pytorch(三)反向传播
发布时间:2024年01月23日
文章目录
反向传播
- 前馈过程的目的是为了计算损失loss
- 反向传播的目的是为了更新权重w,这里权重的更新是使用随机梯度下降来更新的。
前馈过程
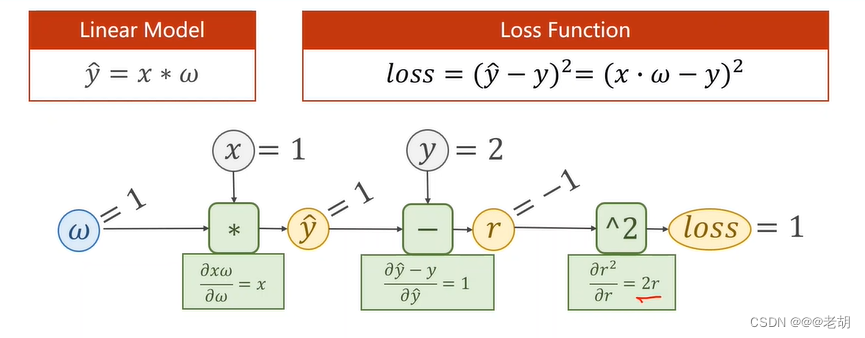
反馈过程
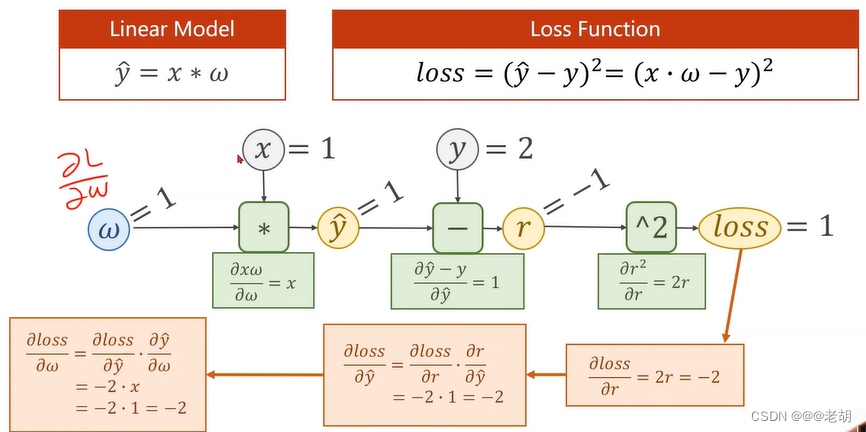
import torch
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=torch.Tensor([1.0])
# 表示需要计算梯度,默认不需要计算梯度
w.requires_grad=True
def forward(x):
return x*w # w是tensor类型,则运算会被重载成tensor之间的运算,x会被自动类型转换为tensor类型
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
print('predict before:',4,forward(4).item())
for epoch in range(100):
for x,y in zip(x_data,y_data):
# 前馈过程
l=loss(x,y)
# 反馈过程,会自动计算,存储在w中,完成存储后释放计算图
l.backward()
print('\tgrad:',x,y,w.grad.item())
# 权重更新,使用data标量,grad也是tensor
w.data=w.data=0.01*w.grad.data
# 权重中的梯度数据清零
w.grad.data.zero_()
print('progress:',epoch,l.item())
print('predict after:',4,forward(4).item())
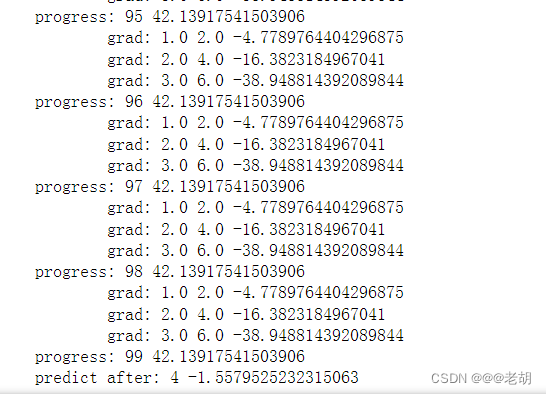
运行结果
在神经网路中,经常对线性的结果做一个非线性函数的变幻的展开,这就是激活函数。激活函数可以使得模型具有非线性。激活函数给神经元引入了非线性因素,神经网络就可以毕竟任意的非线性函数。如果不增加激活函数,模型展开之后还是线性模型,就还是只有一层。
tensor的广播机制
在tensor的使用过程中,我们经常需要对不同形状的tensor进行计算,这个时候就需要用到tensor的广播机制
tansor的广播机制就是在不同的rensor之间进行计算时,自动将数据进行扩展的一种方式。简单来说,就是当两个tensor的形状不同时,tensor会自动的将自己的形状扩展为另一个tensor的相同形状,然后进行计算。通常情况下,小一点的数组会被广播成大一点的数组,这样才能保持大小一致。
tensor的广播机制需要遵循以下规则:
- 每个tensor至少有一个维度
- 遍历tensor所有维度时,从末尾开始遍历(从右向左),两个tensor可能存在以下情况
- tensor维度相同
- tensor维度不同但是其中一个维度为1
- tensor维度不等且其中一个维度不存在
满足以上规则的tensor可以进行广播,维度扩展的过程就是将数值进行复制的过程。示例如下
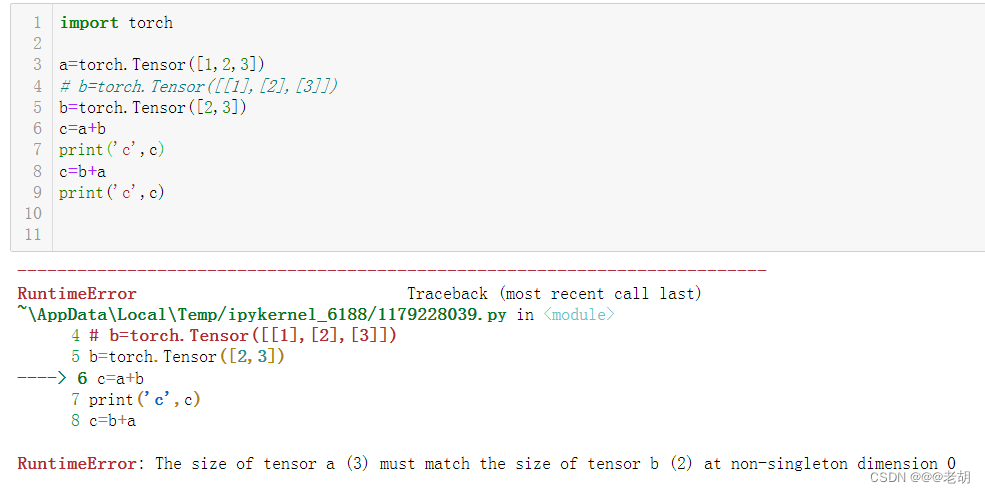
import torch
a=torch.Tensor([1,2,3])
b=torch.Tensor([[1],[2],[3]])
# b=torch.Tensor([2,3])
c=a+b
print('c',c)
c=b+a
print('c',c)
运行结果
c tensor([[2., 3., 4.],
[3., 4., 5.],
[4., 5., 6.]])
c tensor([[2., 3., 4.],
[3., 4., 5.],
[4., 5., 6.]])
有如下情况是不可以进行广播的:
- 参与运算的tensor维度不等但是其中没有一个的维度为1
- 参与运算的tensor其中一个没有任何维度,示例如下
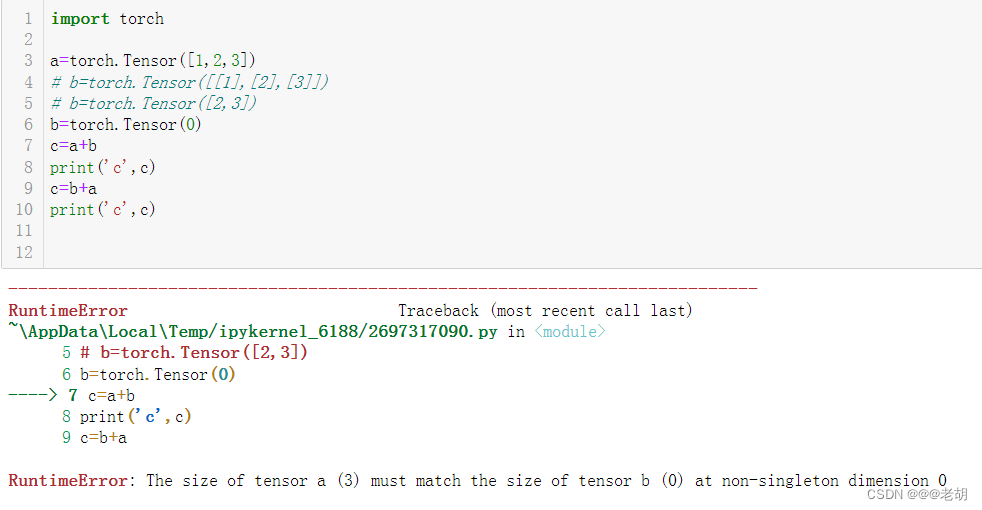
ps:这种广播机制并不是tensor独有的,numpy数组也可以广播,详情可以查看 numpy的广播机制
文章来源:https://blog.csdn.net/CodePlayMe/article/details/135749027
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于Java SSM框架实现健康管理系统项目【项目源码】计算机毕业设计
- 移动云电脑家庭版安装win11系统教程
- 科技顶天,市场立地 。璞华科技“顶天立地”的成长之路
- 代码随想录算法训练营第35天|860.柠檬水找零 406.根据身高重建队列 452. 用最少数量的箭引爆气球
- MyBatis原理–缓存机制
- Vue2+Vue3基础入门到实战项目(前接六 副线一)—— 面经 项目
- 是什么造就了伦敦银趋势?趋势交易的关键
- 数据结构 数组与字符串
- AI全栈大模型工程师(八)Plugins 开发
- 【沁恒蓝牙MESH】CH582单板无法正常启动