Stream流学习
Stream流学习笔记
背景简介
Java8更新之后提供了Stream流,为了让代码更加简洁,所以学习Stream流很有必要,本文为作者学习Stream流的笔记,仅此记录。
Sream操作
1、获取数据源
java.util.stream.Stream 是Java 8新加入的最常用的流接口。(这并不是一个函数式接口。)获取一个流非常简单,有以下几种常用的方式:所有的 Collection 集合都可以通过 stream 默认方法获取流;Stream 接口的静态方法 of 可以获取数组对应的流。
1.1、根据Collection获取流
Collection包含List和Set,两者获取流的方式相似。
List<String> list = new ArrayLise<>();
Stream<String> streamList = list.stream();
Set<String> set= new HashMap<>();
Stream<String> streamSet = set.stream();
1.2、根据Map获取流
java.util.Map不是Collection的接口 ,Map是包含<K,V>键值对的。所以要根据Key和Value分别获取Stream
Stream keyStream = map.keySet.Stream();
Stream valueStream = map.values.Stream();
Map<Map.Entry<String,String>> entryStream = map.entrySet.Stream();
1.3、根据数组获取流
String[] array = { "张三","张四" ,"王五"};
Strean<String> stream = stream.of(array);
Stream流命令分类
Stream操作大体上可以分为三类
- 创建Stream
- Stream中间处理
- 终止操作
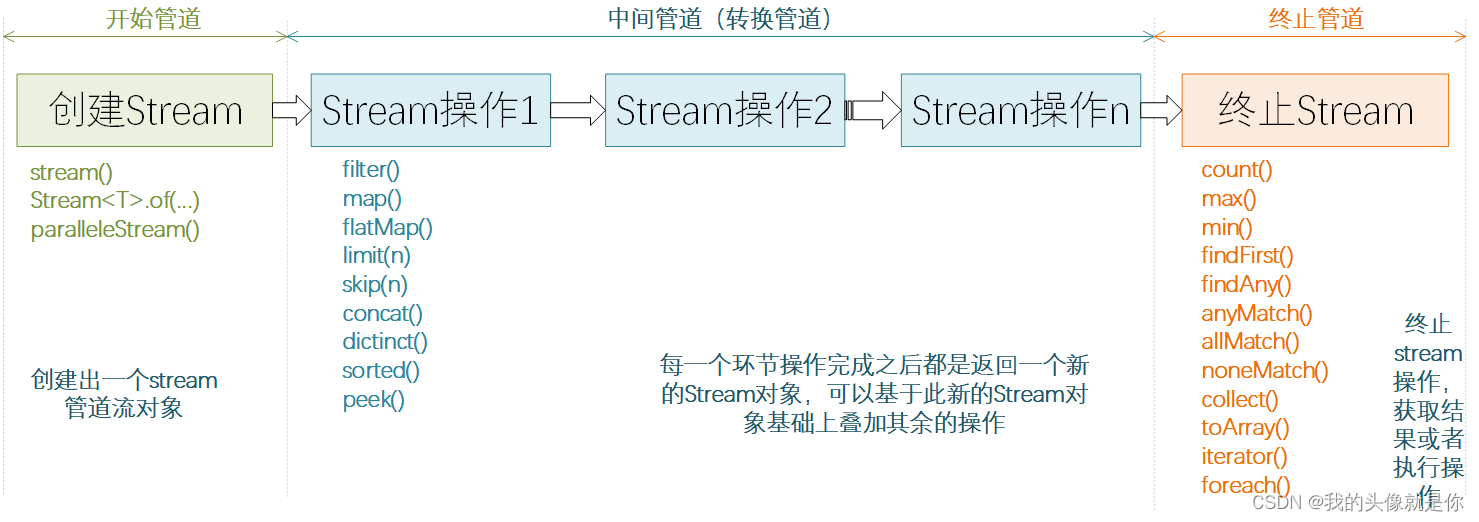
下面开始介绍各个方法的具体用法
方法简介
1、forEach:逐一处理
void forEach(Consumer<? super T> action);
该方法接受一个Consumer接口函数(说明该方法支持lambda函数或引用),将每一个流元素交给该函数处理,类似于遍历。
private static void forEachDemo(){
Stream<String> stream = Stream.of(array);
stream.forEach(s-> System.out.println(s));
}
输出结果:
张三
张四
王五
2、filter:过滤
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
Stream<String> stream = Stream.of(array);
stream.filter(s->s.startsWith("张"))
.forEach(System.out::println);
输出结果:
张三
张四
3、map:映射
该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
List<Integer> list = new ArrayList<Integer>(){{
add(1);
add(2);
add(3);
}};
list.stream().map(s->s.toString()).forEach(System.out::println);
输出结果:
1
2
3
当然,这个作用不仅是转换类型。
4、count:统计元素个数
count方法类似于Collection中的size方法一样,提供元素个数:
long count();
需要注意的是返回的是一个 long 类型的的返回值(而非int类型)。
public static final void countDemo(){
Stream<String> stream = Stream.of(array);
System.out.println(stream.count());
}
输出结果
3
5、limit:取用前几个
limit 方法可以对流进行截取,只取用前n个。
Stream<T> limit(long maxSize);
如果截取长度大于数组长度,则不进行操作
private static void limitDemo(){
Stream<String> stream = Stream.of(array);
Arrays.stream(array)
.limit(2)
.forEach(System.out::println);
}
输出结果:
张三
张四
6、skip:跳过前几个
跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
Stream<T> skip(long n);
需要注意的是:
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。
n必须大于等于0,如果大于当前流中的元素个数,则产生一个空流。
private static void skipDemo(){
Arrays.stream(array)
.skip(2)
.forEach(System.out::println);
}
输出结果:
王五
7、concat:组合
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
private static void concatDemo(){
Stream<String> stream1 = Stream.of("张三");
Stream<String> stream2 = Stream.of("李四");
Stream<String> stream = Stream.concat(stream1,stream2);
stream.forEach(System.out::println);
}
输出结果:
张三
李四
8、sorted:排序
Stream<T> sorted()
sorted 方法用于对流进行排序。
例子简单,待补充。
9、元素收集
Stream<T> sorted()
- 收集到List集合:
流对象.collect( Collectors.toList() )
获得List集合。
- 收集到Set集合:
流对象.collect( Collectors.toSet() )
获得Set集合。
- 收集到数组:
流对象. toArray()
由于泛型擦除的原因,返回值类型是Object[]
10、groupingBy:分组
groupingBy()方法是Collectors类中的静态方法
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream)
例子
//统计数组中出现单词个数
private static void groupingByDemo(){
List<String> items = Arrays.asList("apple", "apple", "banana", "apple", "orange", "banana", "papaya");
Map<String, Long> result = items.stream()
.collect(Collectors.groupingBy(
Function.identity(),Collectors.counting()
));
result.forEach((o1,o2)-> System.out.println(o1 + ":" + o2));
}
其中 Function.identity()可以替换为t->t,Collectors.counting()为统计流中出现次数。
输出结果:
papaya:1
orange:1
banana:2
apple:3
11、partitioningBy:分区
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate)
类似于分组,将符合条件的分为一组,不符合条件的分为一组。
private static void partitioningByDemo(){
System.out.println(Arrays.stream(array).collect(Collectors.partitioningBy(s -> s.startsWith("张"))));
}
输出结果:
{false=[王五], true=[张三, 张四]}
12、查找
allMatch(Predicate<? super T> predicate)
用于检测是否全部都满足指定的参数行为,如果全部满足则返回true
anyMatch(Predicate<? super T> predicate)
anyMatch则是检测是否存在一个或多个满足指定的参数行为,如果满足则返回true
noneMatch(Predicate<? super T> predicate)
oneMatch用于检测是否不存在满足指定行为的元素,如果不存在则返回true
findFirst()
findFirst用于返回满足条件的第一个元素
findAny()
findAny相对于findFirst的区别在于,findAny不一定返回第一个,而是返回任意一个
13、joining:字符串拼接
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter)
参数为连接符,返回值为一个集合。
private static void joinDemo(){
System.out.println(Arrays.stream(array).collect(Collectors.joining(",")));
}
输出结果:
张三,张四,王五
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 机器人中的数值优化之线性共轭梯度法
- 【开源】基于JAVA语言的教学过程管理系统
- 轻松搞定!微信快速导出好友数据备份
- 深度学习|4.7 参数和超参数
- 二叉树-堆
- MATLAB遗传算法工具箱的三种使用方法
- 题解:CF1920E. Counting Binary Strings
- 【什么是Docker ?】一篇博文让你明白什么是Docker,如何按照docker,docker核心命令
- 深入理解Java虚拟机---Java内存模型
- 数字传输系统