NVMe-oF RDMA vs. TCP延时测试对比:端到端SPDK的意义
前不久看到一篇《NVIDIA BlueField?再创?DPU?性能世界纪录》的新闻,该测试环境是2台服务器,每台各安装2块NVIDIA Bluefield-2 DPU,形成4条100GbE以太网直连,两端分别跑NVMe-oF Target(存储目标)和Initiator(主机端)。
测试结果包括TCP和RoCE(RDMA)两部分,上图是第一部分。我们看到,用户态SPDK to SPDK的512Byte小块读测试达到了41.5M(超过4100万)IOPS;Linux 5.15内核的FIO测试只有不到SPDK一半的性能,应该是CPU被I/O中断跑满了,4.18内核则又低了不少。
作为块存储设备,512B IOPS性能基本上只对Optane(傲腾)SCM介质有意义,比如Intel P5800X的4K随机读写、512Byte随机读IOPS指标分别为是150万和460万。对于传统NAND闪存SSD来说,小于4KB的IOPS通常也不会更高了,因为闪存页面大小一开始就是4KB(先进制程NAND的物理页面大多在8KB-16KB)。
另一点值得注意:在NVIDIA新闻的测试平台介绍中,并没有提到用的什么持久化数据盘,也就是说该测试应该是用DRAM内存模拟块设备来跑网卡的极限性能,没有提到随机访问那就是顺序IO了。
在4KB数据块测试中,用户态与内核的差距就没有那么大了,因为网卡的吞吐量快跑满了。其中SPDK to SPDK的读达到了345Gb/s,读写双向则是431Gb/s。
如果换用RoCE,Bluefield的512B小块IOPS,以及4KB双向带宽比TCP有进一步的提升。不过在这个新闻稿中没有提到延时数字,于是我又把https://spdk.io/doc/performance_reports.html?网站上Intel的测试报告翻了出来。
端到端SPDK延时只有5μs:这个数据落盘了吗?

上图引用自《SPDK NVMe-oF RDMA/TCP (Target & Initiator) Performance Report Release 21.10》这2份文档。Intel是用一台配有16个P4610 SSD的服务器跑NVMe-oF Target,前端通过2个CX-5 100GbE网卡直连2台NVMe-oF Initiator服务器。
这个测试环境,比前面NVIDIA那份新闻稿更接近真实应用。不过当我看到下面的延时数据时,还是怀疑这部分测试的IO是否都落盘(SSD)了?

上面图表是我从Intel报告的“Test Case 3: Linux Kernel vs. SPDK NVMe-oF RDMA Latency”中整理的数据,用iodepth=1和单任务能测出最短延时。
可以看出,使用Linux内核的NVMe-oF Initiator和Target测试,延时在16-18μs之间;如果只是把后端存储换成SPDK Target,延时降低到13μs多;只有IO负载请求和目标端都使用SPDK才能达到最短的5μs左右。
显然NAND闪存SSD应该跑不了这么快。可以参考下我在《NVMe-oF三种协议(FC、RDMA、TCP)对比:成败不只看性能》中对比的数字(如下图)——这个是包含SSD延时在内的。

图注:“不同NVMe-oF协议的延时对比主要看低并发/队列深度时。纯软件NVMe/TCP接近100微秒了;而RoCE只有大约30微秒;FC-NVMe在50微秒左右,TCP-Offload甚至比它还要稍好一些。”
记得在几年前的《SPDK实战、QoS延时验证:Intel Optane P4800X评测(5)》一文中,我测试过当时唯一能达到10μs以内延时的SSD(DRAM内存盘除外)。
当年我用FIO测试P4800X在Linux Kernel下的随机读延时为14.2μs,而用户态的SPDK则可以跑到6.49 μs。如果是NAND闪存SSD,正常应该在100 μs左右的水平;随机写有可能会较短,因为固态盘上有Cache。

在Intel报告的Latency测试配置部分,我认为是找到了答案(如果不正确的话,请读者朋友纠正我):bdev_null_create应该是创建了一个并不在SSD上的“空”设备,即等于10240MB的内存盘。为了对比测试NVMe-oF网络的延时,在这一段如此操作倒也合理。
同时我还对比了另一份本地盘的测试报告《SPDK NVMe BDEV Performance Report Release 21.10?》,其中延时数据如下:

上面这个才是实打实的NAND闪存SSD延时水平——我们看到Linux内核libaio引擎平均随机读延时为85μs,SPDK BDEV和io_uring则能够分别降低到71μs和73μs。
SPDK对NVMe/TCP网络延时贡献有限

这个图表整理自Intel报告的“Test Case 3: Linux Kernel vs. SPDKNVMe-oF TCP Latency”部分数据,可以看出NVMe/TCP的延时水平,以及SPDK在这里的价值。
本文主要就写这么多,下面给出本次阅读理解的结论:
1、SPDK的最大价值,依然是用户态Pooling,相比传统内核IRQ I/O能够显著节省CPU资源;
2、当使用Linux Kernel I/O时,NVMe-oF RoCE网络的延时约在16-18μs;NVMe/TCP则达到30?μs左右,并且TCP网络混合读写的延时还有增大;
3、在Target/Initiator端到端SPDK配置下,NVMe-oF RoCE延时降低到5μs左右;NVMe/TCP与内核态I/O相比也有改善,但仍在20μs以上;
注:除非特别说明,以上关于NVMe-oF延时的数据,都没有将SSD延时考虑在内。
简单来说,NVMe/TCP比基于RDMA和FC的NVMe-oF网络延时高,这是许多人都知道的。端到端SPDK能够降低延时,而且这种贡献在RoCE网络下表现更好。
附:SPDK(即IRQ vs. Polling)性能提升原理示意图

上面这个是经典的Polling模式,会把一个CPU核心长时间占满。
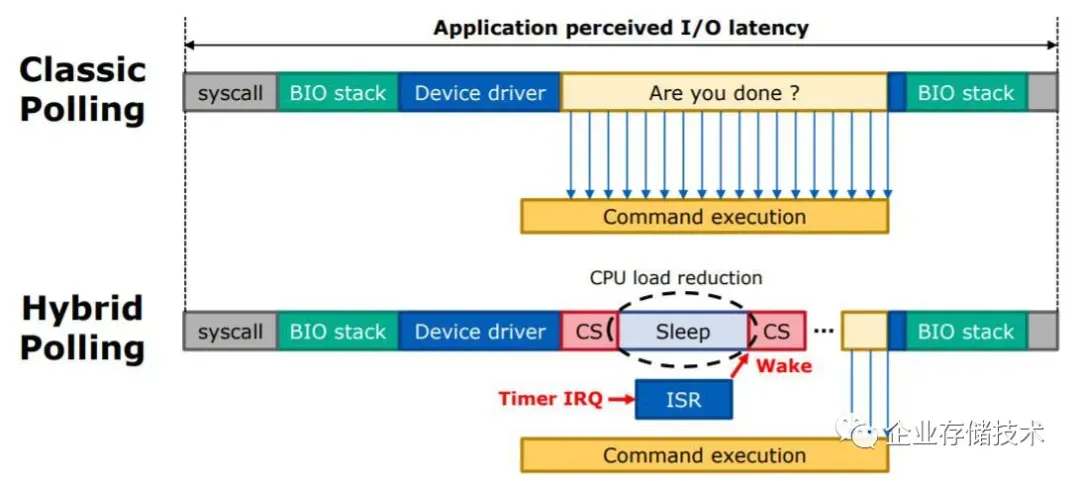
后来又有人提出了Hybird Polling(混合轮询),在没有I/O时可以插入Sleep睡眠来降低CPU负载。
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 为什么员工都非常抵触「绩效考核」,该怎么办呢?
- 手把手搭建jenkins + docker + k8s 持续集成、自动化发布环境
- CVHub|AI标注神器 X-AnyLabeling-v2.3.0 发布!支持YOLOv8旋转目标检测、EdgeSAM、RTMO等热门模型!
- leetcode-Excel表列名称
- MiniTab的拟合回归模型的分析
- QCustomPlot开源库使用
- 21章网络通信
- 使用kali linux时遇到的一些问题及解决方案汇总
- 1688商品数据API接口调用key和密钥
- Linux 常用解压命令tar和zip(详细篇)