Vision Transformer(VIT)模型介绍
计算机视觉
文章目录
Vision Transformer(VIT)
Vision Transformer(ViT)是一种新兴的图像分类模型,它使用了类似于自然语言处理中的Transformer的结构来处理图像。这种方法通过将输入图像分解成一组图像块,并将这些块变换为一组向量来处理图像。然后,这些向量被输入到Transformer编码器中,以便对它们进行进一步的处理。ViT在许多计算机视觉任务中取得了与传统卷积神经网络相当的性能,但其在处理大尺寸图像和长序列数据方面具有优势。与自然语言处理(NLP)中的Transformer模型类似,ViT模型也可以通过预训练来学习图像的通用特征表示。在预训练过程中,ViT模型通常使用自监督任务,如图像补全、颜色化、旋转预测等,以无需人工标注的方式对图像进行训练。这些任务可以帮助ViT模型学习到更具有判别性和泛化能力的特征表示,并为下游的计算机视觉任务提供更好的初始化权重。
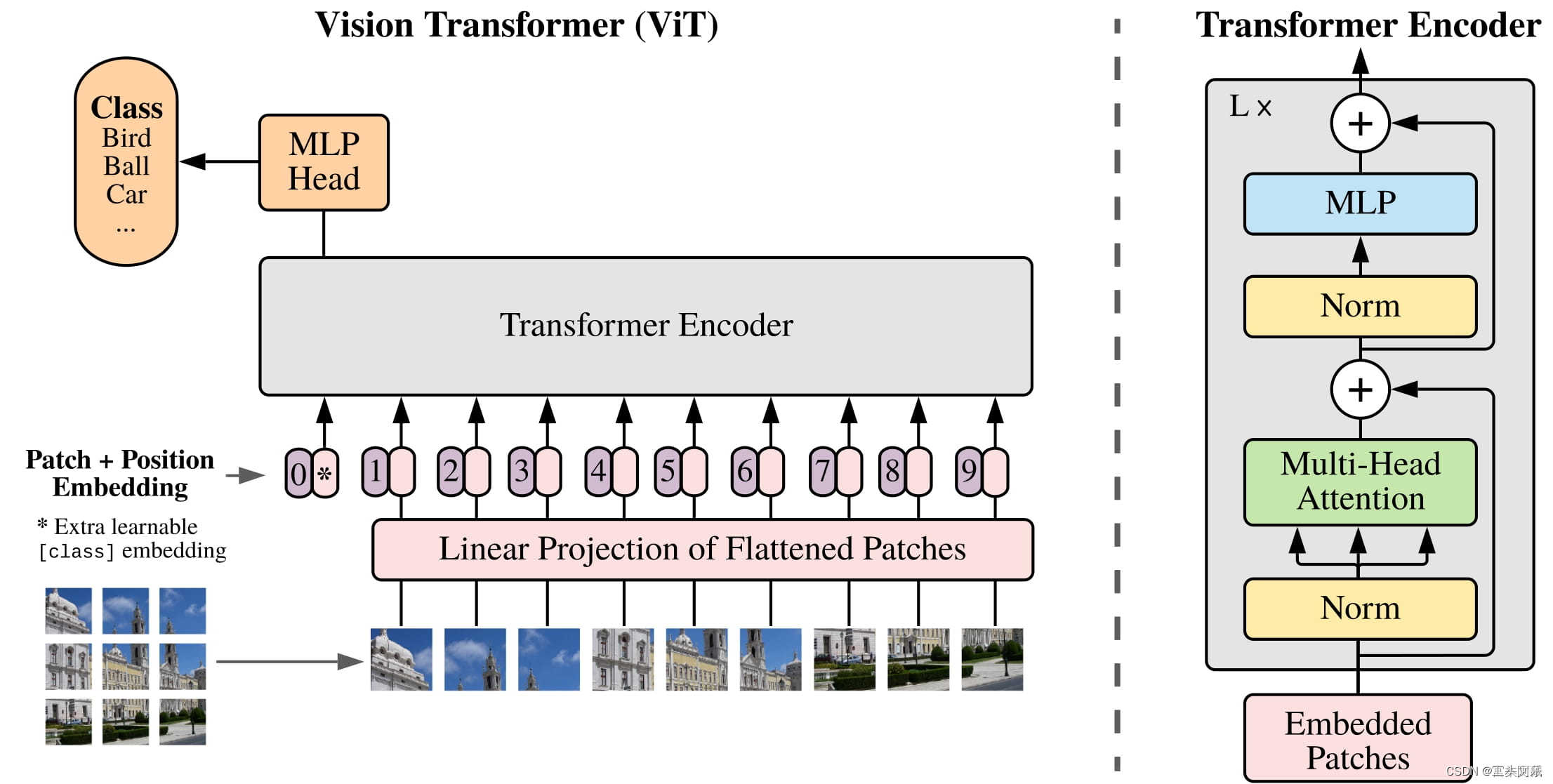
Patch Embeddings
Patch embedding是Vision Transformer(ViT)模型中的一个重要组成部分,它将输入图像的块转换为向量,以便输入到Transformer编码器中进行处理。
Patch embedding的过程通常由以下几个步骤组成:
图像切片:输入图像首先被切成大小相同的小块,通常是16x16、32x32或64x64像素大小。这些块可以重叠或不重叠,取决于具体的实现方式。
展平像素:每个小块内的像素被展平成一个向量,以便能够用于后续的矩阵计算。展平的像素向量的长度通常是固定的,与ViT的超参数有关。
投影:接下来,每个像素向量通过一个可学习的线性变换(通常是一个全连接层)进行投影,以便将其嵌入到一个低维的向量空间中。
拼接:最后,所有投影向量被沿着一个维度拼接在一起,形成一个大的二维张量。这个张量可以被看作是输入序列的一个矩阵表示,其中每一行表示一个图像块的嵌入向量。
通过这些步骤,Patch embedding将输入的图像块转换为一组嵌入向量,这些向量可以被输入到Transformer编码器中进行进一步的处理。Patch embedding的设计使得ViT能够将输入图像的局部特征信息编码成全局特征,从而实现了对图像的整体理解和分类。

Inductive bias
在Vision Transformer(ViT)模型中,也存在着Inductive bias,它指的是ViT模型的设计中所假定的先验知识和偏见,这些知识和偏见可以帮助模型更好地学习和理解输入图像。
ViT的Inductive bias主要包括以下几个方面:
图像切片:ViT将输入图像划分为多个大小相同的块,每个块都是一个向量。这种切片方式的假设是,输入图像中的相邻区域之间存在着相关性,块内像素的信息可以被整合到一个向量中。
线性投影:在Patch embedding阶段,ViT将每个块的像素向量通过线性投影映射到一个较低维度的向量空间中。这种映射方式的假设是,输入图像的特征可以被表示为低维空间中的点,这些点之间的距离可以捕捉到图像的局部和全局结构。
Transformer编码器:ViT的编码器部分采用了Transformer结构,这种结构能够对序列中的不同位置之间的依赖关系进行建模。这种建模方式的假设是,输入图像块之间存在着依赖关系,这些依赖关系可以被利用来提高模型的性能。
通过这些Inductive bias,ViT模型能够对输入图像进行有效的表示和学习。这些假设和先验知识虽然有一定的局限性,但它们可以帮助ViT更好地处理图像数据,并在各种计算机视觉任务中表现出色。
Hybrid Architecture
在ViT中,Hybrid Architecture是指将卷积神经网络(CNN)和Transformer结合起来,用于处理图像数据。Hybrid Architecture使用一个小的CNN作为特征提取器,将图像数据转换为一组特征向量,然后将这些特征向量输入Transformer中进行处理。
CNN通常用于处理图像数据,因为它们可以很好地捕捉图像中的局部和平移不变性特征。但是,CNN对于图像中的全局特征处理却有一定的局限性。而Transformer可以很好地处理序列数据,包括文本数据中的全局依赖关系。因此,将CNN和Transformer结合起来可以克服各自的局限性,同时获得更好的图像特征表示和处理能力。
在Hybrid Architecture中,CNN通常被用来提取局部特征,例如边缘、纹理等,而Transformer则用来处理全局特征,例如物体的位置、大小等。具体来说,Hybrid Architecture中的CNN通常只包括几层卷积层,以提取一组局部特征向量。然后,这些特征向量被传递到Transformer中,以捕捉它们之间的全局依赖关系,并输出最终的分类或回归结果。
相对于仅使用Transformer或CNN来处理图像数据,Hybrid Architecture在一些图像任务中可以取得更好的结果,例如图像分类、物体检测等。
Fine-tuning and higher resolution
在ViT模型中,我们通常使用一个较小的分辨率的输入图像(例如224x224),并在预训练阶段将其分成多个固定大小的图像块进行处理。然而,当我们将ViT模型应用于实际任务时,我们通常需要处理更高分辨率的图像,例如512x512或1024x1024。
为了适应更高分辨率的图像,我们可以使用两种方法之一或两种方法的组合来提高ViT模型的性能:
Fine-tuning: 我们可以使用预训练的ViT模型来初始化网络权重,然后在目标任务的数据集上进行微调。这将使模型能够在目标任务中进行特定的调整和优化,并提高其性能。
Higher resolution: 我们可以增加输入图像的分辨率来提高模型的性能。通过处理更高分辨率的图像,模型可以更好地捕捉细节信息和更全面的视觉上下文信息,从而提高模型的准确性和泛化能力。
通过Fine-tuning和Higher resolution这两种方法的组合,我们可以有效地提高ViT模型在计算机视觉任务中的表现。这种方法已经在许多任务中取得了良好的结果,如图像分类、目标检测和语义分割等。
PyTorch实现Vision Transformer
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, datasets
# 定义ViT模型
class ViT(nn.Module):
def __init__(self, image_size=224, patch_size=16, num_classes=1000, dim=768, depth=12, heads=12, mlp_dim=3072):
super(ViT, self).__init__()
# 输入图像分块
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) ** 2
self.patch_dim = 3 * patch_size ** 2
self.proj = nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size)
# Transformer Encoder
self.transformer_encoder = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=dim, nhead=heads, dim_feedforward=mlp_dim), num_layers=depth)
# MLP head
self.layer_norm = nn.LayerNorm(dim)
self.fc = nn.Linear(dim, num_classes)
def forward(self, x):
# 输入图像分块
x = self.proj(x)
x = x.flatten(2).transpose(1, 2)
# Transformer Encoder
x = self.transformer_encoder(x)
# MLP head
x = self.layer_norm(x.mean(1))
x = self.fc(x)
return x
# 加载CIFAR-10数据集
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=False)
# 实例化ViT模型
model = ViT()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 训练模型
num_epochs = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(num_epochs):
# 训练模式
model.train()
train_loss = 0.0
train_acc = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计训练损失和准确率
train_loss += loss.item() * images.size(0)
_, preds = torch.max(outputs, 1)
train_acc += torch.sum(preds == labels.data)
train_loss = train_loss / len(train_loader.dataset)
train_acc = train_acc
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!