计算机体系结构----存储系统
本文严禁转载,仅供学习使用。参考资料来自中国科学院大学计算机体系结构课程PPT以及《Digital Design and Computer Architecture》、《超标量处理器设计》、同济大学张晨曦教授资料。如有侵权,联系本人修改。
1.1 引言
1.1.1虚拟和物理内存
- 程序员看到虚拟内存 (虚拟内存),可以假设内存是“无限的”
- 现实:物理内存 (物理内存) 大小比程序员假设的要小得多
- 系统(系统软件+硬件,协同)将虚拟内存地址映射到物理内存,即地址转换 (虚实映射)
- 系统自动管理物理内存空间,对程序员透明 + 程序员不需要知道内存的物理大小,也不需要管理 优点:小物理内存对程序员来说可能是一个巨大的内存,使得程序员的生活更轻松
缺点:更复杂的系统软件和架构
本文后面讲到虚拟地址的时候会谈到上面的虚实映射到底是啥。
1.1.2存储数据的方法
- 触发器、锁存器:非常快,并行访问,非常昂贵
- SRAM:相对比较快,一次只能访问一组数据,昂贵
- DRAM:更慢,一次只能访问一个数据,读会毁坏内容,需要特别的工艺,但是便宜
- 其他存储技术如Flash、硬盘等:更慢,访问时间长,但是非易失,非常便宜
关于DRAM和SRAM的具体结构和访问模式属于计算机组成原理的范畴,可以自行查资料,这里不再赘述。
1.1.3 交替访问Interleaving存储器的bank层次
- 问题:单个单片大内存阵列需要很长时间才能访问,并且不支持并行访问多个访问
- 目标:减少内存阵列访问的延迟,并启用多个并行访问
- 思路:将一个大数组划分为多个可以独立访问的bank(在同一周期或连续周期中)
– 每个存储区都小于整个内存存储
– 对不同bank的访问可以重叠访问
– 访问延迟是可控的 - 一个关键问题:如何将数据映射到不同的bank?(即,如何跨bank交错访问数据?)
交错访问的示例
- 内存被划分为可以独立访问的banks; banks 共享地址和数据总线(以减少存储芯片引脚)
- 每个周期可以启动并完成一次 bank 访问
- 如果每个时钟周期都转到不同的bank进行访问请求,则可以维持 N 个并发访问(注:相当于一个流水线)
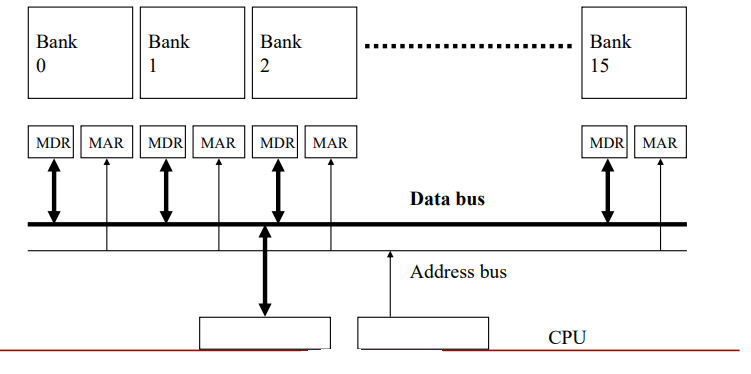
上图表示交替访问的示例,每个时钟周期地址总线对一个bank发送地址,经过一个bank的延时(latency)之后,数据总线便会每个时钟周期出一个数据,这些数据来自递增再循环的bank序列。
1.2 存储器的抽象层次
1.2.1 广义存储器结构
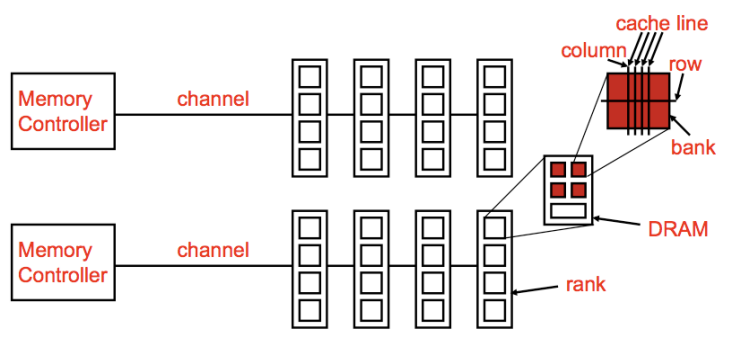

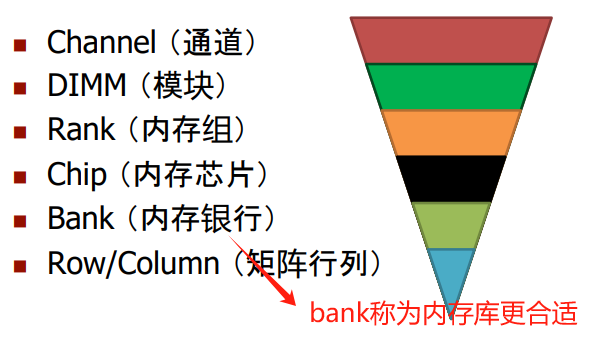
1.2.2 DRAM 子系统组织结构
Channel
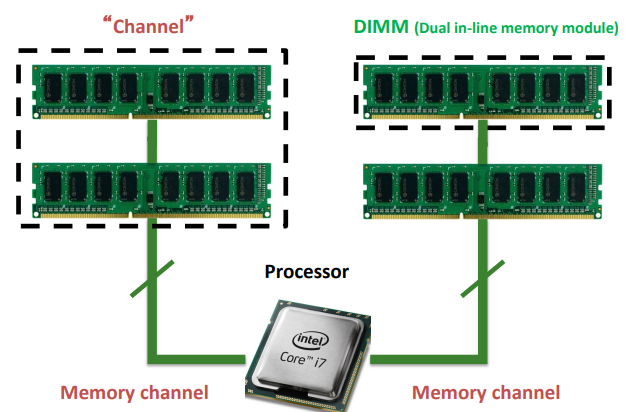
channel 可以理解成插槽。
DIMM
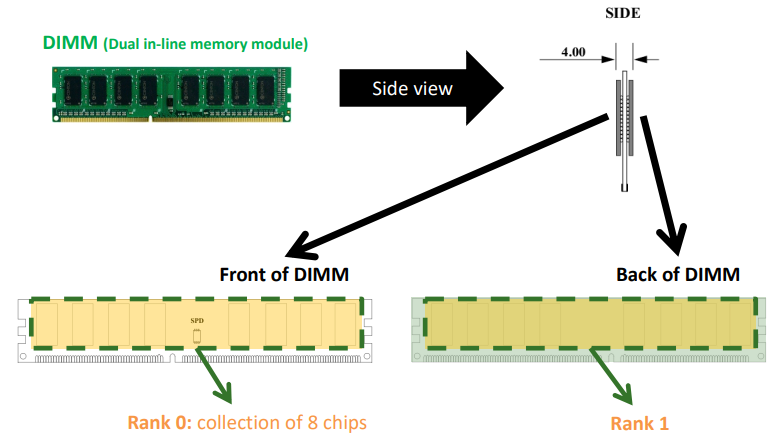
DIMM可以理解成我们常用的内存条。
Rank
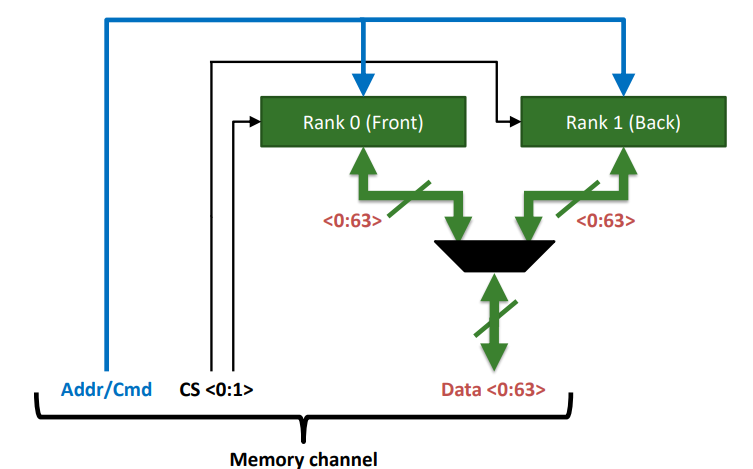
Rank就是内存条的正面或反面
Chip
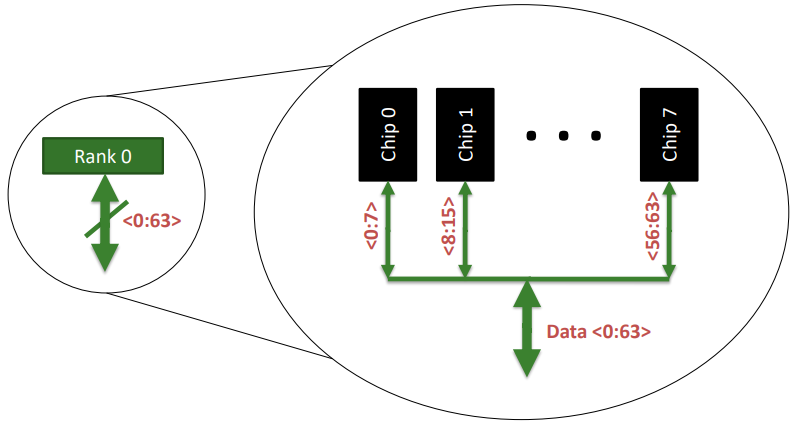
每个Rank都由多个chip组成,chip个数受单个chip位宽和系统位数决定,本文最后的作业题会体现这一点。
Banks
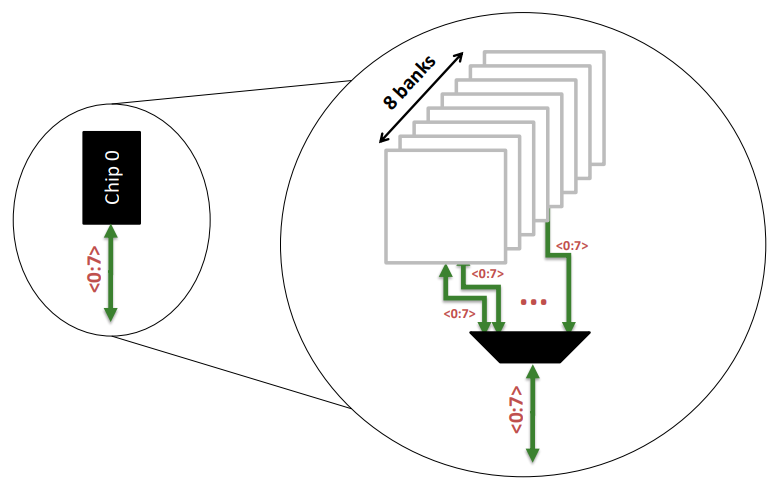
Breaking down a Bank
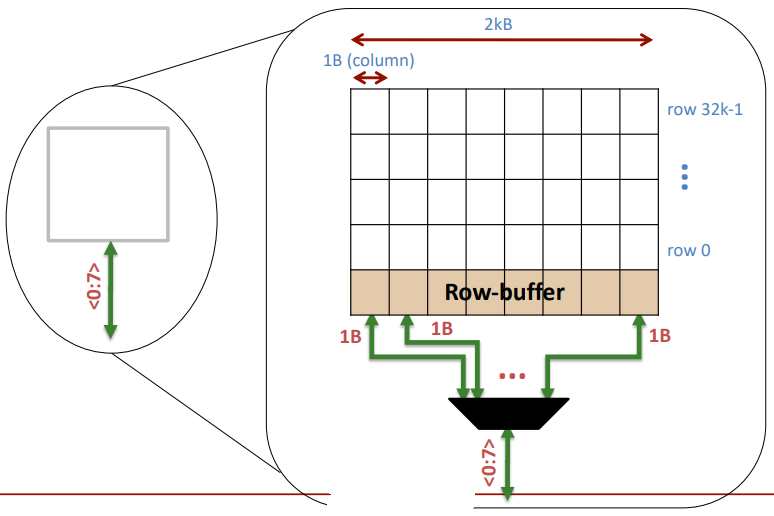
注意,从bank里面出来的<0:7>表示八个bit,也即是1个字节,一个时间周期就吐出来了。
至于bank的组成原理,可以参考本篇文章的解释
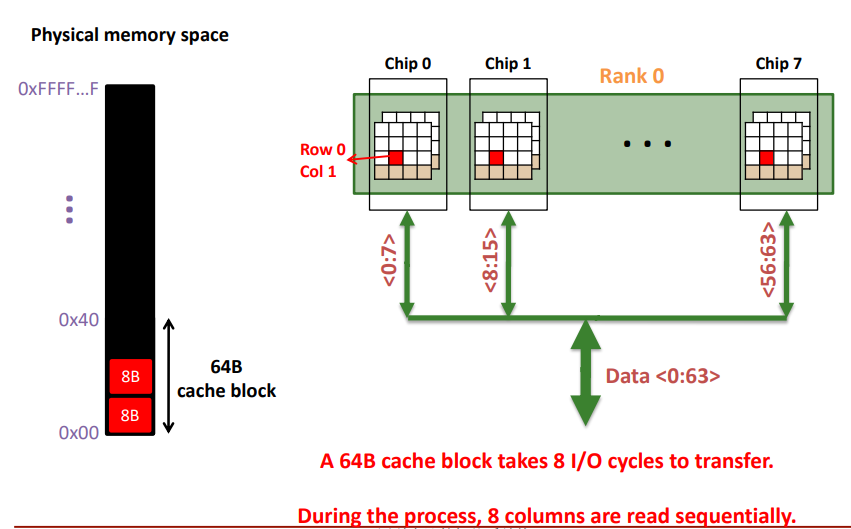
1.2.2 数据从存储器到缓存
如果我们想从主存中调用一个64B的数据到缓存,数据自表向内具体吐出的细节如下(了解细节时需要参考本文1.1.1节的抽象层次解构图):
- 每个时钟周期一个rank吐出64bits数据
- 每个时钟周期每个chip贡献8bits的数据,8个chips贡献64bits数据
- 每个chip由N个banks组成,每个时钟周期N个banks中的一个bank贡献8bits数据,其他N-1个banks不贡献数据,整个chip输出8bits数据
经过上述1~3步骤,一个时钟周期吐出64bits数据,总共要填满64B的缓存块,需要8个时钟周期。
另外需要强调的是,理论上第0个时钟周期给bank送入地址,是不能在第1个时钟周期得到这个bank的数据的,那为什么我们这里认为每个时钟周期每个chip都能吐出8bits的数据呢?是因为我们把需要的数据交替存储在chip中的bank里面,进行流水式的访问chip。
1.3 高速缓存
研究目标:
- 高速缓存中存放哪些数据。
- 如何在高速缓存中寻找数据。
- 当高速缓存满时,如何替换旧数据来放置新数据。
约定几个刻画高速缓存的术语。
容量(C)、组数(S)、块大小(b)、块数(B)和相关联度(N)。
同时我们不区分数据缓存和指令缓存。
1.3.1 高速缓存中存放的数据
利用时间局部性和空间局部性来猜测处理器未来需要的数据。
时间局部性意味着,如果处理器最近访问过一块数据,那么它可能很快再次访问这块数据。因此,当处理器装入和存储不在高速缓存中的数据时,需要将数据从主存复制到高速缓存中。随后对此数据的请求将在高速缓存内命中。
空间局部性意味着,当处理器访问一块数据时,它很可能也访问此存储位置附近的数据。因此,当高速缓存从内存中提取一个字时,它也可以提取多个相邻的字。这样的一组字称为高速缓存块(cache block)或高速缓存行(cache line)。一个高速缓存块中的字数称为块大小(b)。容量为C的高速缓存包含了B=C/b块。
1.3.2 高速缓存中的数据查找
一个高速缓存可以组织成S个组,其中每一组有一个或者多个数据块。主存中数据的地址和高速缓存中数据的位置之间的关系称为映射(mapping)。每一个内存地址都可以准确地映射到高速缓存中的一组。某些地址位用于确定哪个高速缓存组包含数据。如果一组包含多块,那么数据可能包含在该组中的任何一块内。
高速缓存按照组中块的数进行分类。**在直接映(direct mapped)高速缓存内,每一组只包含一块,所以高速缓存包含了S=B 组。因此,一个特定主存地址映射到高速缓存的唯一块在N路组相联(N-way associative)高速缓存中,每一组包含N块。地址依然映射到唯一的组其中共有S=B/N组。**但是这个地址对应的数据可以映射到组中的任何块。全相联(full associative)高速缓存只有唯一一个组(S=1)。数据可以映射到组内B块中的任何一块。因此,全相联高速缓存也是B路组相联高速缓存的别名。
为了说明高速缓存的组织方式,我们将考虑32位地址和32位字的MIPS存储器系统。内存按字节寻址,每个字有4字节,所以内存包含 2 3 0 2^30 230个字,并按照字方式对齐。为了简化,我们首先分析容量C为8个字,块大小6为1个字的高速缓存,然后推广到更大的块。
1. 直接映射高速缓存
直接映射高速缓存的每组内有一块,所以其组数S等于块数 B。为了理解内存地址如何映射到高速缓存块,想象内存就像高速缓存那样映射到多个b字大小的块。主存中第0块的地址映射到高速缓存的第0组。主存中第1块的地址映射到高速缓存的第1组,这样一直到内存中第B-1块的地址映射到高速缓存的第B-1组。此时高速缓存没有更多的块了,所以就开始循环,内存的第B块映射到高速缓存的第0组。
图8-5中用容量为8个字,块大小为1个字的直接映射高速缓存说明了这个映射。高速缓存有8组,每组有1块。因为地址是字对齐的,所以地址的最低两位总是为00。紧接着的
log
?
2
8
=
3
\log_{2}8=3
log2?8=3位说明存储器地址映射到哪一组。因此,地址0x00000004,0x00000024,0xFFFFFFE4 的数据全部映射到第1组,以灰色标注。类似地,地址0x00000010,0xFFFFFFF0 的数据全部映射到第4组,以此类推。每一个主存地址都可以映射到高速缓存中的唯一组。
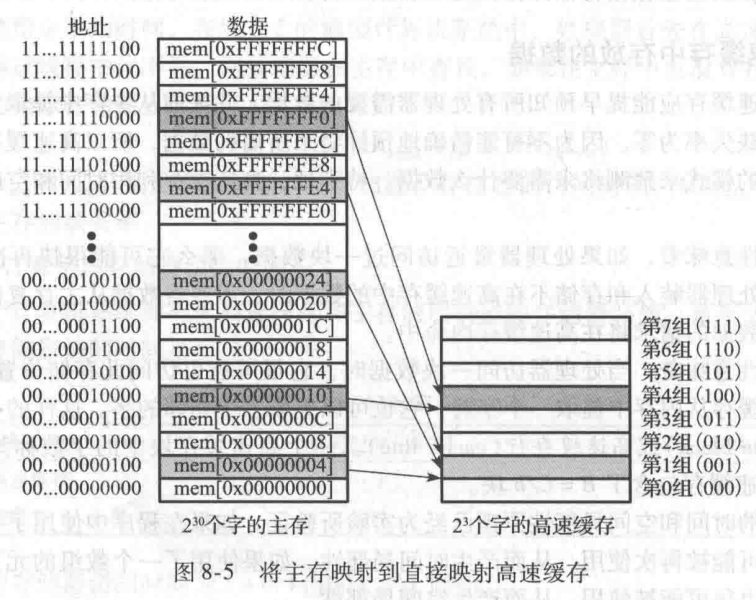
因为很多地址都映射到同一组上,所以高速缓存还必须保存实际包含在每一组内数据的地址。地址的最低有效位说明哪组包含该数据。剩下的高位称为标志(tag),说明包含在组内的数据是多个可能地址中的哪一个。
在我们先前的例子中,32位地址的最低两位称为字节偏移量(byte offset),它说明字节在字中的位置。紧接着的3 位称为组位(set bit),说明地址映射到哪一组(一般来说,组位的位数为 logS \text{logS} logS)。剩下的27位标志位说明存储在特定高速缓存组中数据的存储器地址。图8-6 给出了地址0xFFFFFFF4 的高速缓存字段。它映射到第一组,且所有标志都为1。

问题1:对于图8-5,地址0x00000014 的字映射到哪一个高速缓存组?
0x00000014写成图8.6的组合形式为,0x000…01010, 所以组号为101,字节偏移量为00,因此映射到了高速缓存的第五组(缓存的八个组从0~7)。总结:以后碰到这种问地址属于哪一组的题目,先把地址写成二进制的形式,然后观察下哪些bit位表示组号。
问题2:为具有 1024(
2
10
2^{10}
210)组和块大小为1个字的直接映射高速缓存确定组数和标志位数。其中地址长度为32位。
的32-10-2=20位作为标志
解:一个有
2
10
2^{10}
210组的高速缓存的组位为
log
?
2
2
10
=
10
\log_{2}2^{10}=10
log2?210=10。地址中的最低两位为字节偏移量,剩下
32
?
10
?
2
=
20
32-10-2=20
32?10?2=20位作为标志。
有时(例如计算机刚启动时),高速缓存组没有包含任何数据。高速缓存的每一组都有一个有效位(valid bit),它说明此组是否包含有意义的数据。如果有效位为0,那么其内容就没有意义。图8-7是图8-5中直接映射高速缓存的硬件结构。高速缓存由8表项(entry)SRAM组成。每个表项(或组)包含一个32位数据缓存行、27 位标志和1位有效位。高速缓存使用32位地址访。最低两位(字节偏移位)因为字对齐而省略,紧接着的3 位(组位)指明高速缓存中的表项或组。装入指令从高速缓存中读出特定的表项,检查标志和有效位。如果标志与地址中的最高 27 位相同,而且有效位为1,则高速缓存命中,数据将返回到处理器。否则,高速缓存发生缺失存储器系统必须从主存中取出数据。
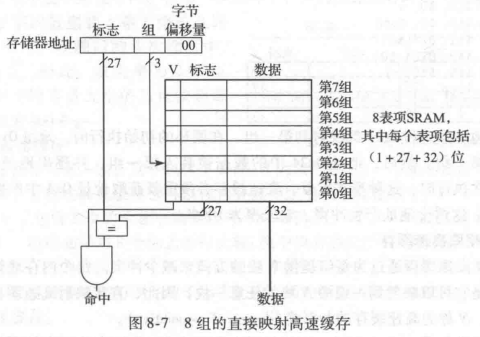
问题3:直接映射高速缓存的时间局部性。在应用中,循环是时间和空间局部性的常见来源。使用图 8-7 中的8 表项高速缓存,给出在执行以下MIPS汇编代码循环后高速缓存中的内容。假设高速缓存的初始状态为空。缺失率为多少?

解:这个程序包含一个重复5次的循环。每一次循环涉及3 次的内存访问(Load操作),最后总计产生15 次内存访问。在第一次循环执行的时候,高速缓存为空。必须分别从主存的0x4、0xC、0x8 中获取数据,存放到高速缓存的第1组、第3组和第2组。然后,在以后4 次的循环执行中,在高速缓存中没有找到数据。图8-8显示了在为最后对内存地址0x4请求时高速缓存内容。因为地址的高27位为0,所以标志全为0。缺失率为3/15=20%。

当两个最近访问的不同地址映射到同一个高速缓存块时,就会产生冲突(conflict),并且最近访问的地址从块中逐出较前面的地址。直接映射高速缓存每组只有1块,所以两个映射到同一组的地址常常会产生冲突。问题4说明冲突。
问题4:高速缓存块冲突。当在图8-7中的8字直接映射高速缓存中执行以下循环时,缺失率是多少?假设高速缓存初始为空。

解:内存地址0x4和0x24都映射到第一组。在循环的初始执行时,地址0x4 中的数据被装人高速缓存的第一组。然后,地址0x24 中的数据被装入第一组,并逐出地址0x4 中的数据在循环的第二次执行时,这种模式重复,高速缓存必须重新获取地址0x4 中的数据,逐出地址0x24中的数据。这两个地址产生冲突,缺失率为 100%。
2. 多路组相联高速缓存
N路组相联高速缓存通过为每组提供N块的方式来减少冲突。每个内存地址依然映射到唯一的组中,但是它可以映射到一组中 N块的任意一块。因此,直接映射高速缓存也称为单路组相联高速缓存。N称为高速缓存的相联度(degree of associative)。
图8-9给出了容量C为8个字,相联度N为2的2路组相联高速缓存的硬件。高速缓存现在只有4组,而不是直接映射高速缓存的8 组。因此,只需要 log ? 2 4 = 2 \log_24=2 log2?4=2个组位来选择组,而不是直接映射高速缓存的3。标志从27 位增加到28 位。每组包括2路(相联度为2)。每路由数据块、有效位和标志位组成。高速缓存从选定的组中读取所有2 路中的块,检查标志和有效位来确定是否命中。如果其中一路命中,复用器就从此路选择数据。
与相同容量的直接映射高速缓存相比,组相联高速缓存的缺失率一般比较低,因为它们的冲突更少。然而,因为增加了输出复用器和额外的比较器,所以组相联高速缓存常常比较慢成本也比较高。它们还会产生另一个问题:当2路都满时,选择哪一路替换?这个问题将在后面讨论。大部分的商业系统都使用组相联高速缓存。
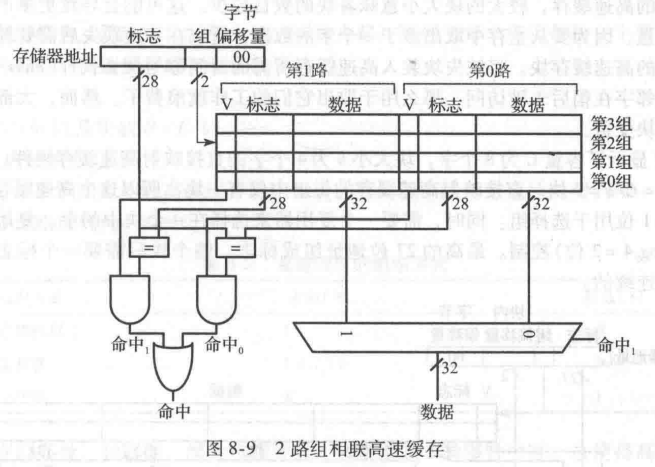
问题5:组相联高速缓存的缺失率。当在图8-7中的8字直接映射高速缓存中执行以下循环时,缺失率是多少?假设高速缓存初始为空。
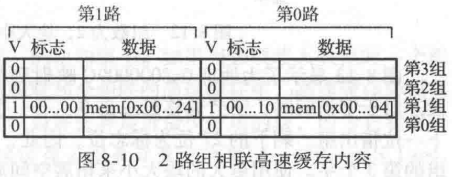
解:两个对地址0x4和0x24 的存储器访问都映射到第一组。然而,高速缓存有2路,所以它能同时为两个地址提供数据空间。在第一次循环中,空的高速缓存对两个地址访问都产生缺失,然后将两个字的数据装入第1组的2路中,如图8-10所示。在随后的4次循环中高速缓存都命中。因此,缺失率为2/10=20%。
3. 全相联高速缓存
全相联高速缓存只有一组,其中包含了 B路(B 为块的数目)。存储器地址可以映射到这些路中的任何一块。全相联高速缓存也可以称为B路单组组相联高速缓存。
图8-11 显示了包含8块的全相联高速缓存SRAM 阵列。对于一个数据请求,由于数据可能在任何一块中,所以必须对8 个标志进行比较(图中没有表示出)。类似地,如果命中,则使用8:1复用器选择合适的数据。对于给定的高速缓存相同容量下,全相联高速缓存一般具有最小的冲突缺失,但是需要更多的硬件用于标志比较。因为需要大量的比较器,所以它们仅仅适合于较小的高速缓存。

4. 块大小
前面的例子能够利用时间局部性,因为调用过的数据被存放在缓存中,而不用再从内存中慢速地获取,但是上面介绍的缓存中只存储了一个字。为了利用空间局部性,高速缓存使用更大的块来保存多个连续的字。
块大小大于1个字的优势在于,在发生缺失和取出字放人高速缓存中时,在块中相邻的字也会取出放人高速缓存中。因此,因为空间局部性,所以后续的访问就很可能命中。然而,对于固定大小的高速缓存,较大的块大小意味着块的数目较少。这可能会导致更多的冲突,增加缺失率。而且,因为要从主存中取出多于一个字的数据,所以在一次缺失后需要耗费更多时间来取出缺失的高速缓存块。将缺失块装入高速缓存所需的时间称为缺失代价(miss penalty)。如果块中的相邻字在稍后未被访问,那么用于取出它们的工作就浪费了。然而,大部分实际程序都从较大的块受益。
图8-12显示了容量C为8个字,块大小b为4个字的直接映射高速缓存硬件。此时,高速缓存只有 B=C/b=2块。直接映射高速缓存的每组中仅有一块,所以这个高速缓存有两组,只需要 l o g 2 2 = 1 \mathrm{log}_22=1 log2?2=1位用于选择组。同时,需要一个复用器来选择在一个块中的字。复用器由地址的块偏移位( l o g 2 4 = 2 \mathrm{log}_24=2 log2?4=2位)控制。最高的27位地址组成标。整个块只需要一个标志,因为块内字的地址是连续的。
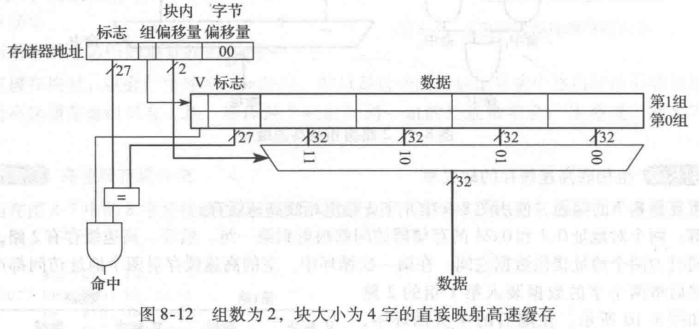
图8-13显示了为地址0x8000009C 映射到图8-12中的直接映射高速缓存时的高速缓存字段。对于字访问时,字节偏移量总是0。下一个
log
?
2
b
=
2
\log_2b=2
log2?b=2的块偏移位指明此字在块中的位置下一位指出组。剩下的27 位为标志位。因此,地址为0x8000009C 的字映射到高速缓存中第1组的第3个字。使用更大的块大小来拓展空间局部性的原理也可应用于相联高速缓存。

问题6:直接映射高速缓存的空间局部性。用容量为8个字、块大小为4个字的直接映射高速缓存,给出在执行以下MIPS汇编代码循环后高速缓存中的内容。假设高速缓存的初始状态为空。缺失率为多少?
解:图8-14显示了第一次存储器访问后高速缓存的内容。在第一次循环迭代时,高速缓存在访问存储器地址0x4 时产生缺失。这次访问将地址0x0~0xC 的数据装入高速缓存块中所有的后续访问(如地址0xC所示)都将在高速缓存中命中。因此,缺失率为1/15=6.67%。

5. 小结
高速缓存组织为二维阵列。行称为组,列称为路。阵列中每个表项包括一个数据块、相有效位和标志位。高速缓存的关键参数为:容量C、块大小b(以及块数B=C/b)和一组内的块数(N)
高速缓存的容量、相联度、组大小和块大小一般都是2的整数次幂。这使得高速缓存字段(标志、组号和块内偏移)均为地址位的子集。增加相联度 N通常可以减少因为冲突引起的缺失。但是高的相联度需要更多的标志比较器。增加块的大小b,可以从空间局部性获益而减少缺失率。然而,对于固定大小的高速缓存,这将减少组数,可能导致更多的冲突。同时,它也会增加缺失代价。
1.3.3 数据的替换
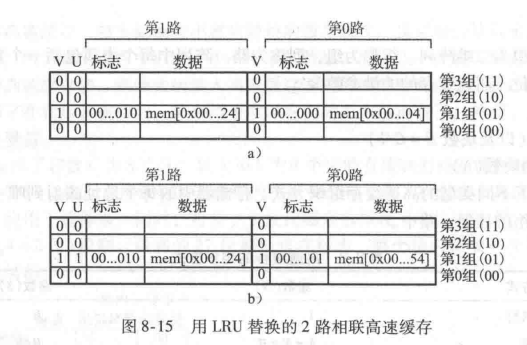
在直接映射高速缓存中,每个地址映射到唯一的块和组上。如果当必须装入数据时一个组满了,那么组中的块就必须用新数据替换。在组相联和全相联的高速缓存中,高速缓存必须在组满时选择哪一个块被替换。(注:直接相联映射是没这个烦恼的,因为直接相联映射是主存和缓存地址一一对应,直接相联映射如果有替换需求,只能把之前组号一致的存储在缓存中的字给踢出去,而组相联和全相联允许多个主存地址映射到缓存相同的组,这样就会存在竞争。)时间局部性原则建议最好选择最近最少使用的块,因为它看起来最近最不可能再次用到。因此,大部分相联高速缓存采用最近最少使用(Least Recently Used,LRU)的替换原则。
在2路组相联高速缓存中,1位使用位(use bit)U,说明组中的哪一路是最近最少使用的。每次使用其中一路,就修改U位来指示另一路为最近最少使用的。对于多于2 路的组相联高速缓存,跟踪最近最少使用的路将更为复杂。为了简化问题,组中的多路分成两部分(group),而U指示哪一部分为最近最少使用的。替换时,就从最近最少使用的部分中随机选择一块用于替换。这样的策略称为伪 LRU,易于实现。
问题7:最近最少使用替换。写出下述执行代码后,容量为8个字的2 路组相联高速缓存的内容。假设采用最近最少使用替换策略,块大小为1个字,初始时高速缓存为空。

解:前两条指令将存储器地址0x4 和0x24 中的数据装入高速缓存的第1组如图8-15a所示。U=0说明在第0路的数据是最近最少使用的。下一次存储器访问地址x54,依然映射到组1,这将替换第0路中的最近最少使用的数据。如图8-15b 所示。随后将使用位设置为1.说明第1路中的数据是最近最少使用的。
1.3.4 高级高速缓存设计
现代系统使用多级高速缓存来减少内存访问时间。本节将讨论两级高速缓存系统的性能,研究块大小、相联度和高速缓存容量对缺失率的影响。本节还介绍高速缓存如何使用直写或写回策略控制处理存储器存储或写人。
1. 多级高速缓存
大容量高速缓存的效果更好,因为它们更有可能保存当前需要使用的数据,因此会有更低的缺失率。然而,大容量高速缓存的速度比小容量高速缓存低。现代处理器系统常常使用至少两级高速缓存,如图 8-16 所示。第一级(L1)高速缓存足够小以保证访问时间为1~2个处理器周期。第二级(L2)高速缓存常常也由SRAM构成,但比L1高速缓存容量更大,因此速度也更慢。处理器首先在L1高速缓存中查找数据。如果在L1高速缓存中缺失,那么处理器将从 L2高速缓存中查找。如果L2高速缓存也缺失,处理器将从主存访问取数据因为访问主存的速度实在太慢了,所以一些现代处理器系统在存储器层次结构中增加了更多级的高速缓存。
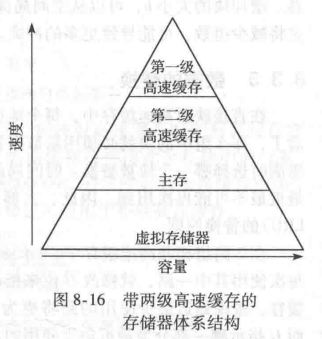
问题8:带L2高速缓存的系统。使用图8-16 中的系统,其中L1、L2高速缓存和主存的访问时间分别为1、10和100个周期。假设L1、L2高速缓存的缺失率分别为5%和20%。即5%的访问在L1 中缺失,其中这些的20%在L2中依然缺失。那么平均访问时间(AMAT)是多少?
解:每次内存访问都检查L1高速缓存。当L1高速缓存缺失时(访问中的5%),处理器就检查L2高速缓存。当L2高速缓存缺失时(访问中的20%),处理器就从主存中获取数据。可以计算平均内存访问时间为:1周期+0.05x[10 周期+0.2(100 周期)]=2.5周期。
一种典型的错误答案:0.95x1 + 0.05x0.8x10 + 0.05x0.2x100 =2.35,这个错误答案认为访问L1成功的概率为0.95,平均算下来访问L1的时间就是0.95x1。但是实际上,我们要访问L2的前提是访问L1失败了,所以L1未命中的5%的时间也要算在里面,所以访问L1的平均时间就是1。同理,对于访问L2和访问主存的关系也是这样,我们访问L2的平均时间是0.05x10 而不是0.05x0.8x10,不管我们L2是否命中,我们访问L2的概率都是5%,平均时间就要花0.05x10。
2. 写入策略
前面各节关注存储器装入。存储器的存储或写入遵循与装入操作相似的过程。当存储器存储时,处理器检查高速缓存。如果高速缓存缺失,就会将相应的高速缓存块从主存取出放入高速缓存中,然后将高速缓存块中的适当字写入。如果高速缓存命中,就简单地将字写入高速缓存块中。
高速缓存可以分为写直达和写回两种方式。在直写(write-through)高速缓存中,写人高速缓存块的数据同时写人主存。在写回(write-back)高速缓存中,需要增加一位与每个高速缓存块关联的脏位(D)。当写入高速缓存块时 D设置为1,其余情况为0。只在脏高速缓存块从高速缓存中逐出时,才将它们写回主存。直写高速缓存不需要脏位,但比写回高速缓存需要更多主存写入操作。由于主存访问时间太长,所以现代的高速缓存往往采用写回方式。
问题9:直写与写回。假设某高速缓存的块大小为4个字。使用直写和写回两种策略,在执行以下代码时主存访问次数分别为多少?

解:所有4个存储指令写同一个高速缓存块。在直写高速缓存中,每一个存储指令将一个字写人主存,需要4次主存写人。写回策略仅仅在脏高速缓存块被逐出时才需要一次主存访问。
1.3.5 缓存性能
缓存性能和如下条件有关:
- 缓存大小
- 缓存块大小
- 关联度
- 替换算法
1.3.5.1 缓存大小
- 缓存大小:总数据(不包括标签)容量越大可以更好地利用时间局部性 ,但是并不总是更好
- 缓存太大会对命中和未命中延迟产生不利影响:缓存越小越快,越大越慢 ,访问时间可能会影响关键路径
- 缓存太小不能很好地利用时间局部性:经常替换有用的数据
缓存大小和命中率的关系图如下,可以发现,缓存越大(注意不是cache block),命中率越高。
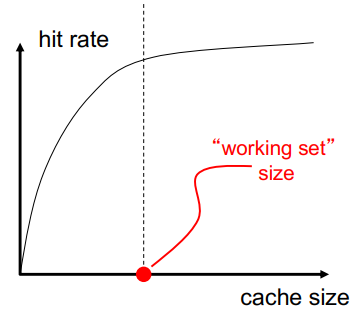
Working set工作集: 在时间间隔内(一个时钟周期内),执行应用程序引用的整个数据集。
从上图可以发现,当缓存大小大于工作集之后,缓存命中率提升便不在明显。
1.3.5.2 缓存块大小
- 块大小是与地址标签关联的数据,不一定是层次结构之间的传输单位
- 子块:一个块分成多个部分(每个块都有 V/D 位)
- 块太小 :不能很好地利用空间局部性 ,同时具有较大的标签开销 ,如果空间局部性不高,则浪费缓存空间和带宽/能量
- 块太大 块总数太少, 较少的时间局部性利用
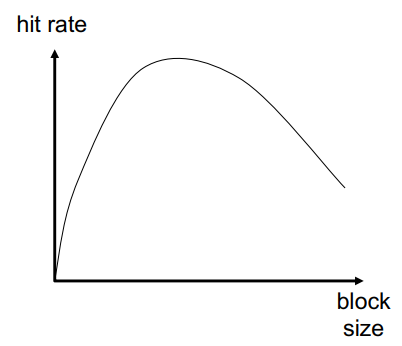
从上图可以发现,缓存块大小在中间位置达到最大的缓存命中率,所以块大小不能太大也不能太小。
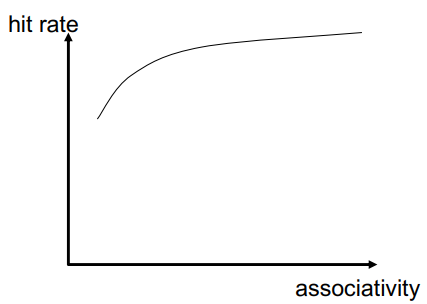
1.3.5.3 关联度Associativity
同一索引(即集合)中可以存在多少个块?
- 更大的关联性 ,更低的未命中率(减少冲突) :更高的命中延迟和区域成本(加上递减的回报)
- 更低的关联性:更低的成本 ,更低的命中延迟 ,这对 L1 缓存尤为重要
从下图可以发现,提高关联度,能提高缓存整体的命中率。
1.3.5.4 Cache Miss的分类
- 强制未命中Compulsory miss
- 对地址(块)的第一次引用总是会导致未命中
- 除非缓存块由于以下原因(Capacity miss、conflict miss)而不在缓存中,否则第一次引用未命中的后续引用应命中
- 容量未命中Capacity miss
- 容量未命中:缓存太小,无法容纳所需的一切
- 定义为即使在相同容量的完全关联缓存(具有最佳替换)中也会发生的未命中
- 冲突未命中Conflict miss
- 定义为任何既不是强制也不是容量的未命中
如何减少各种未命中
- 强制未命中:缓存是无济于事的,预取(prefetching)可以: 预测很快需要哪些块
- 冲突未命中:提高关联度
- 在不使缓存关联的情况下获得更多关联性的其他方法 :受害者(Victim)缓存 、更好的随机索引 、软件提示。
- 容量未命中:更好地利用缓存空间:保留将被引用的块
- 软件管理:划分工作集和计算,使每个“计算阶段”都适合缓存
1.3.5.5 如何提高缓存性能
三个基本目标 :
- 降低未命中率 (注意:如果从缓存中逐出成本更高的重新取回块,降低未命中率会降低性能 )
- 减少未命中延迟或未命中成本
- 减少命中延迟或命中成本
以上三者共同影响性能
具体做法:
- 减少为命中率:
- More associativity
- Alternatives/enhancements to associativity
- Victim caches, hashing, pseudo-associativity, skewed associativity
- Better replacement/insertion policies
- Software approaches
- 减少未命中延时/开销:
- Multi-level caches
- Critical word first
- Subblocking/sectoring
- Better replacement/insertion policies
- Non-blocking caches (multiple cache misses in parallel)
- Multiple accesses per cycle
- Software approaches
下面我们重点关注软件提升Cache性能的方法:重构数据访问模式(Restructuring Data Access Patterns)、重构数据布局(Restructuring Data Layout)。
重构数据访问模式

重构数据布局
- 基于指针的遍历(例如,链表)
- 假设有一个巨大的链表(1字节个节点)和唯一的key
- 为什么下图的代码缓存命中率很差?因为“其他字段”占据了缓存行的大部分,即使很少访问!
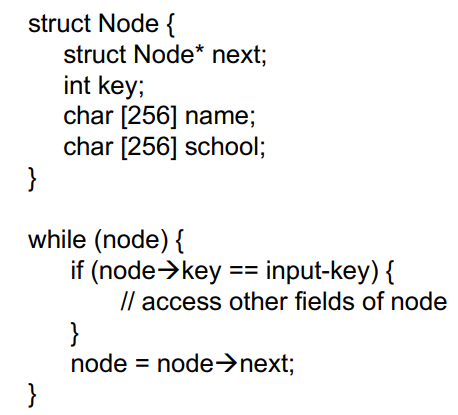
重构思路:将数据结构的常用字段分开,打包成一个单独的数据结构 ,谁应该这样做? 程序员 、编译器 、硬件,重构思路如下图所示。

1.4 虚拟存储器简要介绍(Digital Design and Computer Architecture第二版)
大部分现代计算机系统使用硬盘(也称为硬盘驱动器)作为存储器层次结构中的最底层。与理想的大容量、快速、廉价存储器相比,硬盘容量大,价格便宜,但是速度却非常慢。硬盘比高成本效益的主存(DRAM)提供了更大容量。然而,如果大部分的存储器访问需要使用硬盘,那么性能将严重下降。在 PC上一次运行太多程序时,就可能遇到这种情况。

图8-19显示了一个掉了盖子的硬盘驱动器,它由磁性存储器构成,也称为硬盘。顾名思义,硬盘包含了一片或者多片坚硬的盘片(plater),每个盘片的长三角臂末端都有一个读/写头(read/write head)。移动读/写头到盘片的正确位置,当盘片在它下面旋转时以磁方式读/写数据。读/写头需要毫秒级的时间完成盘片上的正确寻道,这对于人看来很快,但却比处理器慢百万倍。
在存储器层次结构中增加硬盘的目的是在提供一个虚拟化的廉价超大容量存储系统,而且在大部分存储器访问时,依然能提供较快速的存储器访问速度。例如,一个只提供128MB DRAM的计算机,可以用硬盘高效提供2GB的存储。较大的2GB存储器称为虚拟存储器(virtual memory),较小的128MB主存称为物理存储器(physical memory)。在本节中,我们将使用物理存储器这个术语来表示主存。
程序可以访问虚拟存储器中任意地方的数据,所以它们必须使用虚地址(virtual address)指明其在虚拟存储器中的位置。物理存储器内保存虚拟存储器中大部分最近访问过的子集。这样,物理存储器充当虚拟存储器的高速缓存。因此,大部分访问将以DRAM的速度命中物理存储器,而程序却可以使用更大容量的虚拟存储器。

对于前面讨论的相同的高速缓存原理,虚拟存储器系统使用了不同的术语。表8-4总结了类似的术语。虚拟存储器分为虚页(virtual page),大小一般为4KB。物理存储器也类似地划分为大小相同的物理页。虚页可能在物理存储器(DRAM)中,也可能在硬盘上。例如,图8-20给出了一个大于物理存储器的虚拟存储器。长方形表示页。有些虚页在物理存储器中,另一些在硬盘上。根据虚地址确定物理地址的过程称为地址转换(address translation)。如果处理器试图访问不在物理存储器中的虚地址就会产生页面失效(page fault),操作系统将页从硬盘装入物理存储器中。
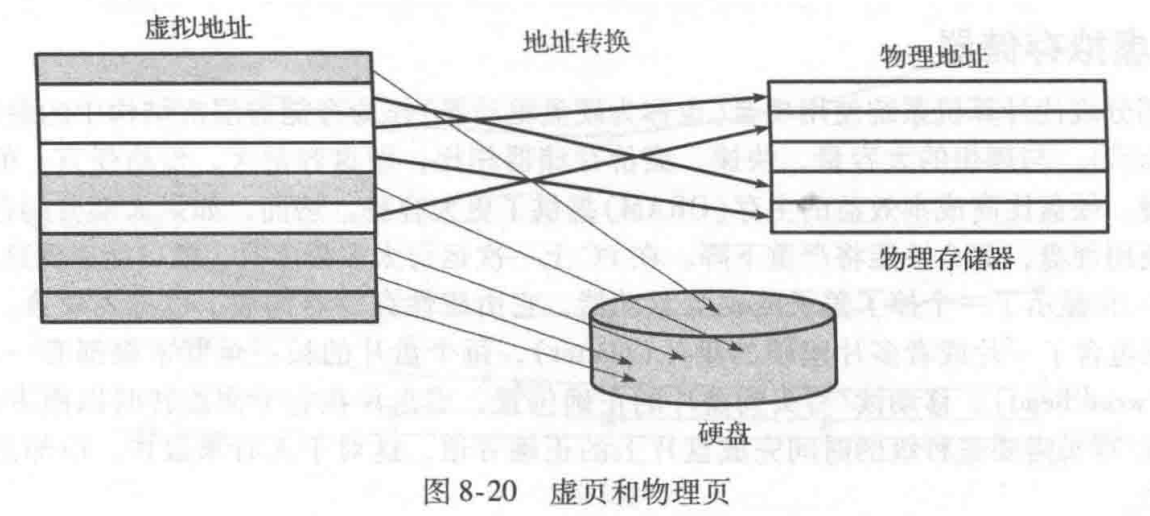
为了防止冲突产生的页面失效,任何虚页都可以映射到任何物理页。换句话说,物理存储器的行为就像虚拟存储器的全相联高速缓存。在常规的全相联高速缓存中,每一个高速缓存块都有一个比较器来比较最高有效地址位与标志,确定请求是否命中块。在类似的虚拟存储器系统中,每一个物理页也需要一个比较器来比较最高有效虚拟地址位和标志,确定虚页是否映射到物理页上。
1.4.1 地址转换
在包含虚拟存储器的系统中,程序使用虚地址访问大容量存储器。计算机必须将虚地址转换以便找到物理存储器中的地址,或产生一个页面缺失然后从硬盘获得数据。
前面提到,虚拟存储器和物理存储器都分成页。虚地址或者物理地址的最高有效位分别说明虚页号或物理页号(page number)。最低有效位说明页内字的位置,也称为页偏移量。
图8-21 说明了包含2GB 虚拟存储器、128MB物理存储器、页大小为4KB 的虚拟存储器系统页结构。MIPS处理器采用32位地址。对于
2
G
B
=
2
31
2GB=2^{31}
2GB=231字节的虚拟存储器,只使用虚拟存储器地址的最低31位第32位总为0。类似地,对于
128
M
B
=
2
27
128MB=2^{27}
128MB=227字节的物理存储器,只使用物理地址的最低27位,最高5位总为0。(注意:一个十六进制地址位对应二进制的4位,即0x1=0001,同时一个十六进制地址位,对应一个字节,因此一个字对应4个十六进制地址的长度。)
因为页大小为
4
K
B
=
2
12
4\mathrm{KB}=2^{12}
4KB=212字节,所以有
2
31
/
2
12
=
2
19
2^{31}/2^{12}=2^{19}
231/212=219个虚页和有
2
27
/
2
12
=
2
15
2^{27}/2^{12}=2^{15}
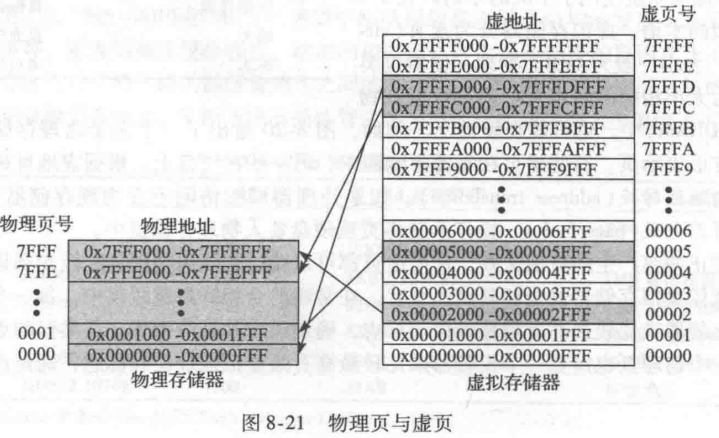
227/212=215个物理页。因此虚页号和物理页号分别为19 位和 15 位。物理存储器在任何时间只能最多保存 1/16 的虚页其余的虚页保存在硬盘上。
图8-21显示了虚页5映射到物理页1,虚页0x7FFFC映射到物理页0x7FFE等。例如,虚地址0x53F8(虚页5内0x3F8的偏移量)映射到物理地址0x13F8(物理页1内0x3F8的偏移量)。虚地址和物理地址的最低12位是一样的(0x3F8),它指明虚页和物理页内的页偏移量。从虚地址到物理地址的转换过程中,只需要转换页号。(地址中的后三位十六进制数表示页偏移,剩下的地址都是页号,上图8-21地址0x0000FFF中的FFF就是页偏移,0x0000就是页号。)
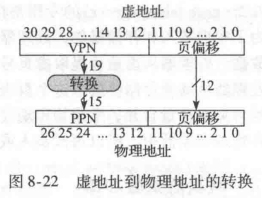
图8-22说明了虚地址到物理地址之间的转换。最低12位(对应16进制地址的3位)为页偏移量,不需要转换。虚地址的最高19位为虚页号(Virtual PageNumberVPN),可转换为15位的物理页号(PhysicalPageNumber,PPN)。后面两小节将进一步介绍页表以及如何使用TLB实现地址转换。
问题10:虚拟地址到物理地址的转换。用图8-21中的虚拟存储器系统确定虚地址0x247C的物理地址。
解:12位页偏移量(0x47C)不需要转换。虚地址的其余19位给出了虚页号,所以虚地址0x247C应在虚页0x2中。在图8-21中,虚页0x2映射到物理页0x7FFF。因此,虚地址0x247C映射到物理地址0x7FFF47C。
1.4.2 页表
处理器使用页表(page table)将虚地址转换为物理地址。对每一个虚页,页表都包含一个表项。表项包括物理页号和有效位。如果有效位是1,则虚页映射到表项指定的物理页。否则,虚页在硬盘中。
因为页表非常大,所以它需要存储在物理存储器中。假设页表存储为连续数组,如图8-23所示。页表包含图8-21中的存储器系统的映射。页表用虚页号(VPN)作为索引。例如,第5个表项说明虚页5映射到物理页1。第6个表项无效(V=0),所以虚页6在硬盘中。
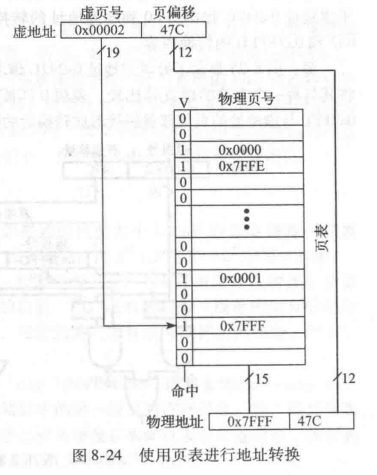
问题11:使用页表实现地址转换。使用图8-23给出的页表找出虚地址0x247C的物理地址。
解:图8-24给出了虚地址0x247C到物理地址的转换。其中12位页偏移量不需要转换。虚地址的其余 19 位为虚页号0x2,是页表的索引。页表将虚页 0x2 映射到物理页 0x7FFF。所以虚地址0x247C映射到物理地址0x7FFF47C。物理地址和虚地址的最低12 位是相同的。
页表可以存放在物理存储器的任何位置,这由操作系统自由决定。处理器一般使用称为页表寄存器(page table register)的专用寄存器存放物理存储器中页表的基地址。
为了实现装入和存储操作,处理器必须首先将虚地址转换为物理地址,然后访问物理地址中的数据。处理器从虚地址提取虚页号,将其与页表寄存器相加来寻找页表表项的物理地址。然后处理器从物理存储器读取这个页表表项,以便获得物理页号。如果表项有效,处理器将物理页号与页偏移量合并,生成物理地址。最后,它在物理地址上读出或者写入数据。因为页表存储在物理存储器中,所以每次装入或者存储操作都需要两次物理存储器访问。(第一次访问是获取物理地址,第二次访问是用物理地址去操作地址内的数据)
1.4.3 转换后备缓冲器
如果每一次的装入和存储都需要页表,那么对虚拟存储器的性能就会产生严重的影响,将增加装入和存储的延迟。幸运的是,页表访问有很大的时间局部性。数据访问的时间和空间局部性,以及大的页意味着很多连续的装入和存储操作都发生在同一页上。因此,如果处理器能记住它最后读出的页表表项,它就可能重用这个转换表项而不需要重读页表。一般来说,处理器可以将最近使用的一些页表表项保存在称为转换后备缓冲器(translation lookaside buffer,TLB)的小型高速缓存内。处理器在访问物理存储器页表前,它首先在 TLB 内查找的转换表项在实际的程序中,绝大多数访问都在 TLB 中命中,避免了读取物理存储器中页表的时间消耗。
TLB以全相联高速缓存的方式,一般有16~512个表项。每个TLB表项有一个虚页号和它相应的物理页号。使用虚页号访问TLB。如果TLB 命中,它返回相应的物理页号:否则,处理器必须从物理存储器读页表。TLB 设计得足够小使得它的访问时间可以小于一个周期。即使如此,TLB 的命中率一般也大于99%。对于大多数装入和存取指令,TLB 使所需的内存访问数从2次减少为1次。(因为处理器一次访问TLB,拿到物理地址后再去访问内存,这样就只要访问一次内存了)
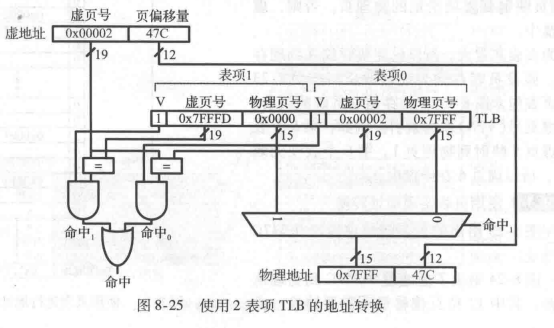
问题12:使用TLB实现地址转换。考虑图8-21中的虚拟存储器系统。使用一个2表项TLB 完成地址转换,或解释为什么对于虚地址0x247C和0x5FB0到物理地址的转换必须访问页表。假设 TLB 目前保存有效的虚页0x2和0x7FFFD的转换内容。
解:图8-25显示了处理虚地址0x247C 请求的2表项TLB。TLB 接收传人地址的虚页号0x2将其与每一个表项的虚页号比较。表项0匹配且有效,所以请求命中。将匹配表项的物理页号0x7FFF 与虚地址的页偏移量拼接形成转换后的物理地址。与往常一样,页偏移量不需要转换。对虚地址0x5FB0的请求在TLB 中缺失。所以请求需要转发到页表进行转换。
1.5 虚拟存储器具体介绍
本文1.4节只是对虚拟存储器做简要介绍,有关于虚拟存储器的具体介绍,可以看下面这篇文章:计算机体系结构----TLB+Cache,这篇文章主要参考《超标量存储器设计》----姚永斌进行总结的。
1.6 缓存一致性
关于缓存一致性的介绍看计算机体系结构----缓存一致性/多处理机
作业
作业1:缓存标记位
假设您正在运行具有以下数据访问模式的程序。该模式仅执行一次。
0x0 0x8 0x10 0x18 0x20 0x28
- 如果使用缓存大小为 1 KB、块大小为 8 字节(2 个字)的直接映射缓存,则缓存中有多少组?
解:1024/8=128 - 在与第一问相同的缓存和块大小下,给定内存的直接映射缓存的未命中率是多少?
解:100% - 对于给定的内存访问模式,以下哪项最能降低未命中率?(缓存容量保持常数)
(i) Increasing the degree of associativity to 2.
(ii) Increasing the block size to 16 bytes.
(iii) Either (i) or (ii).
(iv) Neither (i) nor (ii).
解:(ii),提高关联度而提高Cache命中率的方法是整体上对所有Cache设计来说的,但是在本题这种访问pattern来说,由于每次访问的地址都不冲突,所以提高关联度并没什么用。
作业2:缓存标记位
考虑具有以下参数的缓存:N(关联性)= 2,b(块大小)= 2 个字,W(字大小)= 32 位,C(缓存大小)= 32 K words,A(地址大小)= 32 位。只需要考虑word地址。
- 写出地址的标记位、组位、块偏移位和字节偏移位各自所需要的比特位数。
解:
– N u m _ s e t = log ? 2 C a c h e _ s i z e B l o c k _ s i z e × A s s o c i a t i v i t y = log ? 2 32 × 2 10 2 × 2 = 13 b i t s Num\_set=\log_{2}\frac{Cache\_size}{Block\_size\times Associativity}=\log_{2}\frac{32\times2^{10}}{2\times2}=13bits Num_set=log2?Block_size×AssociativityCache_size?=log2?2×232×210?=13bits
– B l o c k _ o f f s e t = 1 b i t s Block\_offset=1bits Block_offset=1bits,块偏移用来选择需要的数据在一个块中的哪个字中的,这里一个块就只有两个字,所以一个比特就能表示快偏移-- – B y t e _ o f f s e t = log ? 2 4 = 2 b i t s Byte\_offset=\log_24=2bits Byte_offset=log2?4=2bits,字节偏移表示要选择的数据在这个字的哪个字节,这里是字节寻址,所以只需要两个比特位表示
– T a g = A ? N u m _ s e t ? B l o c k _ o f f s e t ? B y t e _ o f f s e t = 16 b i t s Tag=A-Num\_set-Block\_offset-Byte\_offset=16bits Tag=A?Num_set?Block_offset?Byte_offset=16bits
– 具体位及其分布如下,表格第二行表示地址位。

– 注意:有些题目把set称为index,还有就是有些题目把block offset 和byte offset统称为offset,注意分辨,我们这里采用《Digital Design and Computer Architecture》这本书的记法。 - 所有的缓存标记用了多少比特位?
A l l _ t a g s = o n e _ t a g _ b i t s × N u m b e r = 16 × 2 13 × 2 = 2 18 b i t s All\_tags=one\_tag\_bits\times Number=16\times2^{13}\times2=2^{18}bits All_tags=one_tag_bits×Number=16×213×2=218bits - 假设每个缓存块也有一个有效位 (V) 和一个脏位 (D)。缓存中每个组(set)的大小是多少,包括数据、标记(Tag)和状态。
s e t _ s i z e = ( v a l i d _ b i t + d i r t y _ b i t + T a g _ b i t s + d a t a _ b i t s ) × A s s o c i a t i v i t y = ( 1 + 1 + 16 + 64 ) × 2 = 164 b i t s \begin{aligned} &set\_size=(valid\_bit+dirty\_bit+Tag\_bits+data\_bits)\times Associativity \\ &=(1+1+16+64)\times2=164bits \end{aligned} ?set_size=(valid_bit+dirty_bit+Tag_bits+data_bits)×Associativity=(1+1+16+64)×2=164bits?
作业3:缓存命中
内存访问时间(Memory access time):假设一个程序具有以下的缓存访问时间:1 cycle(L1 cache),10 cycle(L2 cache),30
cycles(L3 cache),和300 cycles(内存),以及L1、L2 和 L3 的MPKI 分别为20、10 和 5。你是否需要 L3 cache吗?其中 MPKI 表示每千条指令中的缓存失效次数(Misses Per Kilo Instructions)。
解:
有L3 Cache时的平均访存时间:1 + 0.02 ? (10 + 0.01 ? (30 + 0.005 ? 300)) = 1.2063 𝑐𝑦𝑐𝑙𝑒𝑠
没有 L3 Cache 时的平均访存时间:1 + 0.02 ? (10 + 0.01 ? 300) = 1.26 𝑐𝑦𝑐𝑙𝑒𝑠
所以需要 L3 Cache
作业4:缓存命中
假设一个两路组相联缓存 (2-way set-associative cache ) ,只有两个组 (sets)。假设块 (block) A 映射到组 0,块 B 映射到组 1,块 C 映射到组 0,块 D 映射到组 1,块 E 映射到组0,以此类推。对于以下的访问模式,请估算命中 (hits) 和失效 (misses)次数:
访问模式:ABBECCADBFAEGCGA
解:M MH M MH MM HM HMM M H M
命中次数5,未命中次数11
作业5:缓存大小
8 KB 的全相联数据缓存阵列( fully-associative data cache array ),Cacheline大小为 64 字节,假设地址位为 40 位。
- 有多少个组(sets)?有多少路(ways)?
- 有多少索引位(index bits)、偏移位(offset bits)、标记位(tagbits)?
- 标记数组(tag store)有多大?

作业6:缓存大小
假设页面大小为 16KB,缓存块大小为 32 字节。 如果我想实现一个虚拟索引、物理标记的 L1 缓存( virtually indexed physically tagged
L1 cache ),我可以实现的最大直接映射 L1 缓存( direct-mapped L1 cache)大小是多少?我可以实现的最大 2 路(2-way)缓存大小
是多少?
解:最大直接映射L1缓存大小:512个缓存块即51232B=16KB,最大2路缓存大小:1024个缓存块即102432B=32KB
作业7:内存结构
以下服务器支持的最大内存容量是多少:有 2 个处理器插槽(processor sockets ),每个插槽有 4 个内存通道( memory channels
),每个通道支持 2 个双排列 DIMMs( dual-ranked DIMMs ),并且是 x4 4Gb 的 DRAM 芯片?
解:2 sockets x 4 channels x 2 DIMMs x 2 ranks x16 chips x 4Gb capacity = 256 GB
注意这道题x4表示一个chip只能一个时钟周期吐4bits数据出来,本文前面讲的例子是8bits数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Spring之国际化:i18n
- Python知识(4/20):Python条件判断
- 浪涌抑制器的应用及注意事项?|深圳比创达电子
- 入站请求负载均衡解决方案 LVS 的介绍
- Linux操作系统的ECS云服务器上搭建WordPress网站教程
- Java企业电子招投标系统源代码,支持二次开发,采用Spring cloud框架
- 面试springcloud知识点
- MySQL基础面试知识点
- 设计模式下
- C++面向对象(OOP)编程-四种类型转换