? 方法的整体流程如上图所示。它由四个主要部分组成:点云道路注释、数据准备、掩模损失和分割模型本身。首先,我们获取点云域中带有道路注释的数据。之后,我们使用齐次变换和相机参数来投影点。然后,使用投影点,获得道路地面实况和掩模,用于添加随机噪声的损失计算。来自相机的图像由分割模型处理。Masked 损失利用上一步的预测和掩码,从而允许使用稀疏的地面实况数据来训练模型。最后,经过模型训练,得到了具有分段道路的图像。训练过程以及Masked损失允许将投影的地面实况与传统的 2D掩模混合,这使得该方法在数据方面具有灵活性。??
技术细节
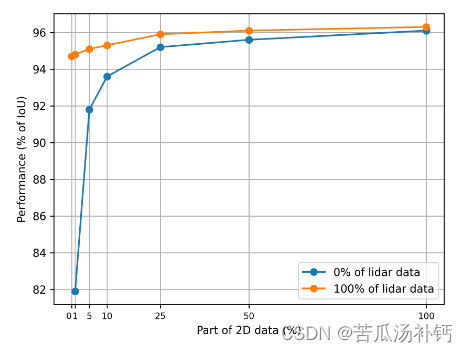
"Waymo full"数据集验证分割的道路分割结果(IoU 的百分比),该数据集针对在不同比率的 2D图像掩模和基于激光雷达的地面实况上训练的模型。

Waymo 开放数据集上三种模型的预测比较。从上到下:仅 2D、仅投影 3D、混合 2D + 投影 3D
? ? 可以在训练过程中将数据集中的 2D 图像掩模与 3D 点云掩模结合起来。这种多功能性非常有价值,特别是当 3D 激光雷达点和图像的手动注释可能不切实际时(当数据集非常大时)。该方法使用两个公共数据集(Waymo 开放数据集和 KITTI-360)和一个专有数据集进行了测试,结果令人鼓舞。仅在投影激光雷达点掩模上训练的模型的性能略逊于二维掩模训练的模型,但前者的质量仍然很高,并且与后者的质量相当。在 2D 掩模和激光雷达投影组合上训练的模型的性能指标与传统的 2D 掩模模型相匹配甚至超过了传统的 2D 掩模模型,强调了这种混合方法的潜力。混合实验表明,可以将训练所需的图像量减少 50%,并在不损失预测质量的情况下增加投影3D 数据量。
小结
? ? 在文中介绍了一种新的道路表面分割方法,其利用了标注的激光雷达点云和传统的2D图像掩膜。通过本文流程(包括点云道路标注、真值数据准备、分割神经网络和专门设计的masked损失函数),作者展示了激光雷达获得的道路masks如何使神经网络在图像分割任务中表现更好。论文方法使用较少的资源来标注来自不同类型传感器的数据。
? ? 该方法的一个显著优势是其灵活性,它能够在训练过程中将数据集中的2D图像掩膜和3D点云掩膜相结合。这种多功能性非常有价值,尤其在3D激光雷达点云和图像的手动标注可能不切实际的情况下(当数据集非常大时)。该方法使用两个公开数据集(Waymo Open Dataset和KITTI-360)和一个专有数据集进行测试,结果非常良好。仅在投影的激光雷达点云掩膜上训练的模型的性能略低于2D掩膜训练的模型,但是前者的质量仍然很高,与后者的质量相当。在2D掩膜和激光雷达投影的组合上训练的模型的性能指标与传统的2D掩膜模型相当甚至超过2D掩膜模型,从而突出了这种混合方法的潜力。混合实验表明,可以将训练所需的图像数量减少50%,并且在不损失预测质量的情况下增加投影的3D数据数量。
? ? 在Waymo和KITTI-360数据集上的分析结果表明,激光雷达的特性(例如图像上的点分布、距离和频率)会影响分割结果。这种可变性表明,尽管基于激光雷达的标注很重要,但是也应该考虑每个数据集的独特属性,包括硬件细节和环境变量。
? ? 未来的研究可以使用不同的方法。增强投影的激光雷达点云的规模可能会提高覆盖范围,但是会损失一些精度。今后也能够扩展数据融合技术,利用车辆周围的多相机视角并且探索各种激光雷达设置。理解不同激光雷达之间的细微差别是至关重要的,并且需要在各种条件下(冬天和夜间场景等)测试本文方法。最后,需要额外研究将投影的激光雷达点作为输入的新型神经架构,可能会优化2D图像标注和3D激光雷达数据的组合,以增强分割。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024 通义语音 AI 技术图景,大模型引领 AI 再进化
- Shell编程--正则表达式(基本/拓展元字符、正则判断)
- 数据库系统原理例题之——数据库安全与保护
- 如何本地搭建DolphinScheduler并无公网ip远程访问管理界面
- Nginx rewrite 参数
- MySQL-事务
- 红队攻防实战之DOUBLETROUBLE
- C#上位机基本通信过程
- c# OpenCvSharp透视矫正参数调整器
- C++和Java中的随机函数你玩明白了吗?内附LeetCode470.rand7()爆改rand10()巨详细题解,带你打败LeetCode%99选手