ChatGPT学习笔记——大模型基础理论体系
1、ChatGPT的背景与意义
近期,ChatGPT表现出了非常惊艳的语言理解、生成、知识推理能力, 它可以极好的理解用户意图,真正做到多轮沟通,并且回答内容完整、重点清晰、有概括、有条理。
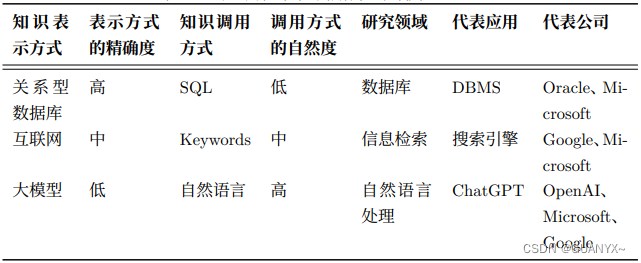
ChatGPT 是继数据库和搜索引擎之后的全新一代的 “知识表示和调用方式”如下表所示。
1.1 ChatGPT技术发展历程
从技术角度讲,ChatGPT 是一个聚焦于对话生成的大语言模型,其能够根据用户的文本描述,结合历史对话,产生相应的智能回复。其中 GPT是英文 Generative Pretrained Transformer 的缩写。OpenAI 认为符合人类预期的回复应该具有真实性、无害性和有用性。为了使生成的回复具有以上特征,OpenAI 在 2022 年初发表的工作“Training language models to follow instructions with human feedback”中提到引入人工反馈机制,并使用近端策略梯度算法(PPO)对大模型进行训练。这种基于人工反馈的训练模式能够很大程度上减小大模型生成回复与 人类回复之间的偏差,也使得 ChatGPT 具有良好的表现。
ChatGPT 核心技术主要包括其具有良好的自然语言生成能力的大模型 GPT-3.5 以及训练这 一模型的钥匙——基于人工反馈的强化学习(RLHF)。
除了参数上的增长变化之外,GPT 模型家族的发展从 GPT-3 开始分成了两个技术路径并行发展,一个路径是以 Codex 为代表的代码预训练技****术,另一个路径是以 InstructGPT 为代表的文本指令(Instruction)预训练技术。但这两个技术路径不是始终并行发展的,而是到了一定阶段后(具体时间不详)进入了融合式预训练的过程,并通过指令学习(InstructionTuning)、有监督精调(Supervised Fine-tuning)以及基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF)等技术实现了以自然语言对话为接口的 ChatGPT 模型。
其中RLHF 这一概念最早是在 2008 年 TAMER:Training an Agent Man?ually via Evaluative Reinforcement一文中被提及的。该文章中指出引入人类进行评价的主要目的是加快模型收敛速度,降低训练成本,优化收敛方向。具体实现上,人类标注人员扮演用户和代理进行对话,产生对话样本并对回复进行排名打分,将更好的结果反馈给模型,让模型从两种反馈模式——人类评价奖励和环境奖励中学习策略,对模型进行持续迭代式微调。
1.2 ChatGPT未来技术发展
(1)模型瘦身:目前主流的模型压缩方法有**量化、剪枝、蒸馏和稀疏化(权重矩阵分解、模型参数共享)**等。量化是指降低模型参数的数值表示精度,比如
从 FP32 降低到 FP16 或者 INT8。剪枝是指合理地利用策略删除神经网络中的部分参数,比如从单个权重到更高粒度组件如权重矩阵到通道,这种方法在视觉领域或其他较小语言模型中比较奏效。蒸馏是指利用一个较小的学生模型去学习较大的老师模型中的重要信息而摒弃一些冗余信息的方法。稀疏化将大量的冗余变量去除,简化模型的同时保留数据中最重要的信息。
(2)减少人类反馈信息的 RLAIF 也是最近被提出的一个全新的观点。2022 年 12 月 Anthropic 公司发表论文“Constitutional AI: Harmlessness from AI Feedback”该文章介绍 了其最新推出的聊天机器人 Claude,与 ChatGPT 类似的是两者均利用强化学习对模型进行训练,而不同点则在于其排序过程使用模型进行数据标注而非人类,即训练一个模型学习人类对于无害性偏好的打分模式并代替人类 对结果进行排序。
1.3 ChatGPT的优势和劣势
1.3.1 优势
相较于普通聊天机器人:(1)强大的底座能力:ChatGPT 基于 GPT-3.5 系列的 Code-davinci-002 指令微调而成。而 GPT-3.5 系列是一系列采用了数千亿的 tok
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- react中的setState是同步还是异步
- linux sudo指令提权
- 定义Threadlocal工具类使用拦截器统一释放资源
- ICC2:调整字体大小和图标尺寸
- 【精通C语言】:深入解析for循环,从基础到进阶应用
- js自定义滑块
- Discourse 未活动的用户是怎么处理的
- IT新人成长路线(2023图文版)
- 【nice-slam】基于RGB-D类型SLAM的定位与重建(史上最详细nice-slam资料汇总)
- MySQL 按日期流水号 条码 分布式流水号