MySQL基础面试知识点
SQL执行流程和语法树
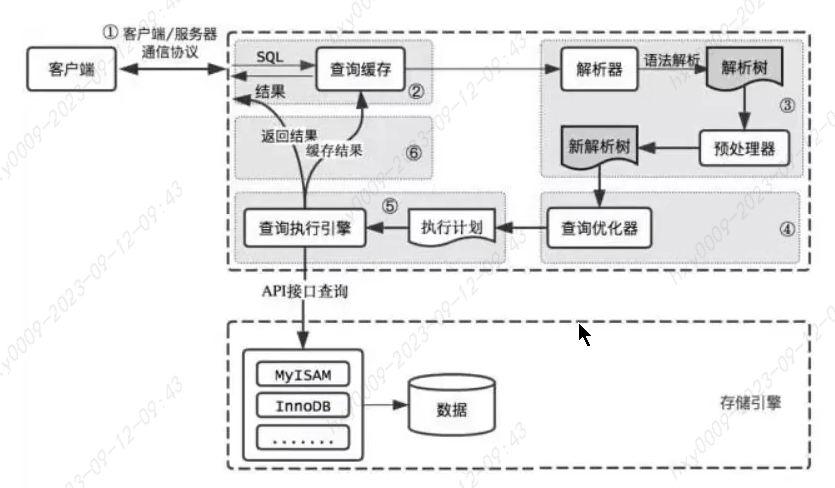
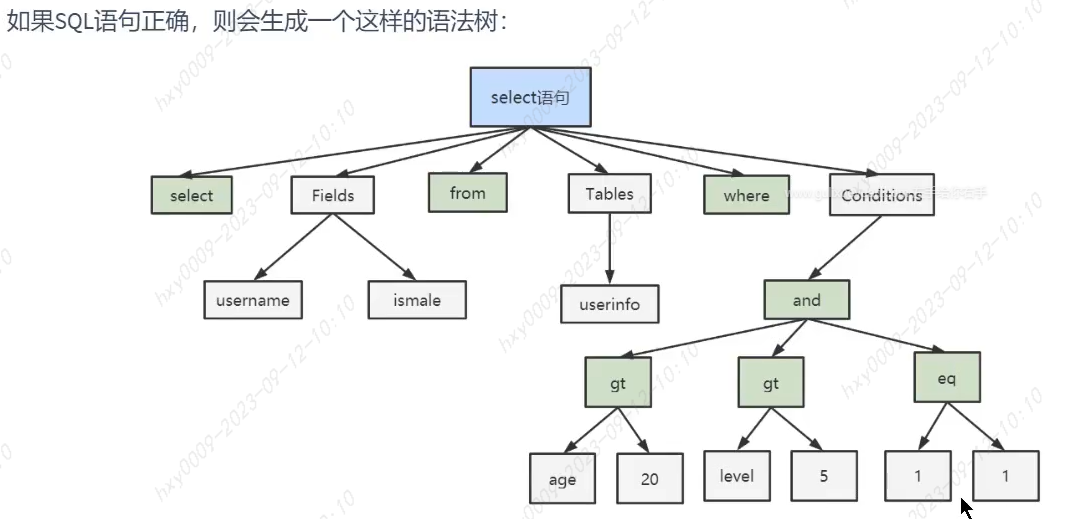
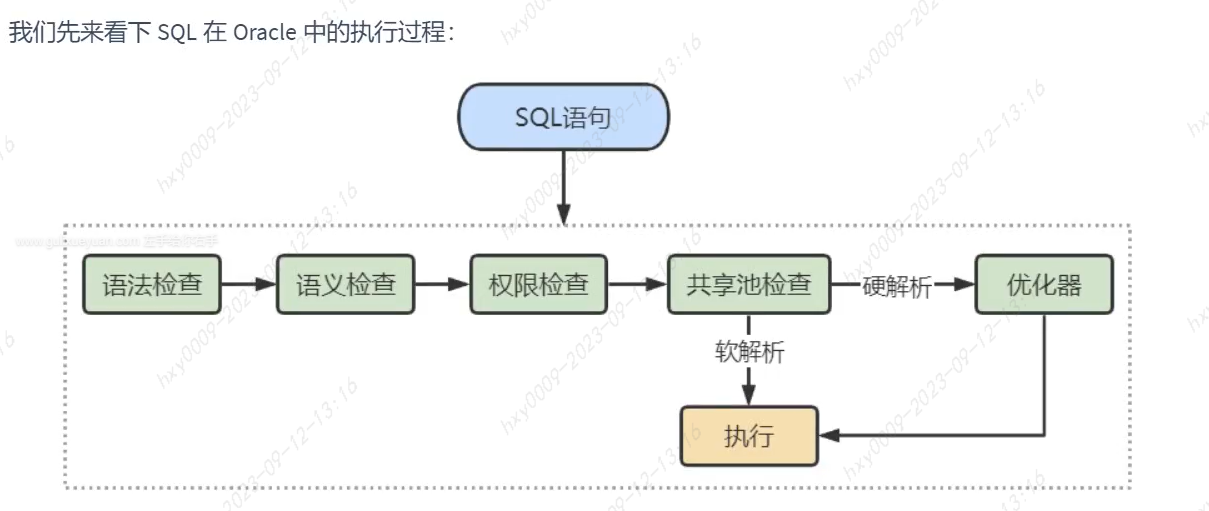
MySQL中命中查询缓存很严格:必须是完全相同的查询SQL Oracle中采用共享池来判断是否存在缓存和执行计划,共享池检查(Hash计算):
-
软解析:Hash值在库缓存中查找到执行计划,直接进入到执行器环节(可以绑定变量大概率命中缓存)
-
硬解析:没有则会进入优化器,执行硬解析环节
查询缓存和缓存池的区别:
-
查询缓存是select语句封装的一种key-value的形式,8.0中干掉了
-
缓存池是一种数据页,用于存储内存中的部分热数据,查看缓冲池大小:
show variables like 'innodb_buffer_pool_size/instances';
存储引擎比较
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行标锁 | 表锁,即使操作一条数据也会锁全表,不适合高并发的操作 | 行锁,粒度更细,适合高并发 |
| 缓存 | 只缓存索引.myd.myi | 索引即数据.frm.ibd |
| count(*) | O(1) | 全表计算 |
| 是否默认安装 | Y | Y |
| 是否默认使用 | N | Y |
| 关注点 | 节省资源、消耗少、简单事务 | 并发写、支持事务(崩溃恢复)、更大的内存 资源 |
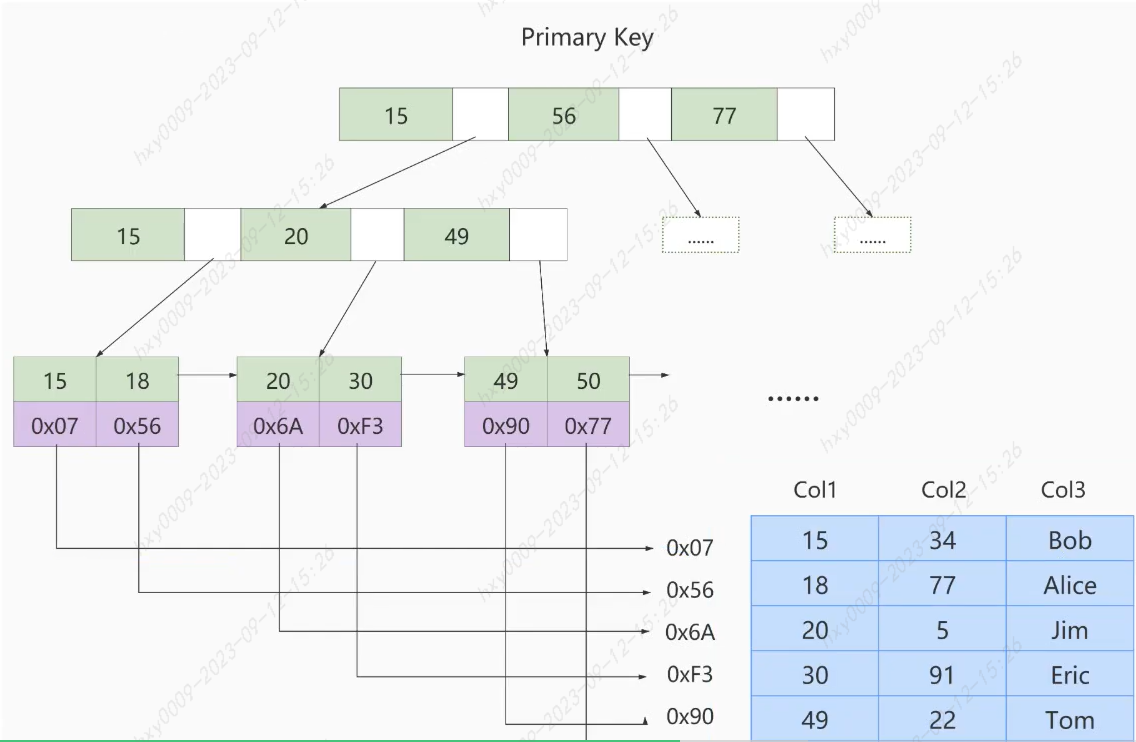
聚簇索引、二级索引和联合索引
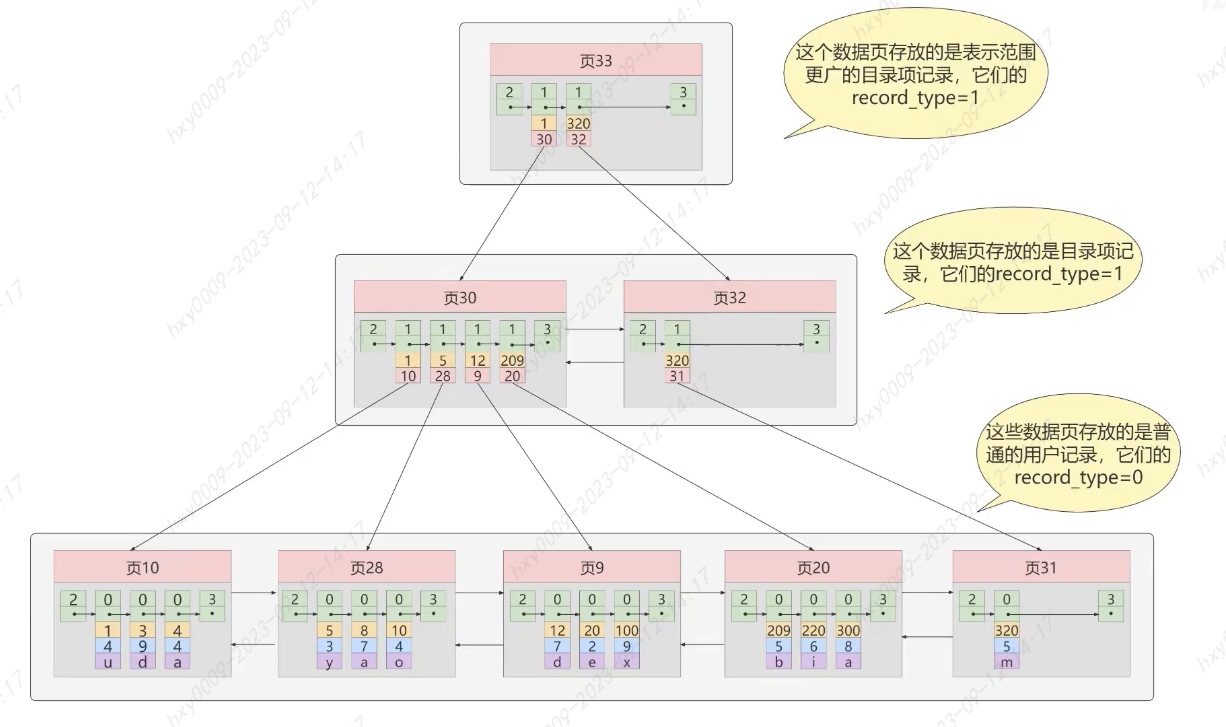
聚簇索引(只能有一个且搜索条件是主键才生效):就可以理解为是一个B+树,有存储顺序,索引即数据,不需要用INDEX显示的创建,innodb引擎会自动为我们创建,因为按顺序且是B+树结构,所以查找速度快,但主键不应该自定义插入,代价很高,页分裂。
二级索引(一个表可以有多个二级索引,需要进行回表操作):某列的叶子结点不存储实际的数据行,而是包含指向数据行的指针,可以快速定位到符合条件的数据行。
联合索引(索引的顺序非常重要):同时包含多个列的索引,可以提高多列条件查询的性能。
Hash结构(等值查找)
Hash算法:hash('hello')hash函数一包,每次计算同一个值得哈希值都是一样的
Hash碰撞:对哈希值取%时,由于散列在同一个散列表中,两个不同的关键字会映射到相同的位置,再采用链接法(数组+链表)
Hash索引:在等值判断上有优势,但是在范围查找上面是O(n)级别,数据的存储是无序的,
联合索引是加法,无非对单个进行判别,重复值列多的情况很极端
数据库调优问题的步骤
-
观察服务器状态,是否周期性波动
-
加缓存或者更改缓存失效策略
-
仍有不规则延迟或卡顿,开启慢查询(设置慢查询阈值),explain分析慢SQL,或者show profiles查询具体每一个步骤的时间成本
-
SQL等待时间长:调优服务器参数,SQL执行时间长:索引优化,关联表优化,表设计优化
-
SQL瓶颈:分库分表,垂直分离
查看系统性能参数:show status like '参数'Connections:服务器连接次数,Slow_queries:慢查询次数
查看慢查询日志参数:set global slow_query_log = on
EXPLAIN工具的使用(?重点?)
| 列名 | 描述 |
|---|---|
| id | 唯一的ID,驱动表和被驱动表优先级一样,几个select对应几个ID |
| select_type | select--关键字对应的查询类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等 |
| table | 表名 |
| partitions | 匹配的分区信息,对于非分区表值为NULL,当查询的是分区表时,partitions显示分区表命中的分区情况。 |
| type | 针对单表的访问方法,性能由好到差的连接类型为( system ---> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge ---> index_subquery -----> range -----> index ------> all ) |
| possible_keys | 可能用到的索引 |
| key | 实际上用到的索引 |
| key_len | 实际使用索引的长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
索引优化和查询优化
-
索引失效,没有充分利用索引--索引建立
-
关联太多的join--SQL优化
-
调整服务器参数--调整my.cnf
-
数据过多--分库分表
索引失效的几种情况:
-
全值匹配我最爱
-
最佳左前缀法则
-
主键插入顺序
-
计算、函数、类型转换导致失效(字符串类型不加'')
-
范围条件右边的失效
-
!=和<>不等于索引失效
-
is null可以使用索引,is not null不使用索引
-
like用%通配符开头
-
or前后存在不是索引的字段
覆盖索引:一个索引包含了满足查询结果的数据。字段之间没有顺序的要求,可以少但是不能多
索引下推:区别于用到聚簇索引不存在回表行为,如果需要回表,会在第一个索引用到后在用下面的索引进行过滤操作,减少回表的次数
-
访问类型为range、ref、eq_ref、ref_or_null
-
ICP仅用于二级索引。
-
相关子查询不能使用ICP
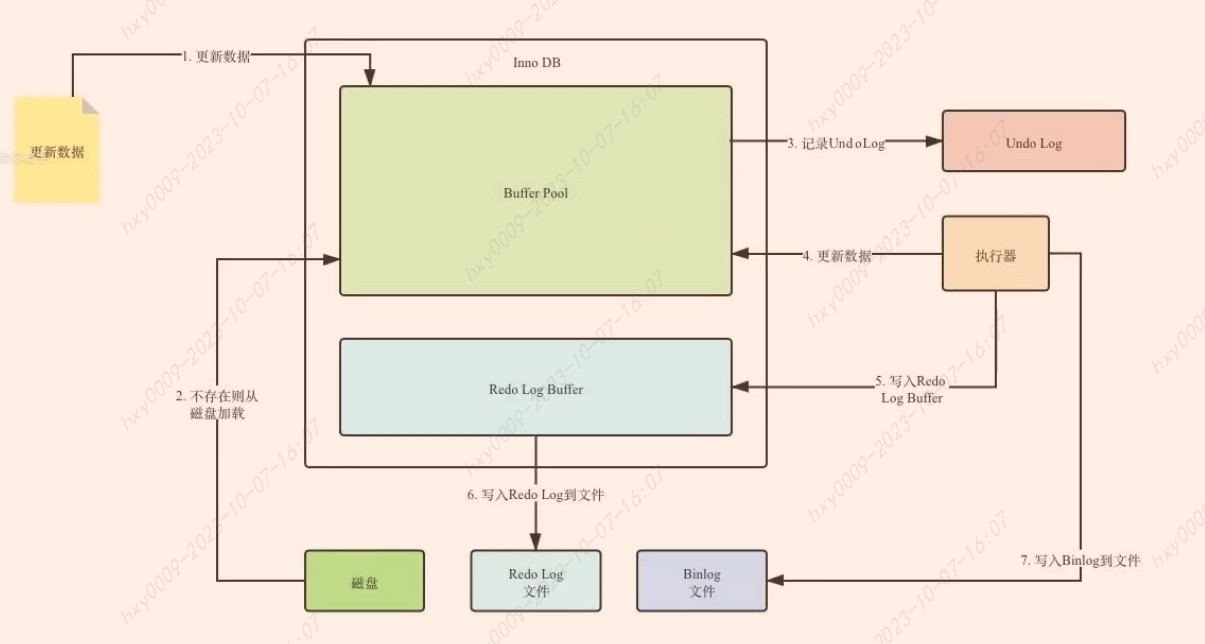
有了Redo Log和Undo Log之后的更新数据为例:如果我们需要更新一条数据,先去Buffer Pool中去找,如果没找到,再去磁盘空间中加载,加载到缓冲区以后,更新之前先把原始数据放在Undo Log的回滚段文件中,然后执行器做更新的操作,执行完以后,我们会把更新后的数据写入到内存层面的Redo Log Buffer中参数0、1、2策略控制,再更新到Redo Log File(日志文件优先的原则)文件中,然后再刷盘到磁盘中。其中在执行器执行更新的操作时,在数据库层面会记录相反的二进制命令写入到BinLog日志中,会作为事务回滚的作用。

MVCC(多版本并发控制):是为了解决事务隔离级别下的一致性读的问题,做查询使用时,不用等待另一个事务释放锁。快照读:实现基于MVCC,即使有读写冲突时,也能做到不加锁,非阻塞并发读,采用乐观锁的思想,不加锁的简单select都属于快照读,串行条件下退化成当前读。当前读:是一种基于加锁的操作,是悲观锁的实现。MVCC三剑客:隐藏字段(row_id--主键--唯一键--自动生成一个,trx_id,roll_pointer--可以通过它找到undo log旧版本修改前的信息)、ReadView、Undo Log版本链
读已提交的场景下:每次select都生成一个新的ReadView
可重复的的场景下:都是用第一次生成的ReadView
-
首先获取事务自己的版本号,也就是事务ID
-
获取ReadView
-
查询得到的数据,然后与ReadView中的事务版本号进行比较
-
如果不符合ReadView规则,就需要从Undo Log中获取历史快照
-
最后返回符合规则的数据
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- javaWeb蛋糕商城(前后台) 2
- python2和python3有什么区别,在这里详细的说一下
- 25考研数据结构复习·2.线性表.2
- django基于spark的电影推荐系统(程序+开题)
- 设计模式在Java开发中的应用
- ROS 传感器—相机的介绍
- 深入了解Python中文件IO的使用技巧,提高代码处理效率
- 自动驾驶代客泊车AVP安全监控设计
- MongoDB vs MySQL:项目选择哪一个数据库系统?
- R语言生物群落(生态)数据统计分析与绘图教程