TensorBoard(代码注释有一些对梯度计算,优化器,学习率,反向传播,损失这些基础概念的理解)
1. 详细说明? ?进入pytorch官网-Tutorials-找到visuallizing Models,Data,and Training with TensorBoard.
tensorboard我的理解就是一个用来保存查看训练过程参数,训练情况的库,可以根据可视化的界面,理解模型的训练优化过程,并且可以利用得到的信息进行优化模型。
2. torch.utils.tensorboard.SummaryWriter("保存路径"),这里我运行在指定文件夹下有四个文件,应该是存的以下四种数据:
? ? ? ? add_graph()? 模型示意图
? ? ? ? add_scalar() 折线图
? ? ? ? add_figure() 预测图片在每一轮epoch的预测情况
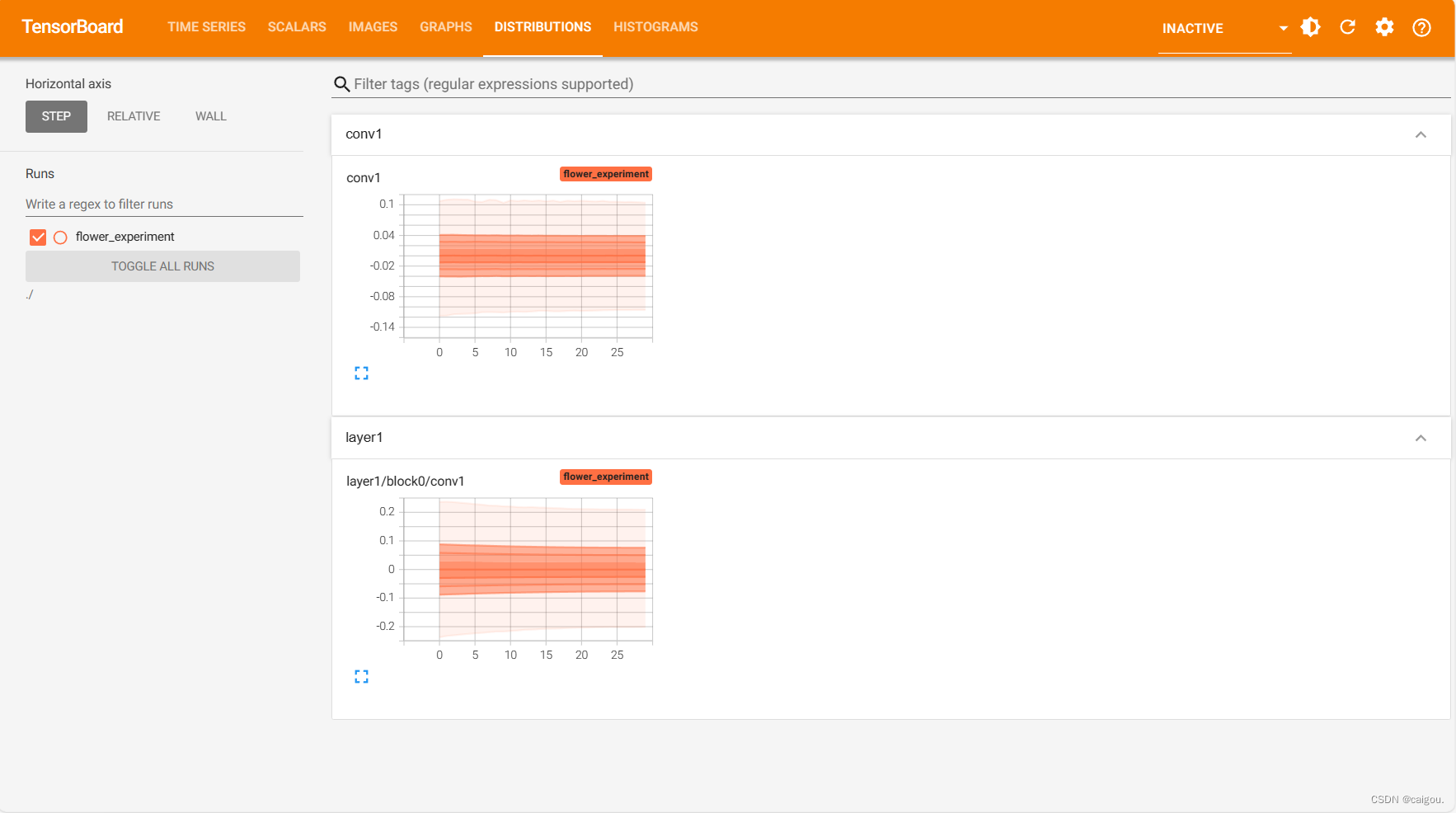
? ? ? ? add_histogram()? 参数数量的直方图
3. 具体见代码和截图,打开tensorboard方法:进入命令行,激活相应环境(一定要进入相关环境才能用tensorboard.exe指令),进入SummaryWriter("保存路径")里的路径文件夹前一个文件夹,输入命令:
因为默认只显示10个epoch的预测情况,设置为50,才能显示完全。
tensorboard.exe --logdir=./ --samples_per_plugin=images=50 ? ??
训练完整代码:? 很多内容都在代码的注释里
train.py
import os
import math
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torch.optim.lr_scheduler as lr_scheduler
from model import resnet34
from my_dataset import MyDataSet
from data_utils import read_split_data, plot_class_preds
from train_eval_utils import train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
# 实例化SummaryWriter对象,log_dir是写入的目录
tb_writer = SummaryWriter(log_dir="runs/flower_experiment")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
# 划分数据为训练集和验证集,训练集图片路径列表,对应训练集图片标签(这个标签是索引)
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
# 定义训练以及预测时的预处理方法
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_data_set = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_data_set = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
# 计算使用num_workers的数量 os.cpu_count() 是一个函数,用于获取系统中可用的 CPU 核心数量。
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=batch_size,
shuffle=True,
pin_memory=True, # 提高数据加载的效率
num_workers=nw,
collate_fn=train_data_set.collate_fn)
val_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_data_set.collate_fn)
# 实例化模型
model = resnet34(num_classes=args.num_classes).to(device)
# 将模型写入tensorboard, 用一个数据+模型就可以把模型写入tensorboatd
init_img = torch.zeros((1, 3, 224, 224), device=device)
tb_writer.add_graph(model, init_img)
# 如果存在预训练权重则载入
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
# model.state_dict()[k].numel() 获取模型名k对应的参数的数量
if model.state_dict()[k].numel() == v.numel()}
model.load_state_dict(load_weights_dict, strict=False)
else:
print("not using pretrain-weights.")
# 是否冻结权重
if args.freeze_layers:
print("freeze layers except fc layer.")
# model.named_parameters() 都是nn.Module里的方法,获取结构名和参数,
for name, para in model.named_parameters():
# 除最后的全连接层外,其他权重全部冻结
if "fc" not in name:
para.requires_grad_(False)
# model.parameters() 获取需要训练的模型参数,p.requires_grad=True即需要梯度信息
pg = [p for p in model.parameters() if p.requires_grad]
# 学习率的动量参数,权重衰减系数定义参数优化器
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
# 定义学习率调度器
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
# 将学习率调度器与优化器绑定,使得优化器能够根据学习率调度器的结果来更新学习率
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
for epoch in range(args.epochs):
# train
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# update learning rate
# 每训练一个epoch,学习率进行一次更新,以便优化器根据新的学习率优化下一次epoch里的每个step的数据
scheduler.step()
# validate
acc = evaluate(model=model,
data_loader=val_loader,
device=device)
# add loss, acc and lr into tensorboard
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
# 写入器 tb_writer 每个epoch写入一次,
# 可以在 TensorBoard 的界面中查看、比较和分析标量值的变化趋势,帮助理解和监控训练过程中的指标。
tags = ["train_loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
# add figure into tensorboard
# 用每个epoch的权重预测一遍
fig = plot_class_preds(net=model,
images_dir="./plot_img",
transform=data_transform["val"],
num_plot=5,
device=device)
if fig is not None:
tb_writer.add_figure("predictions vs. actuals",
figure=fig,
global_step=epoch)
# add conv1 weights into tensorboard 两个直方图
tb_writer.add_histogram(tag="conv1",
values=model.conv1.weight,
global_step=epoch)
tb_writer.add_histogram(tag="layer1/block0/conv1",
values=model.layer1[0].conv1.weight,
global_step=epoch)
# save weights
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch-size', type=int, default=16)
# 学习率,控制参数更新步长的超参数
parser.add_argument('--lr', type=float, default=0.001)
parser.add_argument('--lrf', type=float, default=0.1)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
img_root = "../../data_set/flower_data/flower_photos"
parser.add_argument('--data-path', type=str, default=img_root)
# resnet34 官方权重下载地址
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
# parser.add_argument('--weights', type=str, default='resNet34.pth',
# help='initial weights path')
# 这个不用预训练权重,用预训练权重tensorboard上训练曲线效果不明显
parser.add_argument('--weights', type=str, default='',
help='initial weights path')
# freeze-layers 是否冻结除全连接层外的其他层
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda', help='device id (i.e. 0 or 0,1 or cpu)')
# parse_args() 用于解析命令行参数,返回一个包含解析结果的命名空间对象,可以通过属性访问这些参数的值
# 在命令行运行脚本时可以通过传递相应的选项和参数来解析
opt = parser.parse_args()
main(opt)
mdoel.py
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
my_dataset.py
from tqdm import tqdm
from PIL import Image
import torch
from torch.utils.data import Dataset
class MyDataSet(Dataset):
"""自定义数据集"""
def __init__(self, images_path: list, images_class: list, transform=None):
self.images_path = images_path
self.images_class = images_class
self.transform = transform
delete_img = []
for index, img_path in tqdm(enumerate(images_path)):
img = Image.open(img_path)
w, h = img.size
ratio = w / h
if ratio > 10 or ratio < 0.1:
delete_img.append(index)
# print(img_path, ratio)
for index in delete_img[::-1]:
self.images_path.pop(index)
self.images_class.pop(index)
def __len__(self):
return len(self.images_path)
def __getitem__(self, item):
img = Image.open(self.images_path[item])
# RGB为彩色图片,L为灰度图片
if img.mode != 'RGB':
raise ValueError("image: {} isn't RGB mode.".format(self.images_path[item]))
label = self.images_class[item]
if self.transform is not None:
img = self.transform(img)
return img, label
@staticmethod
def collate_fn(batch):
# 官方实现的default_collate可以参考
# https://github.com/pytorch/pytorch/blob/67b7e751e6b5931a9f45274653f4f653a4e6cdf6/torch/utils/data/_utils/collate.py
images, labels = tuple(zip(*batch))
images = torch.stack(images, dim=0)
labels = torch.as_tensor(labels)
return images, labels
data_utils.py
import os
import json
import pickle
import random
from PIL import Image
import torch
import numpy as np
import matplotlib.pyplot as plt
def read_split_data(root: str, val_rate: float = 0.2):
random.seed(0) # 保证随机结果可复现
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
# 遍历文件夹,一个文件夹对应一个类别
flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
# 排序,保证顺序一致,列表排序
flower_class.sort()
# 生成类别名称以及对应的数字索引 {"daisy":0,"dandelion":1,"roses":2,"sunflowers":3,"tulips":4}
class_indices = dict((k, v) for v, k in enumerate(flower_class))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
train_images_path = [] # 存储训练集的所有图片路径
train_images_label = [] # 存储训练集图片对应索引信息
val_images_path = [] # 存储验证集的所有图片路径
val_images_label = [] # 存储验证集图片对应索引信息
every_class_num = [] # 存储每个类别的样本总数
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
# 遍历每个文件夹下的文件
for cla in flower_class:
cla_path = os.path.join(root, cla)
# 遍历获取supported支持的所有文件路径,os.path.join()可以拼接若干个字符串
images = [os.path.join(root, cla, i) for i in os.listdir(cla_path)
if os.path.splitext(i)[-1] in supported]
# 获取该类别对应的索引
image_class = class_indices[cla]
# 记录该类别的样本数量
every_class_num.append(len(images))
# 按比例随机采样验证样本
val_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集
val_images_path.append(img_path) # 验证图片的路径列表
val_images_label.append(image_class) # 验证图片对应的标签列表
else: # 否则存入训练集
train_images_path.append(img_path)
train_images_label.append(image_class)
print("{} images were found in the dataset.".format(sum(every_class_num)))
print("{} images for training.".format(len(train_images_path)))
print("{} images for validation.".format(len(val_images_path)))
plot_image = False
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(flower_class)), every_class_num, align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(flower_class)), flower_class)
# 在柱状图上添加数值标签
for i, v in enumerate(every_class_num):
plt.text(x=i, y=v + 5, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('flower class distribution')
plt.show()
return train_images_path, train_images_label, val_images_path, val_images_label
def plot_data_loader_image(data_loader):
batch_size = data_loader.batch_size
plot_num = min(batch_size, 4)
json_path = './class_indices.json'
assert os.path.exists(json_path), json_path + " does not exist."
json_file = open(json_path, 'r')
class_indices = json.load(json_file)
for data in data_loader:
images, labels = data
for i in range(plot_num):
# [C, H, W] -> [H, W, C]
img = images[i].numpy().transpose(1, 2, 0)
# 反Normalize操作
img = (img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255
label = labels[i].item()
plt.subplot(1, plot_num, i+1)
plt.xlabel(class_indices[str(label)])
plt.xticks([]) # 去掉x轴的刻度
plt.yticks([]) # 去掉y轴的刻度
plt.imshow(img.astype('uint8'))
plt.show()
def write_pickle(list_info: list, file_name: str):
with open(file_name, 'wb') as f:
pickle.dump(list_info, f)
def read_pickle(file_name: str) -> list:
with open(file_name, 'rb') as f:
info_list = pickle.load(f)
return info_list
def plot_class_preds(net,
images_dir: str,
transform,
num_plot: int = 5,
device="cpu"):
if not os.path.exists(images_dir):
print("not found {} path, ignore add figure.".format(images_dir))
return None
label_path = os.path.join(images_dir, "label.txt")
if not os.path.exists(label_path):
print("not found {} file, ignore add figure".format(label_path))
return None
# read class_indict
json_label_path = './class_indices.json'
assert os.path.exists(json_label_path), "not found {}".format(json_label_path)
json_file = open(json_label_path, 'r')
# {"0": "daisy"} json.load() 返回一个json文件里的字典
flower_class = json.load(json_file)
# {"daisy": "0"}
class_indices = dict((v, k) for k, v in flower_class.items())
# reading label.txt file
label_info = []
with open(label_path, "r") as rd:
for line in rd.readlines():
line = line.strip()
if len(line) > 0:
# 读取到的txt里的一行以空格分格,返回一个这行元素的列表
split_info = [i for i in line.split(" ") if len(i) > 0]
# 这行元素生成的列表一定是两个元素,一个是图片名,一个是类别名称
assert len(split_info) == 2, "label format error, expect file_name and class_name"
image_name, class_name = split_info
image_path = os.path.join(images_dir, image_name)
# 如果文件不存在,则跳过
if not os.path.exists(image_path):
print("not found {}, skip.".format(image_path))
continue
# 如果读取的类别不在给定的类别内,则跳过
if class_name not in class_indices.keys():
print("unrecognized category {}, skip".format(class_name))
continue
# label_info 是获取到的图片名和对应类型的二维列表,因为把每行的两个元素都加进去了
label_info.append([image_path, class_name])
if len(label_info) == 0:
return None
# get first num_plot info num_plot是画预测图的数量限制,如果txt文件过多,只取前num_plot个
if len(label_info) > num_plot:
label_info = label_info[:num_plot]
num_imgs = len(label_info)
images = []
labels = []
for img_path, class_name in label_info:
# read img
img = Image.open(img_path).convert("RGB")
label_index = int(class_indices[class_name])
# preprocessing
img = transform(img)
images.append(img)
labels.append(label_index)
# batching images 添加维度,把要预测的经过预处理后的图片张量打包成一批,生成images张量
images = torch.stack(images, dim=0).to(device)
# inference
with torch.no_grad():
# output: [batch_pred,num_cls]
output = net(images)
# softmax 函数常用于将模型输出转换为概率分布,用于多分类任务的概率预测
# torch.softmax(output, dim=1) 将在维度 dim=1 上计算张量 output 的 softmax 函数值。
# 这意味着将对 output 张量中的每一行应用 softmax 函数,并返回具有相同形状的张量,其中每一行的元素之和等于 1
# torch.softmax(output, dim=1)返回一个具有相同形状的张量。
# torch.max() 函数在这个 softmax 张量上再次使用 dim=1,来获取每一行的最大值和最大值的索引
# 这个索引就是预测类别preds,probs长是预测batch的一维张量,preds长也是预测batch的一维张量,batch就是batch_pred
# 一个batch有多少张图片,预测矩阵张量就有多少行,预测的有多少类,就有多少列
probs, preds = torch.max(torch.softmax(output, dim=1), dim=1)
# 通过调用 cpu() 方法,将它们从 GPU 设备上移动到 CPU 设备上。
"""
为什么要移动到cpu上?
数据后处理:有时候,在模型的输出上需要进行一些后处理操作,例如计算指标、可视化结果或保存结果到磁盘。
这些操作通常在 CPU 上执行,因为 CPU 上的计算能力足够处理这些任务。
与其他库的兼容性:某些库或工具可能对 CPU 上的数据更加友好,而不是 GPU 上的数据。
例如,一些常用的数据处理、可视化或存储库可能更容易与 CPU 上的数据进行交互,所以需要将 GPU 上的数据转换为 CPU 上的数据。
内存限制:在处理大规模数据集或模型时,GPU 的显存可能会受到限制。
如果计算结果的大小超过 GPU 的显存容量,那么需要将其移动到 CPU 上进行处理。
模型部署:在将训练好的模型部署到生产环境中时,可能需要将模型的输出从 GPU 移动到 CPU 上,
因为生产环境通常没有 GPU 或者 GPU 的数量有限。
"""
probs = probs.cpu().numpy()
preds = preds.cpu().numpy()
# width, height 每张图片显示宽是250,高是300,共num_imgs张图片
fig = plt.figure(figsize=(num_imgs * 2.5, 3), dpi=100)
for i in range(num_imgs):
# 1:子图共1行,num_imgs:子图共num_imgs列,当前绘制第i+1个子图 xticks=[], yticks=[]清空坐标刻度
ax = fig.add_subplot(1, num_imgs, i+1, xticks=[], yticks=[])
# CHW -> HWC
npimg = images[i].cpu().numpy().transpose(1, 2, 0)
# 将图像还原至标准化之前
# mean:[0.485, 0.456, 0.406], std:[0.229, 0.224, 0.225]
npimg = (npimg * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255
plt.imshow(npimg.astype('uint8'))
title = "{}, {:.2f}%\n(label: {})".format(
flower_class[str(preds[i])], # predict class
probs[i] * 100, # predict probability
flower_class[str(labels[i])] # true class
)
ax.set_title(title, color=("green" if preds[i] == labels[i] else "red"))
return fig
train_eval_utils.py
import sys
from tqdm import tqdm
import torch
def train_one_epoch(model, optimizer, data_loader, device, epoch):
"""
在深度学习中,model.train()是一个用于设置模型为训练模式的方法。调用该方法后,模型会进行以下操作:
激活训练模式:设置模型的train属性为True,表示将进入训练模式。这是为了告诉模型在训练期间需要执行训练相关的操作,例如启用Dropout和Batch Normalization层的训练行为。
梯度计算:启用梯度计算,以便在反向传播过程中计算和累积参数的梯度。这是为了在训练过程中更新模型的权重和偏置。
批归一化更新:在训练模式下,批归一化层会根据当前批次的输入数据更新其内部统计信息,例如均值和方差。这是为了保证每个批次的数据都能够获得相对一致的归一化效果。
Dropout激活:在训练模式下,Dropout层将以一定的概率随机丢弃部分神经元的输出。这有助于提高模型的泛化能力和防止过拟合。
总的来说,model.train()方法的调用是为了将模型设置为训练模式,以便进行参数更新和训练相关的操作。
要先在反向传播里计算参数的梯度,才有用优化器根据学习率调度规则来优化训练的参数
"""
model.train()
loss_function = torch.nn.CrossEntropyLoss()
# 用于累积每个批次的损失值
mean_loss = torch.zeros(1).to(device)
# 使用optimizer.zero_grad()将优化器中的梯度信息清零。这是为了确保在每个批次开始时,梯度不会累积之前的批次的梯度信息。
optimizer.zero_grad()
# 将 data_loader 中的迭代过程包装在一个进度条中,并将进度信息输出到标准输出(stdout)
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
"""
softmax 归一化处理,确保每个样本的预测概率之和等于1。这样做是为了将预测输出转换为概率分布,使其表示模型对每个类别的预测概率。
"""
# 具体损失函数做了什么,pred是一个 batch_size * num_cls 的二维张量
# labels是一个存有类别索引的 长度为 batch_size 的一维张量
# 交叉熵损失函数先把labels根据索引类别变成 batch_size * num_cls 的二维独热编码张量
# 然后根据真实标签的概率和预测的相应位置上的概率计算损失
# 最后,对这些交叉熵值进行平均或求和操作,得到一个表示整个批次的损失值
# 通常情况下,我们会将这个损失值作为模型在当前批次数据上的损失。
loss = loss_function(pred, labels.to(device))
# 损失的反向传播
"""
backward() 方法的作用是计算损失函数关于模型参数的梯度。具体来说,它执行以下操作:
从损失值开始,通过链式法则计算梯度:PyTorch 中的自动求导机制会根据计算图中的节点,自动计算每个节点相对于损失的梯度。这是通过应用链式法则来实现的,从损失节点开始,逐层向后传播计算梯度。
累积梯度:梯度计算得到的梯度值会被累积到每个参数的 .grad 属性中。
梯度计算完成:一旦完成梯度计算,可以使用得到的梯度值来执行参数更新和优化算法,例如使用梯度下降算法来更新模型的参数。
"""
loss.backward()
"""
loss.detach() 方法执行以下操作:
分离张量:该方法创建一个新的张量,其值与原始张量相同,但不再与计算图关联。
断开梯度计算:分离的张量将不再保留梯度信息。这意味着对分离张量进行任何操作或计算梯度时,梯度将不会回传到原始张量。
"""
# 计算迭代到当前批次的前面所有批次和这批的平均损失,这是一个批次平均损失,每个批次的损失里包括每个图片张量的损失,可以是一批图片
# 损失的平均值或和
mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # update mean losses
# 打印平均loss
# mean_loss.item() 是一个张量的方法,用于获取张量的数值表示
# round(mean_loss.item(), 3) 将损失值保留三位小数
# 当使用 tqdm 来迭代一个可迭代对象时,可以通过设置 desc 参数来为进度条添加描述信息。
# 每迭代一次data_loader,都要更新一次下面的进度条描述信息
data_loader.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))
# torch.isfinite(loss) 用于检查损失值是否为有限值。
#
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
# 参数更新:如果损失值是有限值,代码会执行 optimizer.step() 来更新模型的参数。
# 这一步是优化算法的核心,根据计算得到的梯度来调整模型参数,以最小化损失函数。
# 清空梯度:在参数更新之后,为了避免梯度的累积影响后续的迭代,
# 代码会执行 optimizer.zero_grad() 来清空之前计算的梯度值,为下一次迭代做准备。
# 定义优化器时已经传入了需要进行训练的参数(梯度计算的参数),
# 通过para.requires_grad_(False)也设置了模型里不需要求梯度的参数,loss.backward()也不会求损失对应相关参数的梯度
# 这样optimizer.step()优化器进行用定义优化器时传入的学习率更新策略优化时就只根据loss.backward()求得的梯度优化传入优化器的需要优化的参数
optimizer.step()
optimizer.zero_grad()
return mean_loss.item()
@torch.no_grad()
def evaluate(model, data_loader, device):
model.eval()
# 用于存储预测正确的样本个数 torch.zeros(1)创建一个1*n的元素全是0的张量,其实就是一个一维张量,一维是线,点是0维
sum_num = torch.zeros(1).to(device)
# 统计验证集样本总数目,这个总数目不是批次数,而是验证集的所有图片数
num_samples = len(data_loader.dataset)
# 打印验证进度
data_loader = tqdm(data_loader, desc="validation...", file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
# dim等于1表示取每行最大值及其索引,dim=0表示取每一列上最大值及其索引,
# torch.max(pred, dim=1)返回的是两个一维张量,第一个是每一行最大值,第二个是对应的索引
# [1] 返回的是第二个输出,即每行上最大值对应的索引,其实就是类别,预测的类别
pred = torch.max(pred, dim=1)[1]
# pred是一个一维张量,包含一个批次的每张图片的索引,共batch_size个元素,
# torch.eq(pred, labels.to(device)) 对比预测的一维张量和从dataset中获取的labels这个标签一维张量有几个位置的元素相同
# 即有几张图片预测正确了,sum()求得一个批次中预测正确的图片数
sum_num += torch.eq(pred, labels.to(device)).sum()
# 计算预测正确的比例
# item() 方法用于将张量中的单个元素提取为 Python 标量值,
# 一个epoch中所有批次的所有图片的预测正确总数/验证集中图片总数 求得预测的正确率,进行返回
acc = sum_num.item() / num_samples
return acc
训练过程:
3670 images were found in the dataset.
2939 images for training.
731 images for validation.
2939it [00:00, 4558.29it/s]
731it [00:00, 4928.77it/s]
Using 8 dataloader workers every process
not using pretrain-weights.
[epoch 0] mean loss 1.416: 100%|██████████| 184/184 [00:42<00:00, 4.30it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 0] accuracy: 0.473
[epoch 1] mean loss 1.27: 100%|██████████| 184/184 [00:42<00:00, 4.32it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 1] accuracy: 0.59
[epoch 2] mean loss 1.155: 100%|██████████| 184/184 [00:42<00:00, 4.36it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.24it/s]
[epoch 2] accuracy: 0.64
[epoch 3] mean loss 1.088: 100%|██████████| 184/184 [00:42<00:00, 4.36it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.24it/s]
[epoch 3] accuracy: 0.662
[epoch 4] mean loss 1.043: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.20it/s]
[epoch 4] accuracy: 0.683
[epoch 5] mean loss 1.019: 100%|██████████| 184/184 [00:42<00:00, 4.34it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 5] accuracy: 0.644
[epoch 6] mean loss 0.979: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.20it/s]
[epoch 6] accuracy: 0.705
[epoch 7] mean loss 0.959: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 7] accuracy: 0.713
[epoch 8] mean loss 0.913: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:21<00:00, 2.18it/s]
[epoch 8] accuracy: 0.715
[epoch 9] mean loss 0.881: 100%|██████████| 184/184 [00:43<00:00, 4.27it/s]
validation...: 100%|██████████| 46/46 [00:21<00:00, 2.18it/s]
[epoch 9] accuracy: 0.741
[epoch 10] mean loss 0.843: 100%|██████████| 184/184 [00:42<00:00, 4.32it/s]
validation...: 100%|██████████| 46/46 [00:21<00:00, 2.17it/s]
[epoch 10] accuracy: 0.741
[epoch 11] mean loss 0.846: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 11] accuracy: 0.74
[epoch 12] mean loss 0.839: 100%|██████████| 184/184 [00:42<00:00, 4.34it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 12] accuracy: 0.759
[epoch 13] mean loss 0.808: 100%|██████████| 184/184 [00:42<00:00, 4.33it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 13] accuracy: 0.713
[epoch 14] mean loss 0.769: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 14] accuracy: 0.767
[epoch 15] mean loss 0.759: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.24it/s]
[epoch 15] accuracy: 0.717
[epoch 16] mean loss 0.759: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 16] accuracy: 0.756
[epoch 17] mean loss 0.711: 100%|██████████| 184/184 [00:42<00:00, 4.32it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 17] accuracy: 0.784
[epoch 18] mean loss 0.73: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.24it/s]
[epoch 18] accuracy: 0.766
[epoch 19] mean loss 0.681: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 19] accuracy: 0.787
[epoch 20] mean loss 0.66: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 20] accuracy: 0.776
[epoch 21] mean loss 0.658: 100%|██████████| 184/184 [00:42<00:00, 4.33it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 21] accuracy: 0.778
[epoch 22] mean loss 0.663: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 22] accuracy: 0.782
[epoch 23] mean loss 0.623: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 23] accuracy: 0.796
[epoch 24] mean loss 0.589: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.21it/s]
[epoch 24] accuracy: 0.8
[epoch 25] mean loss 0.616: 100%|██████████| 184/184 [00:42<00:00, 4.32it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.20it/s]
[epoch 25] accuracy: 0.802
[epoch 26] mean loss 0.586: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.21it/s]
[epoch 26] accuracy: 0.811
[epoch 27] mean loss 0.569: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 27] accuracy: 0.814
[epoch 28] mean loss 0.559: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 28] accuracy: 0.817
[epoch 29] mean loss 0.567: 100%|██████████| 184/184 [00:42<00:00, 4.35it/s]
validation...: 100%|██████████| 46/46 [00:20<00:00, 2.22it/s]
[epoch 29] accuracy: 0.814
打开tensorboard面板:


由于是在每个epoch训练和验证完后进行一次对预测图片的的预测,所以可以查看每个epoch,在tensorboard界面中是step表示,的预测情况,具体打印的信息在代码中进行控制。
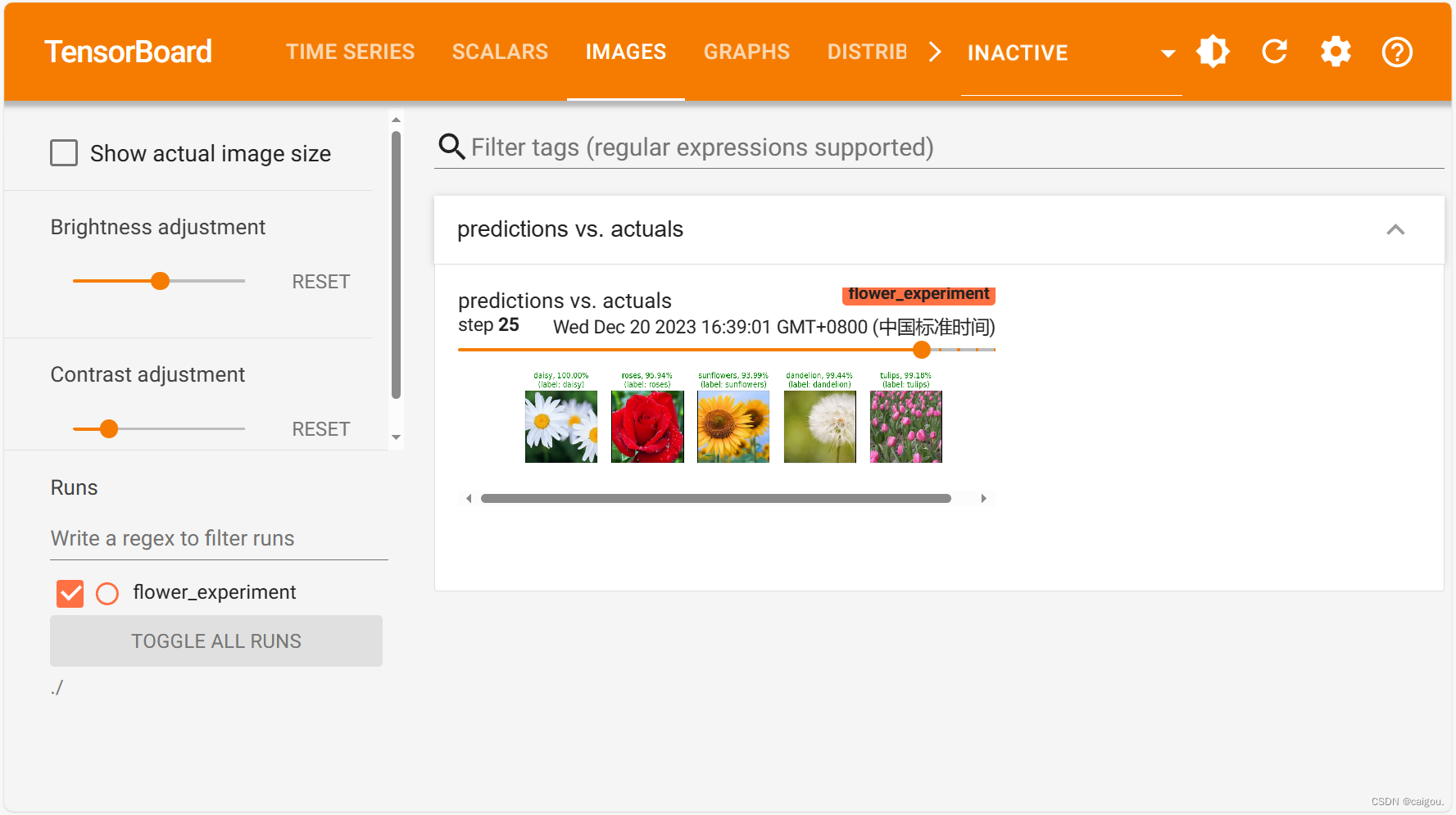
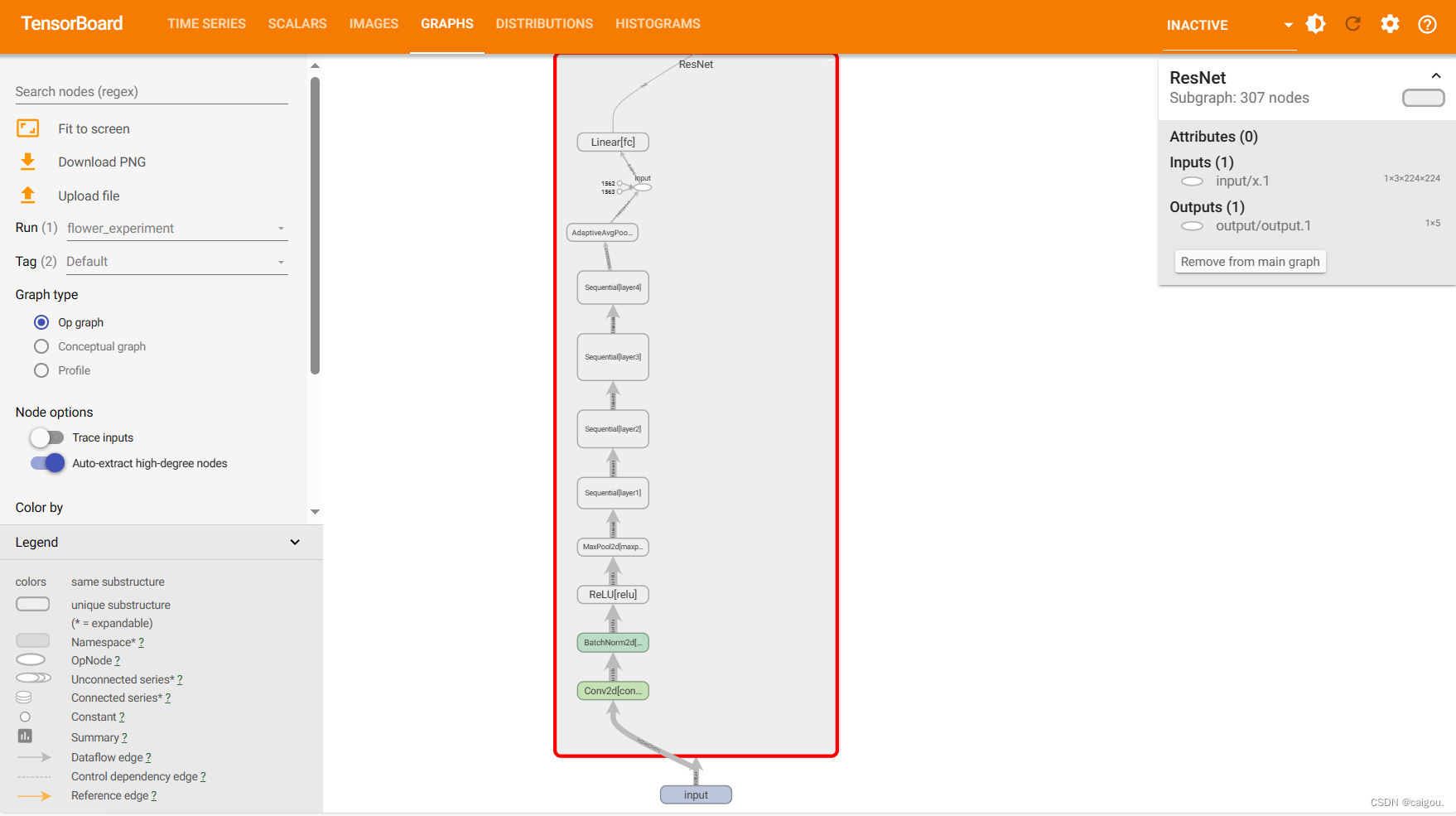 ?GRAPH可以查看详细数据在模型里的流向情况。
?GRAPH可以查看详细数据在模型里的流向情况。

在代码里定义的要查看的每一层的权重参数的分布情况。

DISTRIBUTED是tensorboard提供的另一种查看方式。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 5 微信小程序
- Vue Tinymce富文本组件自定义带下拉框的操作按钮
- 技术、经验双重buff叠加,惟客数据助力中国品牌扬帆出海
- 根文件以及中断
- Leetcode 106. 从中序与后序遍历序列构造二叉树
- TypeScript 从入门到进阶之基础篇(九) Class类篇
- 数据分析为何要学统计学(10)——如何进行比率检验
- GIS项目实战07:Eclipse资源分享
- pytorch安装+出现ModuleNotFoundError: No module named ‘torchvision‘的解决办法
- GSP算法在数据挖掘中的应用