Transformer模型中前置Norm与后置Norm的区别
主要介绍原始Transformer和Vision Transformer中的Norm层不同位置的区别。
前言
在讨论Transformer模型和Vision Transformer (ViT)模型中归一化层位置的不同,我们首先需要理解归一化层(Normalization)在这些模型中的作用。归一化层主要用于调整输入数据的尺度,以减少梯度消失或梯度爆炸的问题,从而提高模型的稳定性和训练效率。
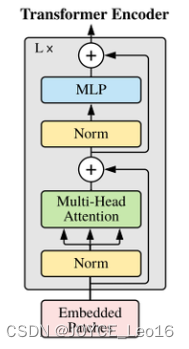
原始的transformer模型把norm归一化层放在了注意力机制的后面,但是vision transformer模型把norm归一化层放到了注意力机制的前面。
在Transformer模型中,归一化(Normalization)层的位置在注意力前后有所不同。这种差异主要源于对模型训练和稳定性的考虑。
? ? ? ? ? ?? ? ?
? ?
不同位置的作用
在原始的transformer模型中,归一化层被放置在注意力机制之后。这种设计有助于提高模型的训练效率和稳定性。在自注意力机制中,输入序列通过与权重矩阵相乘来计算注意力分数,这可能导致梯度消失或梯度爆炸的问题。将归一化层放在注意力机制之后,可以有效缓解这些问题,因为归一化层可以调整输入的尺度。使得梯度更加稳定。此外,由于注意力机制本身是一种非线性的处理方式,把归一化层放在它之后,可以帮助保持输入数据分布的稳定性,这对于模型收敛和有效训练来说是至关重要的。
在Vision transformer(ViT)模型中,归一化层被放置在注意力机制之前。这种设计选择是为了更好地适应图像数据的特性。在ViT模型中,输入的图像数据首先经过卷积层进行初步的特征提取,然后这些特征通过归一化层和线性层进行进一步处理,以便于计算注意力分数。鉴于图像数据通常具有较大的尺度变化,将归一化层置于注意力机制之前可以更有效地调整输入特征的尺度。这样的设计使得模型能够更好地适应和处理图像数据,从而在视觉任务中表现出更优异的性能。
总结
-
在原始的Transformer模型中,归一化层放在注意力机制之后:这样的安排有助于模型更好地保留和学习输入数据之间的关系,同时也有利于保持模型训练的稳定性和高效性。
-
在Vision Transformer模型中,归一化层放在注意力机制之前:这种设计有助于针对图像数据调整输入特征的尺度,使模型在处理图像数据时更加高效和精确。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 嵌入式学习-网络编程-Day2
- workFlow c++异步网络库编译教程与简介
- 【每周AI简讯】GPT-5将有指数级提升,GPT Store正式上线
- Android Termux技能大揭秘:安装MySQL并实现公网远程连接
- Dart安装(Winodws)
- 用23种设计模式打造一个cocos creator的游戏框架----(十九)备忘录模式
- Tektronix泰克TCP303示波器电流探头
- 有的人是如何做到把OpenAI的API-Key变得这么便宜的?
- 2.控制语句
- Linux chmod命令详解