(2024,强化学习,提示扩展,原始提示中心引导)Parrot:用于文本到图像生成的帕累托最优多奖励强化学习框架
Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
最近的研究表明,使用带有质量奖励(quality rewards)的强化学习(RL)可以提高文本到图像(T2I)生成中生成图像的质量。然而,对多个奖励进行简单聚合可能会导致在某些指标上过度优化并在其他指标上降低,手动找到最佳权重也具有挑战性。一种在 RL 中联合优化 T2I 生成的多个奖励的有效策略是非常可取的。本文介绍了 Parrot(Pareto-optimal multi-reward reinforcement learning framework for text-to-image generation),一种新颖的 T2I 生成的多奖励 RL 框架。通过使用按批次 Pareto 最优选择,Parrot 在 T2I 生成的 RL 优化过程中自动识别不同奖励之间的最佳权衡。此外,Parrot 采用 T2I 模型和提示扩展网络的联合优化方法,促进了生成具有质量意识的文本提示,从而进一步提高最终图像的质量。为了抵消由于提示扩展而导致的原始用户提示的潜在灾难性遗忘,我们在推理时引入了原始提示中心引导(original prompt centered guidance),确保生成的图像忠实于用户输入。大量实验证明,Parrot 在各种质量标准,包括美学、人类偏好、图像情感和文本图像对齐等方面,优于几种基准方法。
3. 基础
扩散概率模型:扩散概率模型 [15] 通过逐渐去噪嘈杂图像生成图像。具体而言,给定来自数据分布 x_0 ~ q(x_0) 的真实图像 x_0,扩散概率模型的正向过程 q(x_t | x_0, c) 生成嘈杂图像 x_t,引发了在文本提示 c 条件下的分布 p(x_0, c)。在无分类器引导 [14] 中,去噪模型通过以下无条件评分估计 ?_θ(x_t, t) 和条件评分估计 ?_θ(x_t, t, c) 的线性组合来预测噪声 ˉ?_θ:
![]()
其中 t 表示扩散的时间步数,null 表示空文本,w 表示无分类器引导的引导比例,其中 w ≥ 1。请注意,?_θ 通常由 UNet [39] 参数化。
基于 RL 的 T2I 扩散模型微调:给定从生成的图像得到的奖励信号,RL 微调 T2I 扩散模型的目标是优化一个策略,该策略定义为 T2I 扩散模型的一个去噪步骤。特别是,Black 等人 [4] 应用策略梯度算法(policy gradient algorithm),将扩散模型的去噪过程视为马尔可夫决策过程(Markov decision process,MDP),通过迭代执行多个去噪步骤。随后,一个黑盒奖励模型 r(·, ·) 从采样的图像 x_0 预测一个单一的标量值。给定文本条件 c ~ p(c) 和图像 x_0,可以定义目标函数 J 以最大化期望奖励,如下所示:
![]()
其中,预训练的扩散模型 p_θ 利用文本条件 c 产生一个样本分布 p_θ(x_0 | c)。修改这个方程,Lee等人 [10] 证明了目标函数的梯度 ?J_θ 可以通过梯度上升算法计算,而无需使用奖励模型的梯度,如下所示:?

其中,T 表示扩散采样过程的总时间步数。使用参数 θ,期望值可以在扩散采样过程的轨迹上进行计算。

4. 方法
4.1 Parrot 概述
图 2 显示了 Parrot 的概述,它由提示扩展网络(prompt expansion network,PEN)p_? 和 T2I 扩散模型 p_θ 组成。首先,PEN 的初始化是从提示扩展对的示范上监督微调检查点,而 T2I 模型从预训练的扩散模型初始化。给定原始提示 c,PEN生成扩展提示 ?c,而 T2I 模型根据此扩展提示生成图像。在多奖励 RL 微调期间,抽样一批 N 张图像,并为每张图像计算多个质量奖励,包括文本图像对齐、美学、人类偏好和图像情感等方面。基于这些奖励分数,Parrot 使用非支配排序(non-dominated sorting)算法识别批次的帕累托最优集(Pareto-optimal set)。然后,这组最优图像用于通过 RL 策略梯度更新联合优化 PEN 和 T2I 模型参数。在推断过程中,Parrot 同时利用原始提示及其扩展,平衡保持对原始提示的忠实性和融入更多细节以获得更高质量。

4.2 按批次帕累托最优选择
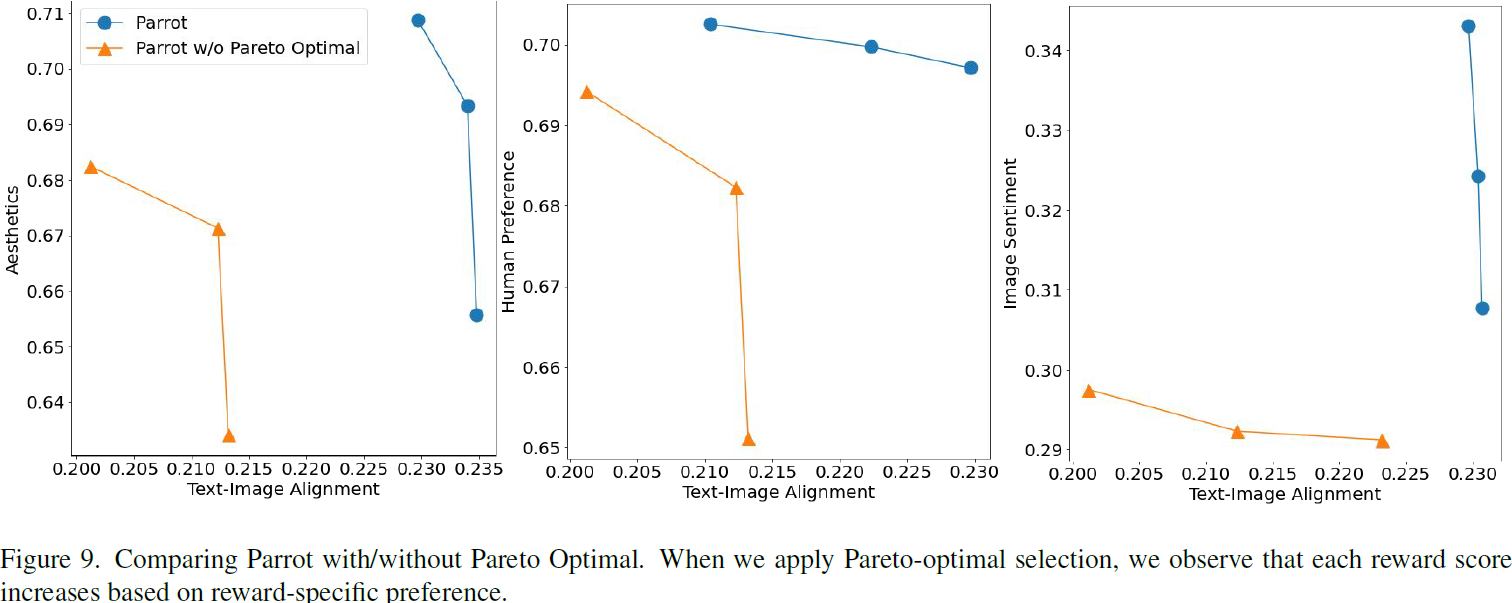
算法 1 概述了 Parrot 的过程。与使用所有图像更新梯度不同,Parrot 专注于高质量样本,在每个小批次中考虑多个质量奖励。在多奖励 RL 中,T2I 模型生成的每个样本为每个奖励呈现不同的权衡。在这些样本中,存在一个子集,其目标之间存在多样的最优权衡,称为帕累托集。对于帕累托最优样本,没有目标值可以进一步改善而不损害其他目标。换句话说,帕累托最优集不被任何数据点支配,也被称为非支配集。为了使用 T2I 扩散模型获得帕累托最优解,Parrot 通过使用非支配排序算法选择来自非支配集的数据点。这自然地鼓励 T2I 模型生成相对于多奖励目标而言的帕累托最优样本。
奖励特定偏好:受到在多目标优化中使用偏好信息的启发 [27],Parrot 通过奖励特定的标识来纳入偏好信息。这使得 Parrot 能够自动确定每个奖励目标的重要性。具体来说,我们通过在第 k 个奖励前面添加奖励特定标识符 “<reward k>” 来丰富扩展提示 ?c。基于这个奖励特定提示,生成 N 张图像,并在梯度更新期间用于最大化相应的第 k 个奖励模型。在推断时,所有奖励标识符 “<reward 1>,...,<reward K>” 的串联用于图像生成。
非支配排序:Parrot 根据多个奖励之间的权衡构建非支配点的帕累托集。这些非支配点优于其余的解决方案,并且彼此之间不受支配。形式上,支配关系定义如下:当且仅当对于所有 i ∈ 1, ...,m,
![]()
并且存在 j ∈ 1, ...,m,使得
![]()
则图像 x^a_0 支配图像 x^b_0,表示为 x^b_0 < x^a_0,。例如,给定小批次中的第 i 个生成的图像 x^i_0,当小批次中没有任何点支配 x^i_0 时,它被称为非支配点。
策略梯度更新:对于未包含在非支配集中的数据点,我们将奖励值设为零,并且仅更新这些非支配数据点的梯度,如下所示:

其中 i 表示小批次中图像的索引,P 表示批次中的一组非支配点。K 和 T 分别是奖励模型的总数和总扩散时间步数。在每个批次更新扩散模型时,使用相同的文本提示。
4.3 原始提示中心引导
虽然提示扩展可以增强细节并通常提高生成质量,但有人担心添加的上下文可能会淡化原始输入的主要内容。为了在推断过程中减轻这一问题,我们引入了原始提示中心引导。在以原始提示为条件进行采样时,扩散模型 ?_θ 通常通过组合无条件得分估计和提示条件得分估计来预测噪声。我们提出在 T2I 生成中使用两个引导的线性组合,而不仅仅依赖于 PEN 生成的扩展提示:一个来自用户输入,另一个来自扩展提示。原始提示的强度由引导比例 w_1 和 w_2 控制。噪声 ˉ?θ 的估计,根据方程 1 的推导如下:

其中 null 表示空文本。???
5. 实验







本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 移动CRM系统有哪些具体的应用场景?移动CRM好用吗?
- 使用docker实现logstash同步mysql到es
- 代码随想录算法训练营第4天 | 24. 两两交换链表中的节点 , 19.删除链表的倒数第N个节点 , 面试题 02.07. 链表相交 , 142.环形链表II
- 代码随想录第十八天 513 找树左下角的值 112 路径之和 106 从中序与后序遍历序列构造二叉树
- MySQL的增删改查(进阶)--下
- HttpClient Http Get方法请求
- 腾讯云 IPv6 解决方案
- C/C++ 函数参数按引用传递、指针传递、实参传递
- GitHub无法完成推送 的设置选项
- 嵌套调用和链式访问