Group k-fold解释和代码实现
发布时间:2024年01月01日
Group k-fold解释和代码实现
一、Group k-fold解释和代码实现是什么?
0,1,2,3:每一行表示测试集和训练集的划分的一种方式。
class:表示类别的个数(下图显示的是3类),有些交叉验证根据类别的比例划分测试集和训练集(例三)。
group:表示从不同的组采集到的样本,颜色的个数表示组的个数(有些时候我们关注在一组特定组上训练的模型是否能很好地泛化到看不见的组)。举个例子(解释“组”的意思):我们有10个人,我们想要希望训练集上所用的数据来自(1,2,3,4,5,6,7,8),测试集上的数据来自(9,10),也就是说我们不希望测试集上的数据和训练集上的数据来自同一个人(如果来自同一个人的话,训练集上的信息泄漏到测试集上了,模型的泛化性能会降低,测试结果会偏好)。
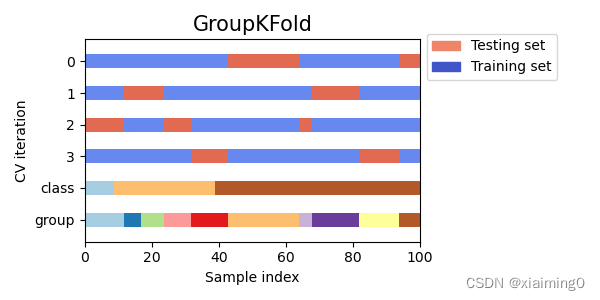
二、 实验数据设置
2.1 实验数据生成代码
X, y = np.arange(0,60).reshape((30,2)), np.hstack(([0] * 3, [1] * 9, [2] * 18))
groups = np.hstack((["a"] * 3, ["b"] * 1,["c"] * 2, ["d"] * 4,["e"] * 5, ["f"] * 3,["g"] * 4,["h"] * 5, ["i"] * 3))
print("数据:", end=" ")
for l in X:
print(l, end=' ')
print("")
print("标签:", y)
print("组别:", groups)
2.2 代码结果
数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59]
标签: [0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
组别: ['a' 'a' 'a' 'b' 'c' 'c' 'd' 'd' 'd' 'd' 'e' 'e' 'e' 'e' 'e' 'f' 'f' 'f' 'g' 'g' 'g' 'g' 'h' 'h' 'h' 'h' 'h' 'i' 'i' 'i']
数据个数、标签个数:30个
类别个数:3个(分别是0,1,2,比例是0.1:0.3:0.6和class每类对应)(和类别无关)
组别(group):9个(分别是a-i,个数是3,1,2,4,5,3,4,5,3)
三、实验代码
3.1 实验代码
代码如下:
# Group k-fold
import numpy as np
from sklearn.model_selection import GroupKFold
# X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
# y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
# groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
X, y = np.arange(0,60).reshape((30,2)), np.hstack(([0] * 3, [1] * 9, [2] * 18))
groups = np.hstack((["a"] * 3, ["b"] * 1,["c"] * 2, ["d"] * 4,["e"] * 5, ["f"] * 3,["g"] * 4,["h"] * 5, ["i"] * 3))
print("数据:", end=" ")
for l in X:
print(l, end=' ')
print("")
print("标签:", y)
print("组别:", groups)
gkf = GroupKFold(n_splits=3)
for i,(train, test) in enumerate(gkf.split(X, y, groups=groups)):
print("=================Group k-fold 第%d折叠 ===================="% (i+1))
# print('train - {}'.format(np.bincount(y[train])))
print(" 训练集索引:%s" % train)
print(" 训练集标签:", y[train])
print(" 训练集组别标签", groups[train])
print(" 训练集数据:", end=" ")
for l in X[train]:
print(l, end=' ')
print("")
# print(" 训练集数据:", X[train])
# print("test - {}".format(np.bincount(y[test])))
print(" 测试集索引:%s" % test)
print(" 测试集标签:", y[test])
print(" 测试集组别标签", groups[test])
print(" 测试集数据:", end=" ")
for l in X[test]:
print(l, end=' ')
print("")
# print(" 测试集数据:", X[test])
print("=============================================================")
3.2 实验结果
结果如下:
数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59]
标签: [0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
组别: ['a' 'a' 'a' 'b' 'c' 'c' 'd' 'd' 'd' 'd' 'e' 'e' 'e' 'e' 'e' 'f' 'f' 'f'
'g' 'g' 'g' 'g' 'h' 'h' 'h' 'h' 'h' 'i' 'i' 'i']
=================Group k-fold 第1折叠 ====================
训练集索引:[ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21]
训练集标签: [1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
训练集组别标签 ['b' 'c' 'c' 'd' 'd' 'd' 'd' 'e' 'e' 'e' 'e' 'e' 'f' 'f' 'f' 'g' 'g' 'g'
'g']
训练集数据: [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43]
测试集索引:[ 0 1 2 22 23 24 25 26 27 28 29]
测试集标签: [0 0 0 2 2 2 2 2 2 2 2]
测试集组别标签 ['a' 'a' 'a' 'h' 'h' 'h' 'h' 'h' 'i' 'i' 'i']
测试集数据: [0 1] [2 3] [4 5] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59]
=============================================================
=================Group k-fold 第2折叠 ====================
训练集索引:[ 0 1 2 3 6 7 8 9 18 19 20 21 22 23 24 25 26 27 28 29]
训练集标签: [0 0 0 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2]
训练集组别标签 ['a' 'a' 'a' 'b' 'd' 'd' 'd' 'd' 'g' 'g' 'g' 'g' 'h' 'h' 'h' 'h' 'h' 'i'
'i' 'i']
训练集数据: [0 1] [2 3] [4 5] [6 7] [12 13] [14 15] [16 17] [18 19] [36 37] [38 39] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59]
测试集索引:[ 4 5 10 11 12 13 14 15 16 17]
测试集标签: [1 1 1 1 2 2 2 2 2 2]
测试集组别标签 ['c' 'c' 'e' 'e' 'e' 'e' 'e' 'f' 'f' 'f']
测试集数据: [8 9] [10 11] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35]
=============================================================
=================Group k-fold 第3折叠 ====================
训练集索引:[ 0 1 2 4 5 10 11 12 13 14 15 16 17 22 23 24 25 26 27 28 29]
训练集标签: [0 0 0 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
训练集组别标签 ['a' 'a' 'a' 'c' 'c' 'e' 'e' 'e' 'e' 'e' 'f' 'f' 'f' 'h' 'h' 'h' 'h' 'h'
'i' 'i' 'i']
训练集数据: [0 1] [2 3] [4 5] [8 9] [10 11] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59]
测试集索引:[ 3 6 7 8 9 18 19 20 21]
测试集标签: [1 1 1 1 1 2 2 2 2]
测试集组别标签 ['b' 'd' 'd' 'd' 'd' 'g' 'g' 'g' 'g']
测试集数据: [6 7] [12 13] [14 15] [16 17] [18 19] [36 37] [38 39] [40 41] [42 43]
=============================================================
进程已结束,退出代码 0
3.3 结果解释
可以看到测试集标签里面有0,但是训练集标签里没有0——这没办法做测试。
可以看到数据集的划分和组别和折叠数(3折)有关,但是和标签比例无关(这一点不科学)
=================Group k-fold 第1折叠 ====================
训练集索引:[ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21]
训练集标签: [1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
训练集组别标签 ['b' 'c' 'c' 'd' 'd' 'd' 'd' 'e' 'e' 'e' 'e' 'e' 'f' 'f' 'f' 'g' 'g' 'g' 'g']
训练集数据: [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43]
测试集索引:[ 0 1 2 22 23 24 25 26 27 28 29]
测试集标签: [0 0 0 2 2 2 2 2 2 2 2]
测试集组别标签 ['a' 'a' 'a' 'h' 'h' 'h' 'h' 'h' 'i' 'i' 'i']
测试集数据: [0 1] [2 3] [4 5] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59]
=============================================================
四、总结
Group k-fold:不考虑标签(class)和组(group)的影响。
- 有时候测试集包含某一类的全部标签,而训练集不包含该类的样本。也就是说没经过训练,就要测试(KFold 第1折叠)。
- 适用于每一组的数据类型都很全的时候。
文章来源:https://blog.csdn.net/xiaiming0/article/details/135329764
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 积水监测识别摄像机
- 2024年武汉中级职称申报材料有哪些?
- 如何使用固定公网地址访问多个本地Nginx服务搭建的网站
- JavaScript--明明白白Promise (Park One)
- 10|记忆:通过Memory记住客户上次买花时的对话细节
- Leetcode18-算术三元组的数目(2367)
- ?iOS实时查看App运行日志
- 【2024华数杯国际数学建模竞赛】问题A 光伏发电 完整代码+结果分析+论文框架(一)
- 移动硬盘打不开怎么办?没有比这更好的办法了
- 8 单链表---带表头节点