【nice-slam】基于RGB-D类型SLAM的定位与重建(史上最详细nice-slam资料汇总)
1. 总结
NICE-SLAM一种结合了神经隐式表示和分层场景表示的密集RGB-D SLAM系统。该方法在保持神经隐式表示的表示能力的同时,通过引入分层场景表示来实现可扩展性和效率。具体来说,场景的几何和颜色信息由四个特征网格及其相应的解码器联合编码,这些网格在不同的空间分辨率上进行优化。在测试时,通过最小化重新渲染的损失,只优化当前视锥体内的特征,从而实现高效的局部更新。并在多个具有挑战性的数据集上进行了方法评估,结果表明NICE-SLAM在重建效果好和跟踪质量高。
2. 论文
相机跟踪和地图构建是NICE-SLAM算法的两个主要步骤。以下是这两个步骤的详细过程和对应的数学推导:
2. 1 算法核心流程小姐
-
相机跟踪:
相机跟踪的目标是估计当前帧的相机位姿。假设我们有一系列的历史关键帧{K1, K2, …, Kt},以及当前帧It的深度图Dt和相机内参矩阵Kc。我们可以用一个优化问题来描述相机跟踪的过程:
min R,t ∑m=1:M L(Dm, ?Dm)
其中,R和t是相机的旋转和平移矩阵,Dm是第m个关键帧的深度图,?Dm是通过当前帧的相机位姿投影到第m个关键帧的深度图。L(·)是一个光度误差损失函数,常用的有平方损失或者Huber损失。
为了求解这个优化问题,NICE-SLAM使用了Levenberg-Marquardt算法。这个算法是一种非线性最小二乘优化算法,它结合了梯度下降和牛顿法的优点,能够在保证收敛速度的同时,对初始值和噪声具有较好的鲁棒性。
-
地图构建:
地图构建的目标是优化场景的几何表示。假设我们选择了K个关键帧 K 1 , K 2 , . . . , K t {K1, K2, ..., Kt} K1,K2,...,Kt,以及对应的深度图 D 1 , D 2 , . . . , D t {D1, D2, ..., Dt} D1,D2,...,Dt和相机位姿 R 1 , R 2 , . . . , R t , t {R1, R2, ..., Rt, t} R1,R2,...,Rt,t。我们可以用一个优化问题来描述地图构建的过程:
m i n θ , R i , t i ∑ i = 1 : K ( L p i + L g i ) min θ,Ri,ti ∑i=1:K (Lpi + Lgi) minθ,Ri,ti∑i=1:K(Lpi+Lgi)
其中,θ是特征网格的参数,Ri和ti是第i个关键帧的相机位姿。Lpi是光度误差,Lgi是几何误差。这两个误差的定义如下:
L p i = ∑ m = 1 : M w p i , m L p , m Lpi = ∑m=1:M wpi,m Lp,m Lpi=∑m=1:Mwpi,mLp,m
L g i = ∑ m = 1 : M w g i , m L g , m Lgi = ∑m=1:M wgi,m Lg,m Lgi=∑m=1:Mwgi,mLg,m
其中,M是采样的像素点数量, w p i , m wpi,m wpi,m和 w g i , m wgi,m wgi,m是权重, L p , m Lp,m Lp,m和 L g , m Lg,m Lg,m分别是第 m m m个像素点的光度误差和几何误差。
为了求解这个优化问题,NICE-SLAM使用了一种交替优化策略。具体来说,它首先固定特征网格的参数θ,然后优化关键帧的相机位姿{Ri, ti}。这一步可以通过求解一个非线性最小二乘问题来完成。然后,它固定相机位姿,优化特征网格的参数θ。这一步可以通过梯度下降来完成。这个过程会迭代进行,直到收敛。
提出了NICE-SLAM,这是一个结合神经隐式解码器和分层网格表示的密集RGB-D SLAM系统,可应用于大型场景。
2.2 论文摘要
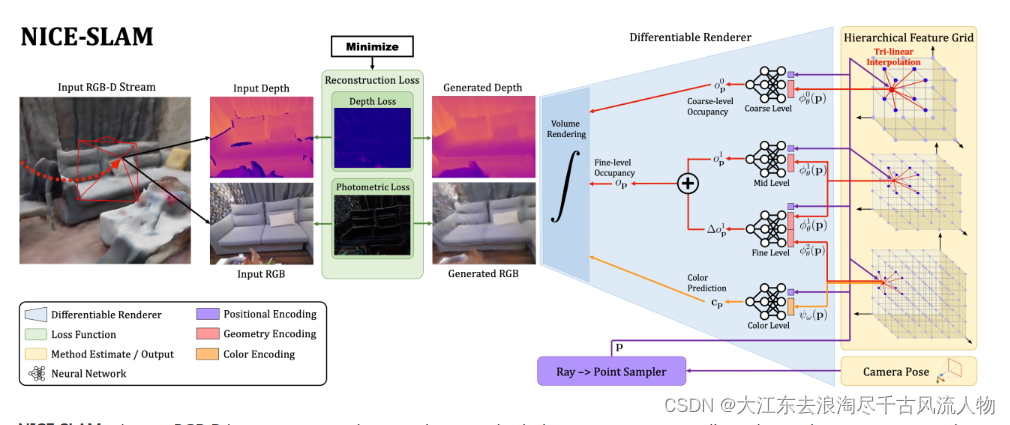
图2
神经隐式表示最近在各个领域显示出了令人鼓舞的结果,包括在同时定位和地图构建(SLAM)方面取得了令人期待的进展。然而,现有方法产生了过于平滑的场景重建,并且难以扩展到大型场景。这些局限主要是由于它们简单的全连接网络架构,没有结合观测中的局部信息。在本文中,我们提出了NICE-SLAM,这是一个密集的SLAM系统,通过引入分层场景表示,结合了多级局部信息。通过利用预训练的几何先验优化这种表示,能够对大型室内场景进行详细重建。与最近的神经隐式SLAM系统相比,我们的方法更具可扩展性、效率和鲁棒性。对五个具有挑战性的数据集进行的实验表明,NICE-SLAM在地图构建和跟踪质量上具有竞争力的结果。
2.3 Dataset result
2.3.1 Replica Dataset result
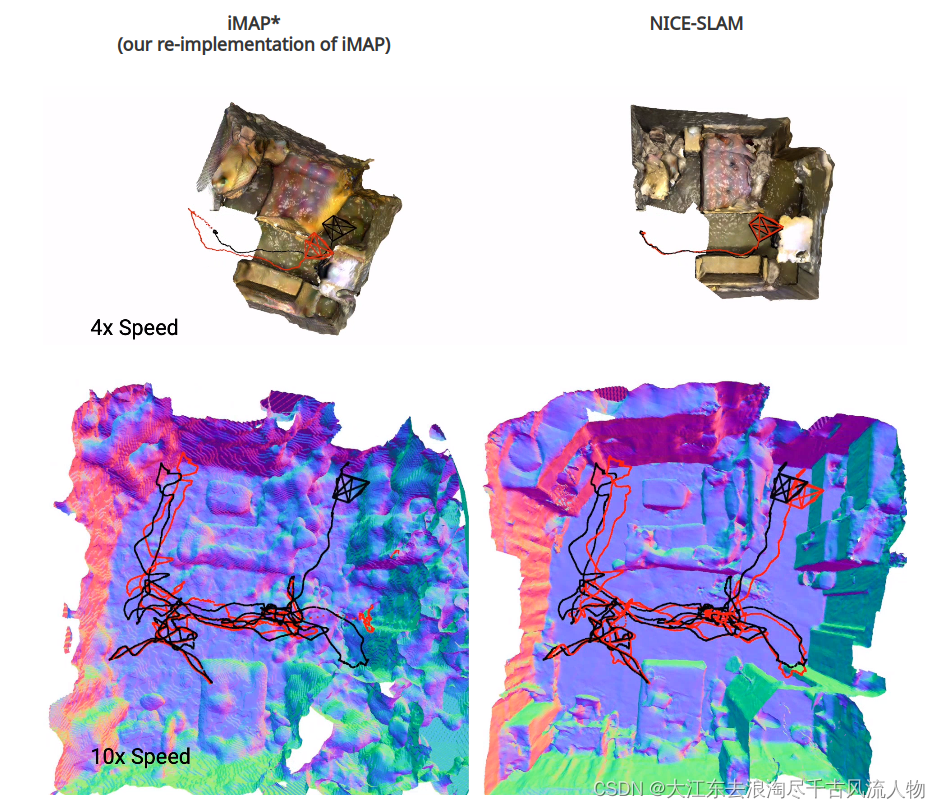
2.3.2 ScanNet Dataset result
As can be observed, our NICE-SLAM produces sharper and cleaner geometry. Also, unlike the global update as shown in iMAP, our system can update locally thanks to the grid-based hierarchical representation.
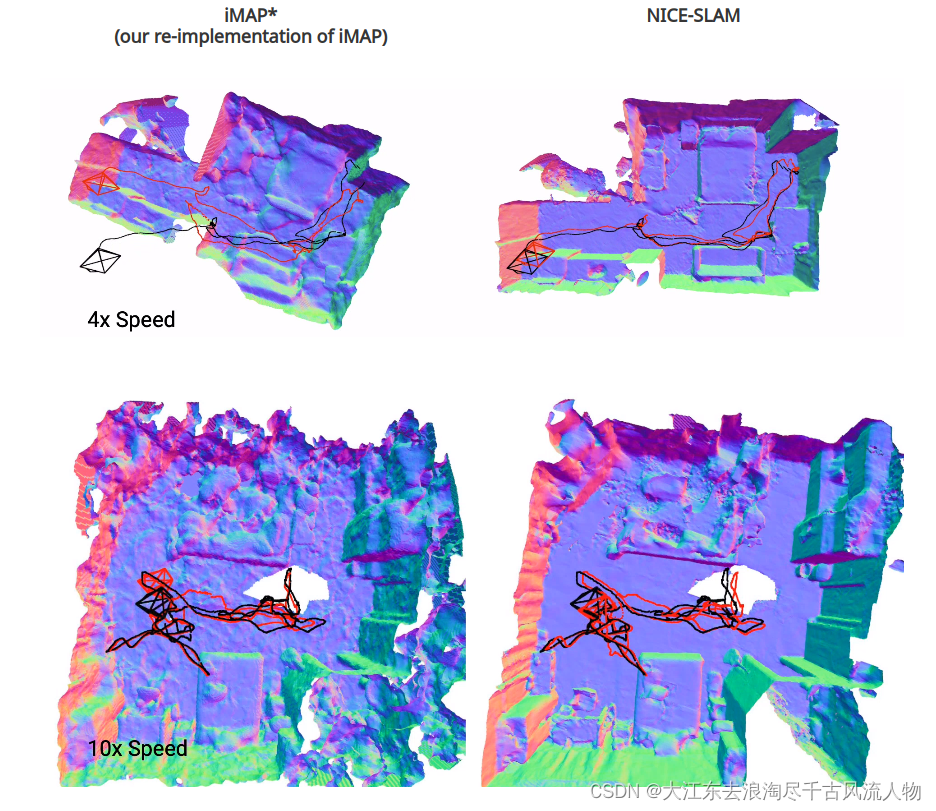
2.3.3 Multi-room Apartment result
To further evaluate the scalability of our method we capture a sequence in a large apartment with multiple rooms.

2.3.4 Co-fusion Dataset (Robustness to Dynamic Objects) result
NICE-SLAM is able to handle dynamic objects . Note that the airship and toy car is not wrongly reconstructed.
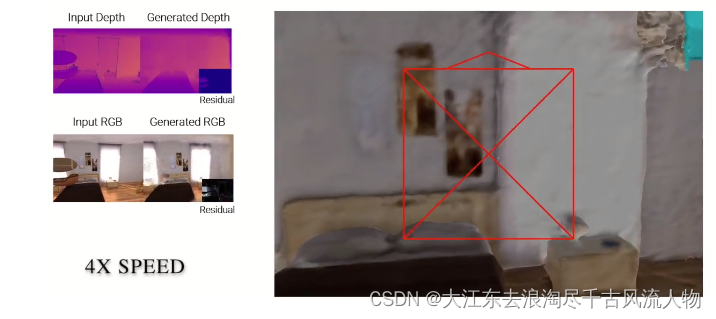
2.3.5 Robustness to Frame Loss?
Here, we simulate large frame lost. The video show current tracking camera pose as well as rendered images for each tracking iteration. The ground truth camera is shown in black, the current tracking camera is shown in red. We can notice that NICE-SLAM is able to fast recover the camera pose thanks to the prediction from the coarse-level (shown in cyan).
一句话:跟踪实时且准确

这里机几组数据对比之下可以显示出这个模型的有点:
尺度准确性比较高;隐士表示,局部优化效果比较干净,平滑,低噪点;可以很好的处理手持动态数据场景;跟踪实时且准确
3. 论文翻译
3.1.摘要:见 1. 总结
3.2. 引言
稠密视觉SLAM是3D计算机视觉的一个基础问题,在自动驾驶、室内机器人、混合现实等领域有着广泛的应用。为了使SLAM系统在实际应用程序中真正有用,以下属性是必不可少的。首先,我们希望SLAM系统能够是实时的。接下来,该系统应该有能力对没有观测的区域做出合理的预测。此外,该系统应该能够扩展到大型场景。最后,对有噪声或观测缺失的情况具有鲁棒性是至关重要的。
在实时稠密视觉SLAM系统的范围内,近几年RGB-D相机已经引入了许多方法。传统的稠密视觉SLAM系统满足实时需求,可以用于大规模场景,但他们无法对未观测到的区域做出合理的几何估计。另一方面,基于学习的SLAM方法获得一定水平的预测能力,因为它们通常在特定任务的数据集上进行训练。此外,基于学习的方法往往能更好地处理噪声和异常值。然而,这些方法通常只在具有多个对象的小场景中工作。最近,Sucar等人在实时稠密SLAM系统(称为iMAP)中应用了神经隐式表示(neural implicit representation),他们对房间大小的数据集显示了良好的跟踪和建图结果。然而,当扩展到更大的场景时,例如,一个由多个房间组成的公寓,在稠密重建和相机跟踪精度方面都可以观察到显著的性能下降。
iMAP的关键限制因素源于它使用了一个单一的多层感知器(MLP)来表示整个场景,它只能随着每一个新的、潜在的部分场景而进行全局更新RGB-D观测。相比之下,最近的工作证明,建立基于多级网格特征可以帮助保存几何细节和重建复杂的场景,但这些都是没有实时功能的离线方法。
在这项工作中,我们试图结合分层场景表征(hierarchical scene representation)和神经隐式表征(neural implicit representation)的优势,以完成稠密RGB-D SLAM的任务。为此,我们引入了NICE-SLAM,这是一种稠密的RGB-D SLAM系统,可以应用于大规模场景,同时保持预测能力。我们的关键思想是用层次特征网格来表示场景的几何形状和外观,并结合在不同空间分辨率下预训练的神经隐式解码器的归纳偏差(inductive biases)。通过从占用率和彩色解码器输出中得到的渲染后的深度和彩色图像,我们可以通过最小化重渲染损失(re-rendering losses),只在可视范围内优化特征网格。我们对各种室内RGB-D序列进行了广泛的评估,并证明了我们的方法的可扩展性和预测能力。总的来说,我们做出了以下贡献:
我们提出了NICE-SLAM,一个稠密的RGB-DSLAM系统,对于各种具有挑战性的场景具有实时能力、可扩展性、可预测性以及鲁棒性。
NICE-SLAM的核心是一个层次化的、基于网格的神经隐式编码。与全局神经场景编码相比,这种表示允许局部更新,这是针对大规模方法的先决条件。
我们对各种数据集进行了广泛的评估,从而证明了在建图和跟踪方面的竞争性能。
3.3 相关工作
稠密视觉SLAM。大多数现代的视觉SLAM方法都遵循了Klein等人的开创性工作中引入的整体架构,将任务分解为建图和跟踪。地图表示通常可以分为两类:以视图为中心(view-centric)和以世界为中心(world-centric)。第一个是将三维几何图形锚定到特定的关键帧上,通常在密集的设置中表示为深度图。这类产品早期的例子之一是DTAM。由于其简单性,DTAM已被广泛应用于最近许多基于学习的SLAM系统。例如,DeepV2D在回归深度和姿态估计之间交替,但使用了测试时间优化。BA-Net和DeepFactor通过使用一组基础深度图简化了优化问题。还有一些方法,如CodeSLAM、Scene和NodeSLAM,它们可以优化一个可解码成关键帧或对象深度图的潜在表示。Droid-SLAM使用回归光流来定义几何残差进行细化。TANDEM结合了多视图立体几何和DSO的实时稠密SLAM系统。另一方面,以世界为中心的地图表示将三维几何图形固定在统一的世界坐标中,可以进一步划分为表面(surfels)和体素网格(voxel grids),通常存储占用概率或TSDF值。体素网格已广泛应用于RGB-D SLAM,例如Kinect-Fusion。在我们提出的管道中,我们也采用了体素网格表示。与以前的SLAM方法相比,我们存储几何的隐式潜在编码,并在建图过程中直接优化它们。这种更丰富的表示方式允许我们在较低的网格分辨率下实现更精确的几何图形。
神经隐式表示。最近,神经隐式表示在对象几何表示、场景补全、新视图合成还有生成模型方面显示出了很好的结果。最近的几篇论文试图用RGB-(D)输入来预测场景级的几何形状,但它们都假设了给定的相机姿态。另一组工作解决了相机姿态优化的问题,但它们需要一个相当长的优化过程,这并不适合实时应用。与我们的方法最相关的工作是iMAP。给定一个RGB-D序列,他们引入了一个实时稠密SLAM系统,该系统使用一个单一的多层感知器(MLP)来紧凑地表示完整的场景。然而,由于单个MLP多层感知机模型容量有限,iMAP不能产生详细的场景几何形状和精确的摄像机跟踪,特别是对于较大的场景。相比之下,我们提供了一个类似于iMAP的可扩展的解决方案,它结合了可学习的潜在嵌入和一个预先训练的连续隐式解码器。通过这种方式,我们的方法可以重建复杂的几何形状和为更大的室内场景预测详细的纹理,同时保持更少的计算和更快的收敛。值得注意的是,[17,38]还将传统的网格结构与学习到的特征表示结合起来,以实现可扩展性,但它们都不是实时的。此外,DI-Fusion也优化了给定RGB-D序列的特征网格,但它们的重建通常包含孔洞,它们的相机跟踪对纯表面渲染损失没有鲁棒性。
3.4 具体方法
我们在图2中概述了我们的方法。以RGB-D图像流作为输入,并输出相机姿态和学习到的分层特征网格形式的场景表示。从右到左的pipeline可解释为一个生成模型,它从给定的场景表示和相机姿态中呈现深度和彩色图像。在测试时,通过可微渲染器(从左到右)我们通过反向传播图像和深度重建损失来求解反问题来估计场景表示和相机姿态。这两个实体都是在一个交替的优化过程中进行估计的:建图:反向传播仅更新层次场景表示;跟踪:反向传播仅更新摄像机姿态。为了更好的可读性,我们将相同大小的颜色网格加入了几何编码的精细网格,并将它们显示为具有两个属性(红色和橙色)的一个网格。
使用四个特征网格及其相应的解码器来表示场景的几何形状和外观。我们使用估计的相机标定来跟踪每个像素的视射线。通过沿着视射线进行采样点并查询网络,我们可以渲染该射线的深度和颜色值。对于选择的关键帧,通过最小化深度和颜色损失,我们能够以交替的方式,同时优化相机位姿和场景几何。
3.4.1 Hierarchical Scene Representation 分层场景表示
我们现在介绍我们的分层场景表示,它将多层次的网格特征与预训练的解码器结合起来,用于占据预测。几何形状被编码成三个特征网格 ? θ l ?^l_θ ?θl?以及它们对应的MLP解码器 f l f ^l fl,其中 l ∈ 0 , 1 , 2 l∈{0, 1, 2} l∈0,1,2表示粗细级别场景细节。此外,我们还有一个单独的特征网格 ψ ω ψ_ω ψω?和解码器 g ω g_ω gω?用于建模场景外观。这里θ和ω表示几何和颜色的可优化参数,即网格中的特征和颜色解码器中的权重。
中-和细级别几何表示。观察到的场景几何被表示为中和细级别特征网格。在重建过程中,我们使用这两个网格采用粗到细的方法,首先通过优化中级特征网格来重建几何形状,然后通过细级别进行细化。在实现中,我们使用侧长度分别为32cm和16cm的体素网格,除了TUM RGB-D[46]我们使用16cm和8cm。对于中级别,特征直接解码为占据值,使用相关的MLP
f
1
f^1
f1,对于任意点
p
∈
R
3
p∈R^3
p∈R3,我们得到占据为
o
p
1
=
f
1
(
p
,
?
θ
1
(
p
)
)
o_p ^1 = f^1(p , \phi ^1_\theta (p))
op1?=f1(p,?θ1?(p)) (1),其中?1θ§表示特征网格在点p上进行三线性插值。相对较低的分辨率使我们能够高效地优化网格特征以适应观察结果。为了捕获高频场景几何的细节,我们以一种残差方式添加了细级特征。特别地,细级特征解码器以中级特征和细级特征作为输入,并输出相对于中级占据的偏移,即
Δ
o
p
1
=
f
2
(
p
,
?
θ
1
(
p
)
,
?
θ
2
(
p
)
)
\Delta o_p ^1 = f^2(p , \phi ^1_\theta (p), \phi ^2_\theta (p))
Δop1?=f2(p,?θ1?(p),?θ2?(p)) (2)
其中点的最终占据由
o
p
=
o
p
1
+
Δ
o
p
1
o_p = o_p ^1 + \Delta o_p ^1
op?=op1?+Δop1? (3)
给出。需要注意的是,我们固定预训练的解码器f1和f2,仅在整个优化过程中优化特征网格
?
θ
1
?^1_θ
?θ1?和
?
θ
2
?^2_θ
?θ2?。我们证明这有助于稳定优化并学习一致的几何形状。
**粗级别几何表示。**粗级别特征网格旨在捕捉场景的高级几何(如墙壁、地板等),并独立于中和细级别优化。粗网格的目标是能够预测观察到的几何之外的大致占据值,即使每个粗体素只被部分观察到。出于这个原因,我们在实现中使用非常低的分辨率,侧长为2m。与中级网格类似,我们通过对特征进行插值并通过MLP f0直接解码为占据值,即 o p 0 = f 0 ( p , ? θ 0 ( p ) ) o_p ^0 = f^0(p , \phi ^0_\theta (p)) op0?=f0(p,?θ0?(p)) (4)
3.4.2 Depth and Color Rendering
在追踪过程中,粗级别的占据值仅用于预测之前未观察到的场景部分。这种预测的几何形状允许我们在当前图像的大部分区域之前未见的情况下进行追踪。
**预训练特征解码器。**在我们的框架中,我们使用三个不同的固定MLP来将网格特征解码为占据值。粗级别和中级别解码器作为ConvONet [38]的一部分进行预训练,其中包括CNN编码器和MLP解码器。我们使用二元交叉熵损失来训练编码器/解码器,即预测值与地面实况值之间的损失。训练后,我们仅使用解码器MLP,因为我们将直接优化特征以适应重建流程中的观察值。通过这种方式,预训练的解码器可以利用从训练集中学到的分辨率特定先验知识进行解码。对于细级别解码器,我们使用相同的策略进行预训练,只是我们在输入到解码器之前简单地将特征 ? θ 1 ( p ) ?^1_θ(p) ?θ1?(p)从中级别和细级别特征 ? θ 2 ( p ) ?^2_θ(p) ?θ2?(p)进行连接。
**颜色表示。**尽管我们主要关注场景的几何形状,但我们也编码颜色信息,这使我们能够渲染RGB图像,从而为追踪提供额外的信号。为了编码场景中的颜色,我们应用另一个特征网格
ψ
ω
ψ_ω
ψω?和解码器
g
ω
:
c
p
=
g
ω
(
p
,
ψ
ω
(
p
)
)
gω:c_p = g_\omega (p , \psi_\omega (p))
gω:cp?=gω?(p,ψω?(p)) (5),
其中
ω
ω
ω表示在优化过程中可学习的参数。与具有强先验知识的几何形状不同,我们经验上发现,联合优化颜色特征
ψ
ω
ψ_ω
ψω?和解码器
g
ω
g_ω
gω?可以提升追踪性能。需要注意的是,类似于iMAP [47],这可能导致遗忘问题,并且颜色在局部区域上是一致的。如果我们想要可视化整个场景的颜色,可以将其作为后处理步骤进行全局优化。
网络设计。对于所有MLP解码器,我们使用32个隐藏特征维度和5个全连接块。除了粗级别的几何表示之外,我们在输入到MLP解码器之前应用可学习的高斯位置编码[47, 50] p。我们观察到这可以发现几何和外观的高频细节。
3.4.3 Mapping and Tracking
在这一部分,我们提供了关于我们分层场景表示的几何形状 θ θ θ和外观 ω ω ω参数,以及相机姿态的优化的详细信息。
建图。为了优化第3.4.1节中提到的场景表示,我们从当前帧和选定的关键帧中均匀采样M个像素。然后,我们通过分阶段的方式进行优化,以最小化几何和光度损失。
几何损失函数
L g l = 1 M ∑ m = 1 M ∣ D m ? D ^ m l ∣ , l ∈ { c , f } L _{g}^{l} = \frac {1}{M}\sum _{m=1}^M {\left |D_m - \hat {D}^l_m\right |},\quad l\in \{c, f\} Lgl?=M1?m=1∑M? ?Dm??D^ml? ?,l∈{c,f}(8)
光度损失函数
L p = 1 M ∑ m = 1 M ∣ I m ? I ^ m ∣ ? . L _p = \frac {1}{M}\sum _{m=1}^M\left |I_m - \hat {I}_m\right |~. Lp?=M1?m=1∑M? ?Im??I^m? ??.(9)
在第一阶段,我们仅通过几何损失 L g f L^f_g Lgf?在Eq. (8)中优化中级特征网格 ? θ 1 ?^1_θ ?θ1?。接下来,我们同时优化中级和细级 ? θ 1 , ? θ 2 ?^1_θ,?^2_θ ?θ1?,?θ2?特征,并使用相同的细级深度损失 L g f L^f_g Lgf?。最后,我们进行局部包裹调整(BA),以同时优化所有级别的特征网格、颜色解码器以及K个选定关键帧的相机外部参数 R i , t i {R_i, t_i} Ri?,ti?。
多阶段优化方案可以更好地收敛,因为更高分辨率的外观和细节特征可以依赖于来自中级特征网格的已经完善的几何形状。
请注意, 系统将并行化为三个线程以加速优化过程:一个线程用于粗级别映射,一个用于中和细级几何和颜色优化,另一个用于相机追踪。
相机追踪。除了优化场景表示,我们还并行运行相机追踪,以优化当前帧的相机姿态,即旋转和平移 R , t {R, t} R,t。为此,我们在当前帧中采样 M t M_t Mt?个像素,并应用Eq. (9)中相同的光度损失,但使用修改后的几何损失
L g _ v a r = 1 M t ∑ m = 1 M t ∣ D m ? D ^ m c ∣ D ^ v a r c + ∣ D m ? D ^ m f ∣ D ^ v a r f . L _{g\_var} = \frac {1}{M_t}\sum _{m=1}^{M_t} \frac {\left |D_m - \hat {D}^c_m\right |}{\sqrt {\hat {D}^c_{var}}} + \frac {\left |D_m - \hat {D}^f_m\right |}{\sqrt {\hat {D}^f_{var}}}. Lg_var?=Mt?1?m=1∑Mt??D^varc?? ?Dm??D^mc? ??+D^varf?? ?Dm??D^mf? ??. (11)
修改后的损失减低了在重建几何形状中不确定性较大区域的权重。相机追踪最终被 formulated 为以下的最小化问题
min ? R , t ? ( L g _ v a r + λ p t L p ) ? . \min \limits _{R , t } ~(L _{g\_var} + \lambda _{pt} L _p)~. R,tmin??(Lg_var?+λpt?Lp?)?.(12)
粗特征网格能够对场景几何进行短程预测。当相机移动到以前未观察到的区域时,这种外推的几何形状为跟踪提供了有意义的信号,使其更加健壮,可以更容易应对突然帧丢失或快速相机移动。
我们在附加材料中提供了实验。
对动态对象的鲁棒性。为了使优化在跟踪过程中对动态对象变得更加健壮,我们会过滤掉具有大深度/颜色重新渲染损失的像素。特别是,我们会移除任何像素,其损失Eq. (12)大于当前帧所有像素的中值损失值的10倍。图6显示了一个示例,在这个示例中,动态物体被忽略,因为它在渲染的RGB和深度图像中不存在。需要注意的是,在这个任务中,我们只在映射期间优化场景表示。在动态环境下联合优化相机参数和场景表示是非常棘手的问题,我们认为这是一个有趣的未来方向。
3.4.4 Keyframe Selection
与其他SLAM系统类似,我们会使用一组选择的关键帧持续优化我们的分层场景表示。我们保持一个全局关键帧列表,与iMAP [47]保持相同的精神,在这里我们根据信息增益逐步添加新的关键帧。然而,与iMAP [47]不同的是,我们只包括与当前帧具有视觉重叠的关键帧在优化场景几何时。这是可能的,因为我们能够对基于网格的表示进行局部更新,并且我们不会受到[47]相同的遗忘问题的困扰。这种关键帧选择策略不仅确保了当前视野之外的几何保持静态,而且还导致了非常高效的优化问题,因为我们每次只优化必要的参数。在实践中,我们首先随机采样像素并使用优化的相机姿态对应地反投影深度。然后,我们将点云投影到全局关键帧列表中的每一个关键帧上。从那些有点投影的关键帧中,我们随机选择K-2帧。另外,我们还包括最近的关键帧和当前帧在场景表示优化中,形成总共K个活跃帧。有关关键帧选择策略的消融研究,请参阅第4.4节。
3.5 实验
3.80GHz英特尔i7-10700K CPU和3090 GPU的台式电脑,参数设置

3.5.1 评价指标
5个多功能数据集: Replica [45], ScanNet [13], TUM RGB-D数据集 [46], Co-Fusion数据集 [40], 以及一个包含多个房间的自拍大型公寓。按照[54]中的预处理步骤对TUM RGB-D进行处理。
基线。将相机姿态与分辨率为256×256×256的TSDF-Fusion [11]进行比较(更高分辨率的结果在附录中报告),使用他们官方实现的DI-Fusion [16],以及iMAP [47]重新实现版本: iMAP?。我们的重新实现在场景重建和相机跟踪方面表现与原始iMAP类似。
度量。我们使用2D和3D度量来评估场景几何。对于2D度量,我们评估从重建和地面真实网格中随机抽取的1000个深度图的L1损失。为了公平比较,在计算平均L1损失之前,我们将双边求解器[2]应用于DI-Fusion [16]和TSDF-Fusion以填充深度空洞。 对于3D度量,我们遵循[47],考虑准确度[cm]、完成度[cm]和完成比率[< 5cm %] ,除了我们移除了不在任何相机视锥内的未看见区域。至于相机跟踪的评估,我们使用ATE RMSE [46]。如果没有另外指定,默认情况下我们报告5次运行的平均结果。
3.5.2 评估结果
对Replica [45]的评估。为了评估Replica [45],我们使用iMAP作者提供的相同渲染的RGB-D序列。在层次化场景表示的支持下,我们的方法能够在有限迭代次数内精确重建几何结构。如表1所示,
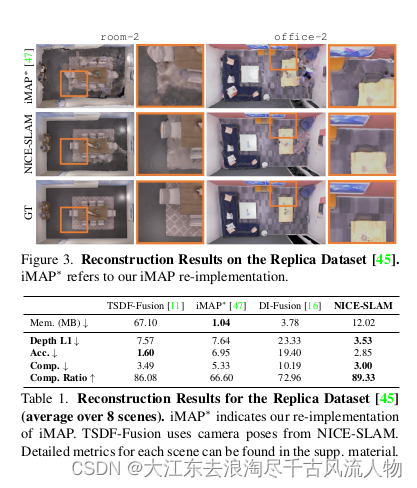
NICE-SLAM在几乎所有指标上明显优于基线方法,同时保持合理的内存消耗。从定性上来看,我们可以从图3中看到我们的方法产生了更锐利的几何结构和更少的伪影。
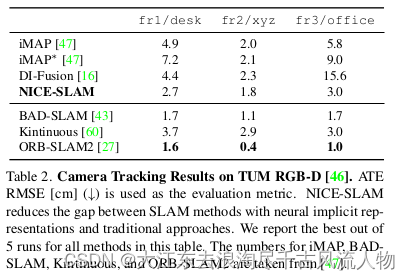
对TUM RGB-D [46]的评估。我们还在小规模的TUM RGB-D数据集上评估了相机跟踪性能。如表2所示,
虽然我们的方法在设计上更适合于大型场景,但在性能上仍优于iMAP和DI-Fusion。可以注意到,通常用于跟踪的最先进方法(例如BAD-SLAM [43],ORB-SLAM2 [27])仍然优于基于隐式场景表示的方法(iMAP [47]和我们的方法)。尽管如此,我们的方法显著缩小了这两个类别之间的差距,同时保留了隐式场景表示的优势。
对ScanNet [13]的评估。我们选择了来自ScanNet [13]的多个大型场景来评估不同方法的可伸缩性。从图4中可以清楚地看出,NICE-SLAM相对于TSDF-Fusion、DI-Fusion和iMAP?产生了更锐利、更详细的几何结构。在跟踪方面,从图中可以观察到,iMAP?和DI-Fusion要么完全失败,要么引入大的漂移,而我们的方法成功重建整个场景。量化来看,如表3所示,
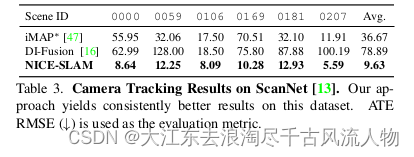
我们的跟踪结果也明显比DI-Fusion和iMAP?准确。
**对更大场景的评估。**为了评估我们的方法的可伸缩性,我们在一个拥有多个房间的大型公寓中捕获了一个序列。图1和图5
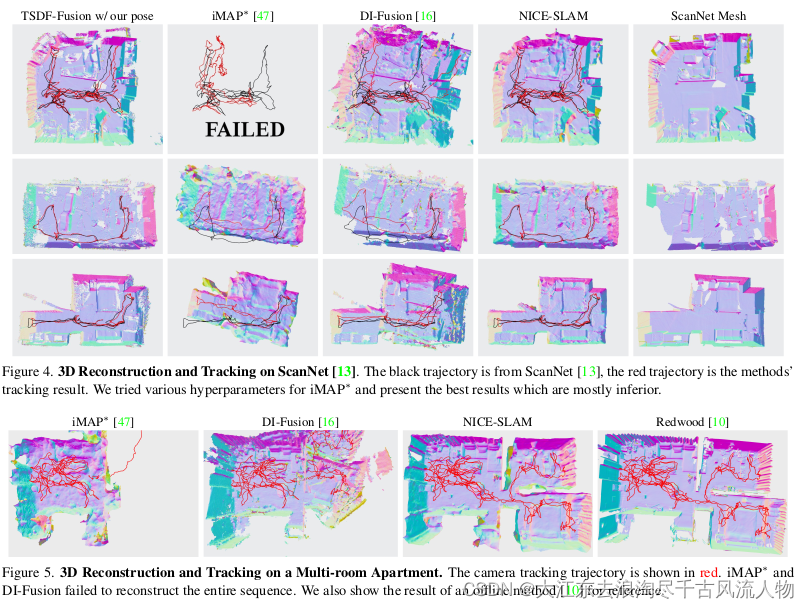
展示了使用NICE-SLAM、DI-Fusion [16]和iMAP? [47]获得的重建结果。为了比较,我们还展示了使用Open3D [70]中的离线工具Redwood [10]进行的3D重建。从图中可以看出,NICE-SLAM的结果与离线方法相当,而iMAP?和DI-Fusion则无法重建整个序列。
3.5.3 结果分析
除了对各种数据集上的场景重建和摄像机跟踪进行评估之外,在接下来的部分中,我们还评估了所提出的流程的其他特点。
计算复杂性
首先,我们比较了查询一个3D点的颜色和占用/体积密度所需的浮点运算(FLOPs)数量,见表4。我们的方法仅需要iMAP的1/4 FLOPs。

值得一提的是,在我们的方法中,即使对于非常大的场景,FLOPs也保持不变。相比之下,由于iMAP中单个MLP的使用,MLP的容量上限可能需要更多参数,导致更多的FLOPs。
运行时间
我们还在表4中对使用相同数量的像素样本(M t = 200用于跟踪和M = 1000用于建图)进行跟踪和建图的运行时间进行了比较。我们可以看到,我们的方法在跟踪和建图方面分别比iMAP快2倍和3倍以上。这表明了使用具有浅MLP解码器的特征网格比单个重型MLP具有优势。
对动态对象的鲁棒性
我们考虑了包含动态移动物体的Co-Fusion数据集 [40]。如图6所示,我们的方法在优化过程中正确识别并忽略了落入动态物体中的像素样本,从而更好地模拟场景表示(见渲染的RGB和深度图)。此外,我们还在相同的序列上将我们的方法与iMAP?进行了相机跟踪的比较。我们的ATE RMSE分数为1.6cm,而iMAP?为7.8cm,这清楚地证明了我们对动态对象的鲁棒性。
几何预测和填补洞
如图7所示,

由于使用了粗略级别的场景先验,我们能够完成未观察到的场景区域。相比之下,iMAP?重建的未见区域非常嘈杂,因为iMAP?中没有编码场景先验知识。
3.5.4 消融实验 ablation study
在这一部分,我们调查了我们分层架构的选择以及颜色表示的重要性。
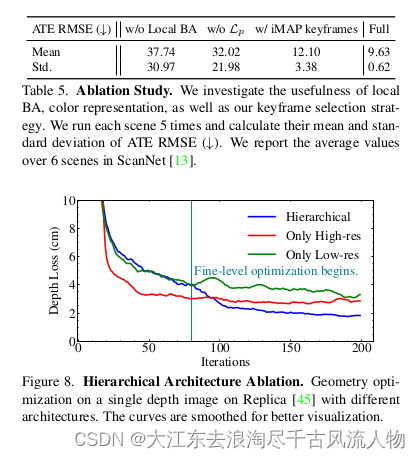
分层架构
图8比较了我们的分层架构与以下内容:
a) 一个具有与我们精细级表示相同分辨率的特征网格(仅高分辨率);
b) 一个具有中级分辨率的特征网格(仅低分辨率)。
我们的分层架构可以在精细级表示参与优化时快速添加几何细节,这也导致更好的收敛。
局部BA
我们在ScanNet [13]上验证了局部捆绑调整的有效性。如果我们不同时优化K个关键帧的相机姿态和场景表示(在表5中的无局部BA),则相机跟踪不仅精度显著降低,而且鲁棒性也较差。
颜色表示
在表5中,我们比较了我们的方法在没有光度损失L p 的情况下。结果显示,尽管由于有限的优化预算和采样点的缺乏,我们估计的颜色不完美,但学习这样的颜色表示仍然对于准确的相机跟踪起着重要作用。
关键帧选择
我们使用了iMAP的关键帧选择策略(表5中的使用iMAP关键帧),其中它们从整个场景中选择关键帧。这对于iMAP来防止他们简单的MLP忘记之前的几何图形是必要的。然而,这也导致了较慢的收敛和不准确的跟踪。
3.5.5 结论
提出了NICE-SLAM,这是一种密集的视觉SLAM方法,它结合了神经隐式表示的优势与基于分层网格的可扩展性场景表示。与单个大型MLP的场景表示相比,我们的实验表明,我们的表示(小型MLP + 多分辨率特征网格)不仅保证了精细映射和高跟踪精度,而且由于局部场景更新的好处,速度更快、计算量更少。此外,我们的网络能够填补小孔并将场景几何外推到未观察到的区域,从而稳定了相机跟踪。限制。我们的方法的预测能力受限于粗略表示的规模。此外,我们的方法不进行闭环检测,这是一个有趣的未来方向。最后,尽管传统方法缺少一些特性,但学习驱动的方法与之间仍存在性能差距,需要弥补
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 推荐系统中的 业务指标 UV
- idea带的maven在SpringBoot下载jar包出错
- ChatGPT 论文:Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models (二)
- Python Tkinter Place布局管理器及用法
- Vmware Windows10安装Apache php
- 轻松批量重命名,一键随机并控制长度:让你的文件夹名充满无限可能
- 【Java万花筒】虚拟奇境:Java引擎驱动的物理计算与仿真技术揭秘
- c# 使用Null合并操作符例子
- 嘴尚绝:卤味市场未来发展潜力无限,谁将成为下一个风口?
- 搭建Selenium自动化测试环境,安装包以及驱动地址