Flume基础知识(九):Flume 企业开发案例之复制和多路复用
发布时间:2024年01月06日
1)案例需求
使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储 到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local FileSystem。
2)需求分析:
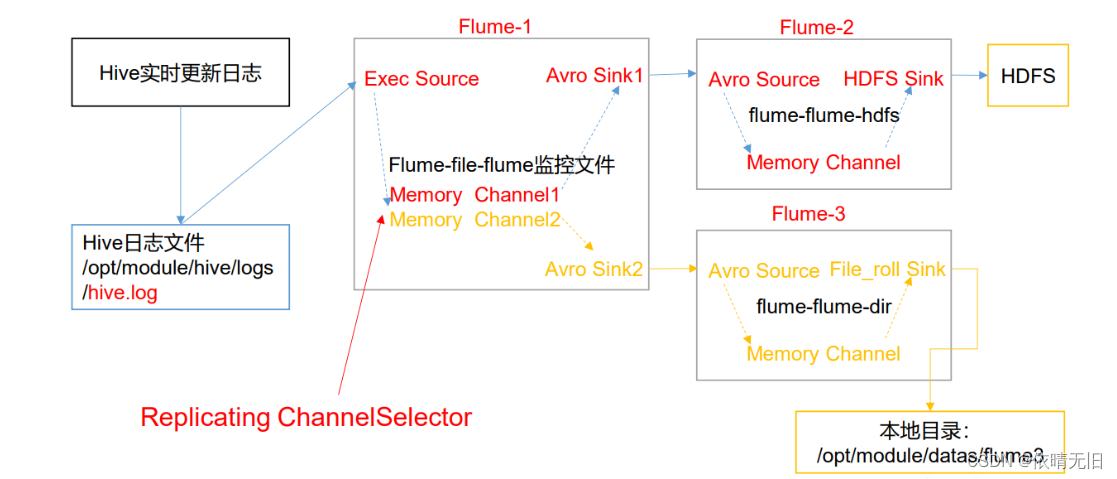
3)实现步骤:
(1)准备工作
在/opt/module/flume/job 目录下创建 group1 文件夹
[root@hadoop102 job]$ cd group1/在/opt/module/datas/目录下创建 flume3 文件夹
[root@hadoop102 datas]$ mkdir flume3(2)创建 flume-file-flume.conf
配置 1 个接收日志文件的 source 和两个 channel、两个 sink,分别输送给 flume-flume-hdfs 和 flume-flume-dir。 编辑配置文件
[root@hadoop102 group1]$ vim flume-file-flume.conf 添加如下内容
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有 channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
# sink 端的 avro 是一个数据发送者
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop100
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop100
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2(3)创建 flume-flume-hdfs.conf
配置上级 Flume 输出的 Source,输出是到 HDFS 的 Sink。
编辑配置文件
[root@hadoop102 group1]$ vim flume-flume-hdfs.conf添加如下内容
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
# source 端的 avro 是一个数据接收服务
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop100
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop100:8020/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 30
#设置每个文件的滚动大小大概是 128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1(4)创建 flume-flume-dir.conf
配置上级 Flume 输出的 Source,输出是到本地目录的 Sink。
编辑配置文件
[root@hadoop102 group1]$ vim flume-flume-dir.conf 添加如下内容
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop100
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/data/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目 录。
(5)执行配置文件
分别启动对应的 flume 进程:flume-flume-dir,flume-flume-hdfs,flume-file-flume。
[root@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf
[root@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf
[root@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf(6)启动 Hadoop 和 Hive
[root@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[root@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[root@hadoop102 hive]$ bin/hive hive (default)>
文章来源:https://blog.csdn.net/zuodingquan666/article/details/135395323
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- jenkins入门
- Web前端-JavaScript(js流程控制)
- 910b上跑Chatglm3-6b进行流式输出【pytorch框架】
- dubbo的基础知识
- Elasticsearch介绍和使用步骤详解(含详细代码)
- 蓝桥杯嵌入式stm32串口接收(使用中断)
- GBASE南大通用-TeraData迁移GBase 8a PoC实践
- 数之寻软件下载
- 【MATLAB第82期】基于MATLAB的季节性差分自回归滑动平均模型SARIMA时间序列预测模型含预测未来
- 【解决方案】电能质量在线监测装置和防孤岛保护装置在特斯拉工厂分布式光伏项目的应用