LLM之RAG实战(十六)| 使用Llama-2、PgVector和LlamaIndex构建LLM Rag Pipeline

? ? ? ?近年来,大型语言模型(LLM)取得了显著的进步,然而大模型缺点之一是幻觉问题,即“一本正经的胡说八道”。其中RAG(Retrieval Augmented Generation,检索增强生成)是解决幻觉比较有效的方法。本文,我们将深入研究使用transformer库、Llama-2模型、PgVector数据库和LlamaIndex库来构建RAG Pipeline完整过程。
一、什么是RAG(检索增强生成)?
? ? ? ?检索增强生成(RAG)模型是传统语言模型与信息检索组件的融合。从本质上讲,RAG利用外部数据(通常来自大型语料库或数据库)来增强大语言模型生成过程,以产生更知情和上下文相关的响应。
二、RAG的工作原理
检索阶段:当查询输入到RAG系统时,首先从数据库中检索相关信息。
增强阶段:然后将检索到的数据输入到一个语言模型中,比如案例中的Llama-2,它会生成一个响应。这种响应不仅基于模型预先训练的知识,还基于在第一阶段检索到的特定信息。
三、Llama-2:大语言模型
? ? ?? 关于Llama-2模型的介绍,可以参考我之前的文章Meta发布升级大模型LLaMA 2:开源可商用
主要功能:
多功能性:Llama-2可以处理各种NLP任务。
上下文理解:它擅长于掌握对话或文本的上下文。
语言生成:Llama-2可以生成连贯且符合上下文的反应。
为什么Llama-2用于RAG?:Llama-2在性能和计算效率方面的平衡使其成为RAG管道的理想候选者,尤其是在处理和生成基于大量检索数据的响应时。
四、PgVector:高效管理矢量数据

? ? ? ?PgVector是PostgreSQL的扩展,PostgreSQL是一个流行的开源关系数据库。它是为处理高维矢量数据而定制的,就像Llama-2等语言模型生成的数据一样。PgVector允许对矢量数据进行高效存储、索引和搜索,使其成为涉及大型数据集和复杂查询的项目的重要工具。
主要功能:
效率:为快速检索高维数据而优化。
集成:与PostgreSQL数据库无缝集成。
可扩展性:适用于处理大规模矢量数据集。
RAG中的重要性:对于RAG,PgVector提供了一个优化的数据库环境来存储和检索矢量化形式的数据,这对检索阶段至关重要。
五、LlamaIndex:连接语言和数据库
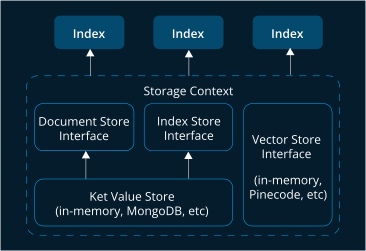
? ? ? ?LlamaIndex可以使用Llama-2将文本数据转换为向量,然后将这些向量存储在由PgVector授权的PostgreSQL数据库中。这种转换对于实现基于语义相似性而不仅仅是关键字匹配的高效文本检索至关重要。
主要功能:
语义索引:将文本转换为表示语义的向量。
数据库集成:存储和检索PostgreSQL中的矢量数据。
增强检索:方便高效、上下文感知的搜索功能。
RAG中的角色:LlamaIndex对于有效搜索存储在PgVector数据库中的嵌入至关重要,它便于根据查询输入快速检索相关数据。
六、代码实现
? ? ? ?在项目开发之前,确保正确设置环境以及安装好必要的库:
6.1 安装transformers库
? ? ? ?Hugging Face的transformer库是使用Llama-2等模型的基石,它为自然语言处理任务提供了对预先训练的模型和实用程序的轻松访问。
pip install transformers? ? ? ?此命令安装transformer库的最新版本,其中包括加载和使用Llama-2模型所需的功能。
6.2 安装PgVector
? ? ? ?PgVector是PostgreSQL的扩展,有助于有效处理矢量数据。这对于管理LLM中使用的嵌入和实现快速检索操作尤为重要。
下载PostgreSQL
? ? ? ? 访问PostgreSQL官方网站(https://www.postgresql.org/download/)并为您的操作系统选择适当的版本。PostgreSQL兼容各种平台,包括Windows、macOS和Linux。
? ? ? 首先,确保PostgreSQL已安装并在您的系统上运行。然后,安装PgVector扩展:
pip install pgvector? ? ? ?安装后,您需要创建一个PostgreSQL数据库,并在其中启用PgVector扩展:
CREATE DATABASE ragdb;\c ragdbCREATE EXTENSION pgvector;
? ? ? 此SQL命令序列创建一个名为ragdb的新数据库,并激活其中的PgVector扩展。
6.3 安装LlamaIndex库
? ? ? ?LlamaIndex是专门为索引和检索矢量数据而设计的,使其成为RAG管道的重要组成部分。
pip install llama-index? ? ? ?此命令安装LlamaIndex库,使您能够为矢量数据创建和管理索引。
RAG Pipeline如下图所示:
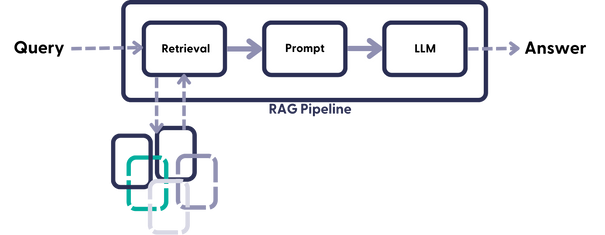
? ? ? ?构建LLM RAG管道包括几个步骤:初始化Llama-2进行语言处理,使用PgVector建立PostgreSQL数据库进行矢量数据管理,以及创建集成LlamaIndex的函数以将文本转换和存储为矢量。
6.4 初始化Llama-2
? ? ? 构建RAG管道的第一步包括使用Transformers库初始化Llama-2模型。这个过程包括建立模型及其标记器,这对编码和解码文本至关重要。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM??# Load the tokenizer and modeltokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")model = AutoModelForSeq2SeqLM.from_pretrained("meta-llama/Llama-2-7b-hf")
? ? ? ?在这个片段中,我们从llama-2包中导入LlamaModel,并使用特定的模型变体(例如“llama2-large”)对其进行初始化,该模型将用于文本生成和矢量化。
6.5 设置PgVector
? ? ? ?一旦模型准备就绪,下一步就是建立PgVector数据库,用于存储和检索矢量化数据。
PostgreSQL数据库设置:
安装PostgreSQL:确保PostgreSQL已安装并正在运行。
创建数据库并启用PgVector:
CREATE DATABASE ragdb;\c ragdbCREATE EXTENSION pgvector;
用于数据库交互的Python代码:
import psycopg2?# Connect to the PostgreSQL databaseconn = psycopg2.connect(dbname="ragdb", user="yourusername", password="yourpassword")?# Create a table for storing embeddingscursor = conn.cursor()cursor.execute("CREATE TABLE embeddings (id serial PRIMARY KEY, vector vector(512));")conn.commit()
? ? ? ?这段代码创建了一个到PostgreSQL数据库的连接,并设置了一个用于存储嵌入的表。矢量(512)数据类型是一个例子;可以根据模型的输出调整大小。
6.6 数据准备
? ? ? ?对于这个例子,让我们使用一个与可再生能源相关的科学摘要的简单数据集。数据集由摘要列表组成,每个摘要都是一个字符串。
data = ["Advances in solar panel efficiency have led to a significant reduction in cost.","Wind turbines have become a major source of renewable energy in the past decade.","The development of safer nuclear reactors opens newpossibilities for clean energy.",# Add more abstracts as needed]
6.7 生成嵌入
? ? ? ?要从这些数据生成嵌入,我们首先需要加载Llama-2模型,并通过它处理每个抽象。
安装要求:
pip install torch安装完torch后,执行以下代码。
from transformers import AutoTokenizer, AutoModelimport torch?# Initialize the model and tokenizertokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")model = AutoModel.from_pretrained("meta-llama/Llama-2-7b-hf")??def generate_embeddings(text):inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512)with torch.no_grad():outputs = model(**inputs)return outputs.last_hidden_state.mean(dim=1).numpy()?# Generate embeddings for each abstractembeddings = [generate_embeddings(abstract) for abstract in data]
? ? ? ?此函数通过Llama-2模型处理每个抽象,以生成嵌入,然后将嵌入存储在列表中。
6.8 使用LlamaIndex索引数据
? ? ? 嵌入准备好后,我们现在可以使用LlamaIndex对它们进行索引。这一步骤对于以后实现高效检索至关重要。
import numpy as npfrom llama_index import VectorStoreIndex??# Convert the list of embeddings to a NumPy arrayembeddings_array = np.vstack(embeddings)?# Create an index for these embeddingsindex = VectorStoreIndex.from_documents(documents, service_context=embeddings_array)
? ? ? ?此代码块将嵌入列表转换为NumPy数组,然后使用LlamaIndex创建一个名为“energy_abstracts_index”的索引。
6.9 与PostgreSQL集成
? ? ? ?最后,为了将其与PostgreSQL数据库集成(假设您已经如前所述使用PgVector进行了设置),您可以将这些嵌入存储在数据库中。
安装要求:
pip install psycopg2? ? ? ? ? 安装“psycopg2”后,实现以下代码以将嵌入存储在数据库中。
import psycopg2?# Connect to your PostgreSQL databaseconn = psycopg2.connect(dbname="ragdb", user="yourusername", password="yourpassword")cursor = conn.cursor()?# Store each embedding in the databasefor i, embedding in enumerate(embeddings_array):cursor.execute("INSERT INTO embeddings (id, vector) VALUES (%s, %s)", (i, embedding))conn.commit()
? ? ? 在这个片段中,我们有一个示例文本的列表。我们循环遍历每个文本,index_document函数将文本转换为向量并将其存储在数据库中。
6.10 集成RAG管道
? ? ? 设置好各个组件后,将它们集成到检索增强生成(RAG)管道中是最后一步。这包括创建一个系统来处理查询,从数据库中检索相关信息,使用Llama-2模型生成响应。
创建RAG查询函数
? ? ? ?RAG Pipeline的核心是一个函数,它接受用户查询,从数据库中检索相关上下文,并基于查询和检索到的上下文生成响应。
def your_retrieval_condition(query_embedding, threshold=0.7):# Convert query embedding to a string format for SQL queryquery_embedding_str = ','.join(map(str, query_embedding.tolist()))?# SQL condition for cosine similaritycondition = f"cosine_similarity(vector, ARRAY[{query_embedding_str}]) > {threshold}"return condition
? ? ? ?现在,让我们将这个自定义检索逻辑集成到我们的RAG管道中:
def rag_query(query):# Tokenize and encode the queryinput_ids = tokenizer.encode(query, return_tensors='pt')?# Generate query embeddingquery_embedding = generate_embeddings(query)?# Retrieve relevant embeddings from the databaseretrieval_condition = your_retrieval_condition(query_embedding)cursor.execute(f"SELECT vector FROM embeddings WHERE {retrieval_condition}")retrieved_embeddings = cursor.fetchall()?# Convert the retrieved embeddings into a tensorretrieved_embeddings_tensor = torch.tensor([emb[0] for emb in retrieved_embeddings])?# Combine the retrieved embeddings with the input_ids for the model# (This step may vary based on your model's requirements)combined_input = torch.cat((input_ids, retrieved_embeddings_tensor), dim=0)?# Generate the responsegenerated_response = model.generate(combined_input, max_length=512)return tokenizer.decode(generated_response[0], skip_special_tokens=True)
? ? ? 让我们看看我们的RAG管道将如何与示例查询一起工作:
query = "What are the latest advancements in renewable energy?"response = rag_query(query)print("Response:", response)
? ? ? ?在这种情况下,管道检索与“可再生能源”进步相关的上下文,将其与查询相结合,并生成全面的响应。
七、结论
? ? ? ?利用Llama-2、PgVector和LlamaIndex构建LLM-RAG管道,为NLP领域开辟了一个可能性领域。这个管道不仅可以理解和生成文本,而且还利用庞大的信息数据库来增强其响应,使其在聊天机器人、推荐系统等各种应用程序中具有难以置信的强大功能。
? ? ? ?然而,旅程并没有就此结束。NLP的世界正在迅速发展,保持最新趋势和技术的更新至关重要。这里讨论的实现是进入更广泛、更复杂的语言理解和生成世界的垫脚石。不断试验,不断学习,最重要的是不断创新。
参考文献:
[1]?https://medium.com/@shaikhrayyan123/how-to-build-an-llm-rag-pipeline-with-llama-2-pgvector-and-llamaindex-4494b54eb17d
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【设计模式】原型模式
- 切分大文件sql为小份
- 漏洞复现-泛微OA xmlrpcServlet接口任意文件读取漏洞(附漏洞检测脚本)
- 《剑指offer》 递归和循环第三题:变态跳台阶
- 8. 自定义分页
- 这款软件轻松解决你图片水印问题
- Exploring Kubernetes: Unveiling a New Era of Container Orchestration
- AI 和 XR:将扩展现实体验带给千家万户
- Bowtie2数据比对教程
- 调试ad5245的总结