从池化的角度看GNN(包含PR-GNN,EdgePool等7篇论文)上篇
从池化的角度看GNN(包含PR-GNN,EdgePool等7篇论文)
前言
这里是早期的笔记,主要是关于图的池化的相关论文的笔记及看法。这里主要是自己看的其中一部分,之所以汇总到一起是感觉有些不同的地方。所以把这几篇论文放在一起了。
主要包括的论文有下面这几篇:

- 论文PR-GNN:《Pooling Regularized Graph Neural Network for fMRI Biomarker Analysis》
- 论文EdgePool:《Edge Contraction Pooling for Graph Neural Networks》
- 论文HaarPooling:《Haar Graph Pooling》
- 论文GSAPool:《Structure-Feature based Graph Self-adaptive Pooling》
- 论文StructPool:《StructPool: Structured Graph Pooling via Conditional Random Fields》
- 论文ASAP:《ASAP: Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations》
- 论文HCP-SL:《Hierarchical Graph Pooling with Structure Learning》
由于篇章有略微有点点长,所以我这里放了上中下2篇
原创笔记,未经同意请勿转载
一些总结
现有图池化操作主要可以分为全局池化(如SortPool)、分层池化,分层池化中还可以分为基于聚类(如DiffPool,StructPool)和基于重要性排序(如TopK Poolig,SAGPool,GSAPool等)的池化操作,同时也可以衍生出基于频谱上处理的池化操作(如EigenPool,LaPool,HaarPool等)。
- 改进1:为更加有效的利用图中边所带来的信息,还又EdgePool的池化操作,使得图在池化过程中也可以关注到对应的边缘特征。
- 改进2:如何更加有效地利用节点对之间关联关系所包含的特征信息,如PR-GNN
- 改进3:如何改进基于重要性排序的图池化操作?——》所面对的问题:丢弃不重要节点所带来的特征信息重要缺失问题 ——-》解决方法:① 拉大节点之间差距,如PR-GNN ② 在丢弃前聚类节点特征,如GSAPool ③ 多特征融合与子图学习机制辅助,如HCP-SL
- 改进4:如何改进基于聚类的图池化操作?——-》所面对的问题:聚类之后的模型可解释性差,聚类之间的关联关系少 ——》解决方法:① 聚类信息中融入关联关系与图结构信息,如StructPool ② 簇内外注意力机制加持与局部关注,如ASAP
- 改进5:如何更有效的保留图层次及子图结构信息?——》所面对的问题:在空间域上处理的池化操作不利于图结构信息的保留 ——》解决方法:频谱上的处理:① 拉普拉斯变换,如LaPool ② 图傅里叶变换,如EigenPool ③ Haar变换,如HaarPool
一些早期论文的简要介绍
上篇章中先放第1篇论文的笔记。中篇放后面3篇,下篇再放最后三篇。
1??论文PR-GNN:《Pooling Regularized Graph Neural Network for fMRI Biomarker Analysis》
- 来源: MICCAI 2020
- 原文链接: https://link.springer.com/chapter/10.1007/978-3-030-59728-3_61
- 代码链接: https://github.com/xxlya/PRGNN_fMRI
- 数据及任务: (1)研究任务:图分类任务(ASD分类)、检测出显著的ROI区域(可用于下游任务)
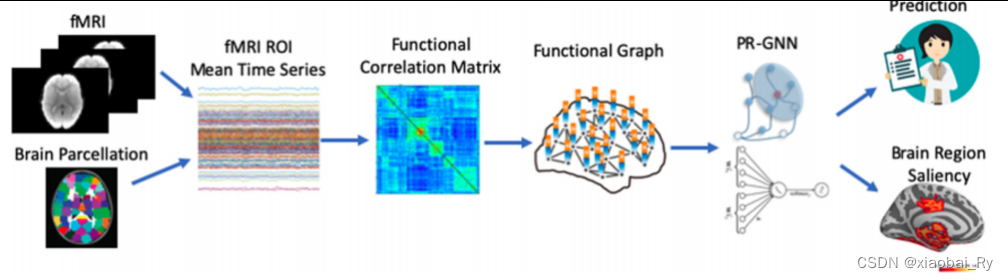 (2)数据分布:【非公开,私有】75名ASD与43名HC(年龄与智商相仿)
(2)数据分布:【非公开,私有】75名ASD与43名HC(年龄与智商相仿)
(3)数据格式:fMRI
(4)图谱:Desikan-Killiany atlas(84ROIs)
(5)数据预处理:- ① 时间序列的选取:之前的文章都是讲ROI内所有体素的时间序列均值作为ROI的时间序列,但PR-GCN 通过bootstraping随机采样ROI中1/3的体素作为该ROI的时间序列。论文中应该是为了随机采样的数据足够表达该区域的特征又不过度冗余(从单次来看的话),做了10次1/3的体素随机采样,这样子每个ROI就有10个时间序列,数据量增大了10倍!【之前好像没有看过这种预处理,但可以跟前面采样多视角的思想有点像,就是数据处理的角度不太一样】
- ②边属性的构建:非全连接图(只保留前10%的边),与其他论文不同,该论文边的连接强度时采用偏相关系数而非皮尔逊系数
- ③节点属性的构建:采用节点的person相关系数来度量
主要的出发点: 现存graph pooling主要包含两种:基于聚类的池化和基于重要性的池化,对于PR-GNN论文所研究的任务来说,该两种方法存在以下局限性:
(1)基于聚类的池化
- Core :基于聚类思想的池化实际上就是基于图的拓扑结构将图的节点聚类到一个super node。

- 缺点:可解释性差【在医学的任务上网络的可解释性有着重要的作用】
注:这个之前组会有分享过比较经典的论文【DIFFPOOL和EigenPooling】,这两篇都是利用聚类思想的池化,特别地,EigenPooling是基于谱聚类思想实现的。 - EigenPool与DiffPool的区别
① EigenPool用来进行图的层次化Pooling操作,在图坍缩方面,与DiffPool的图坍缩机制不同的是,EigenPool方法进行图坍缩时不需要引入任何需要训练的参数【非参数化池化过程】,而是 采用如谱聚类的方式对图进行划分,然后再进行池化操作。谱聚类算法的思想是将图映射到特征空间后再使用聚类算法进行聚类(如Kmeans聚类算法),使得不同的簇之间的相连节点之间的权重尽可能大,而同一个簇之间的节点之间的权重尽可能小。在谱聚类中常用的聚类算法就是谱聚类,那么节点到簇的分配方式就是一种硬分配的方式,这样就保证了每一个节点只能分配的下一层的一个簇中,从而保证了网络连接的稀疏性,大大降低了参数量和计算开销。
② 此外,DiffPool在池化时,采样加和的方式聚合节点特征,这一定程度上丢失了每个簇的结构信息。为了解决结构信息丢失的问题,EigenPool使用谱图理论的知识来整合子图的结构信息和属性信息。使用谱聚类的方式划分子图,池化时也使用图的傅里叶变换将图信号映射到谱空间,从而使得池化过程兼顾各个簇内的结构和属性信息。
(2)基于重要性的池化
- Core:通过重要性排序的方法来取舍,即计算每个节点的重要性并保留排名靠前的一部分节点。(比较经典的有SAGPool【ICML2019】、TopK-Pooling【ICML 2019】)
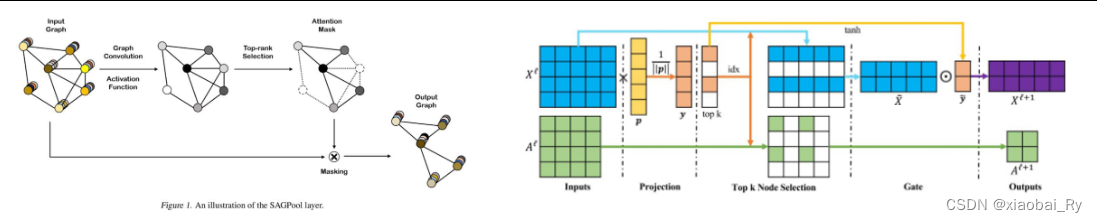
- 缺点:被保留的节点与丢弃节点之间的区别小,不利于显著性区域的识别;对于不同受试者,各节点之间的重要性可能不同,不利于找到群体水平的统一显著区域
- 亮点:(1)提出了一个端到端可识别显著性ROI区域的图神经网络Pooling Regularized-GNN(PR-GNN)【node conv + node pooling + readout】
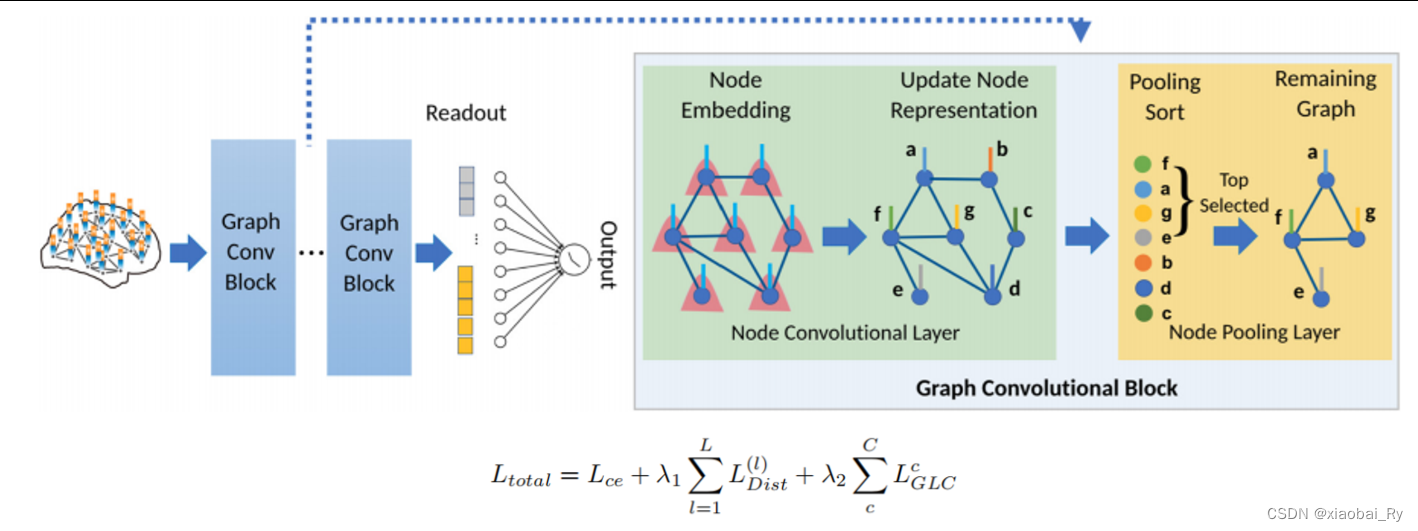 (2)最主要的核心要点感觉还是在其正则化,即PR-GNN对Pooling的限制所提出的两个Loss
(2)最主要的核心要点感觉还是在其正则化,即PR-GNN对Pooling的限制所提出的两个Loss
核心内容:(1)Node Pooling
PR-GNN基于重要性池化的方法加以相对限制,主要是基于SAGE Pooling 和 TopK Pooling方法的改进(即采用Distance Loss和Group-Level Consistency Loss加以限制)。
 (2)Distance Loss【用来加强被保留/丢弃节点之间的差异,便于显著性区域的识别】
(2)Distance Loss【用来加强被保留/丢弃节点之间的差异,便于显著性区域的识别】
采用MMD loss或BCE loss
 (3)Group-Level Consistency Loss【用来拉近同类受试者(如ASD患者与ASD患者,HC受试者与HC受试者)之间节点的重要性排序的相似性】
(3)Group-Level Consistency Loss【用来拉近同类受试者(如ASD患者与ASD患者,HC受试者与HC受试者)之间节点的重要性排序的相似性】

实验结果:
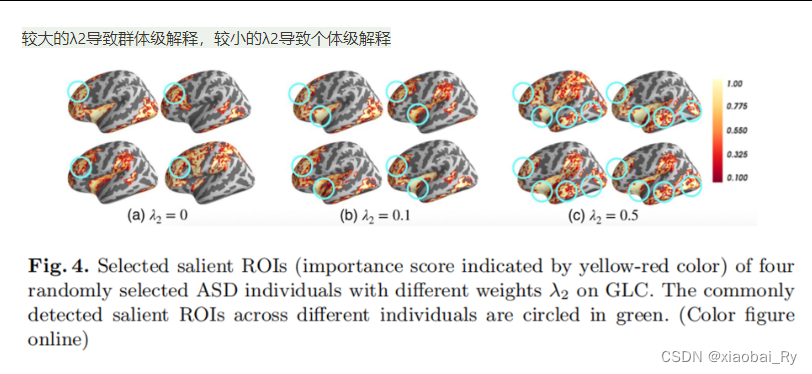
λ1鼓励在合并后为选定和未选定的节点提供更多可分离的节点重要性分数;
λ2控制同一类内实例的所选节点的相似性。
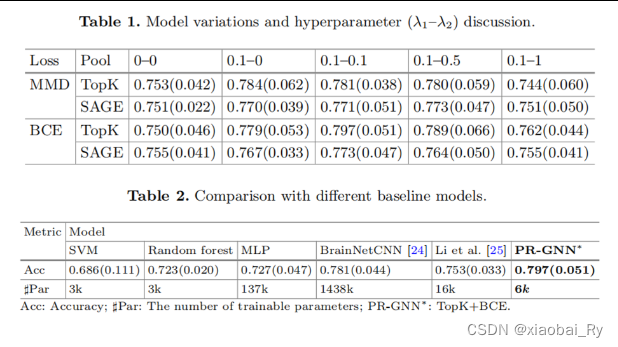
较大的λ2导致群体级解释,较小的λ2导致个体级解释
下一篇章笔记链接
下面笔记链接:
从池化的角度看GNN(包含PR-GNN,EdgePool等7篇论文)中篇笔记
链接:【笔记链接】
包括:
- 论文EdgePool:《Edge Contraction Pooling for Graph Neural Networks》
- 论文HaarPooling:《Haar Graph Pooling》
- 论文GSAPool:《Structure-Feature based Graph Self-adaptive Pooling》
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!