Python_xpath_解析
发布时间:2023年12月30日
目录
一、xpath的安装
二、xpath的基本使用
xpath解析:
1.本地文件? ? ? ? ? ? ? ? etree.parse()
2.服务器响应的数据 response.read().decode('utf-8')? ? ?常用? ? ? ? ? etree.HTML()
?1.路径查询
//:查找所有子孙节点,不考虑层级关系
/:查找子节点,考虑层级关系

?
?2.谓词查询
//div[@id]
//div[@id="maincontent"]



?
?
3.属性查询
//@class

 ?
?
4.模糊查询
//div[contains(@id,"he")]
//div[starts-with(@id."he")]

?

 ?
?
5.内容查询
//div/h1/text()
6.逻辑查询
//div[@id="head" and @class="s_down"]
//title | //price



from lxml import etree
#xpth解析本地文件
tree = etree.parse('xpth本地案例.html')
# tree.xpath('xpath路径')
#查找ul下面的li
# li_list = tree.xpath('//body/ul/li')
#查找所有有id的属性的li标签
#text()获取标签中的内容
#li_list = tree.xpath('//ul/li[@id]/text()')
#查找id为l1的li标签a
#注意引号的问题
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
#查找到id为l1的li标签的class的属性值
# li = tree.xpath('//ul/li[@id="l1"]/@class')
#查询id中包含l的li标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
#查找id中以c开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
#查询id为l1和class为c1的标签
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
#判断列表的长度
# print(len(li))
# print(li)
#判断列表的长度
print(len(li_list))
print(li_list)7.解析_获取百度一下?
xpath的返回值是一个列表类型的数据,可以通过列表的下标来访问数据

#(1) 获取网页的源码
#(2) 解析 解析的服务器相响应的文件 etree.HTML
#(3) 打印
import urllib.request
url = 'https://www.baidu.com/'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.82'
}
#请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
#模拟浏览器访问服务器
response = urllib.request.urlopen(request)
#获取网页源码
content = response.read().decode('utf-8')
#解析网页源码来获取想要的数据
from lxml import etree
#解析服务器响应的文件
tree = etree.HTML(content)
#获取想要的数据 xpath的返回值是一个列表
result = tree.xpath('//input[@id="su"]/@value')
#打印数据
print(result)8.解析_站长素材
风景图片、风景图片大全、山水风景图片、风景图片桌面、唯美风景图片 (chinaz.com)
这里需要注意的是,pycharm获取的网页源码和网站的源码可能不一样,所以在查询内容的时候要注意是否跟网页源码一样,如果没有识别出来可以在pycharm中打印网页源码。
# (1)请求对象的定制
# (2)获取网页源码
# (3)下载
#需求 下载前十页的图片
# https://sc.chinaz.com/tupian/fengjing.html 第一页
# https://sc.chinaz.com/tupian/fengjing_2.html 第二页
# https://sc.chinaz.com/tupian/fengjing_3.html 第三页
import urllib.request
from lxml import etree
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/fengjing.html'
else:
url = 'https://sc.chinaz.com/tupian/fengjing_'+str(page)+'.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.82'
}
request = urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
#下载图片
#urllib.request.urlretrieve("图片地址","文件名字")
tree = etree.HTML(content)
name_list = tree.xpath('//div[@class="tupian-list com-img-txt-list"]//img/@alt')
src_list = tree.xpath('//div[@class="tupian-list com-img-txt-list"]//img/@data-original')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:'+src
urllib.request.urlretrieve(url=url,filename='./screen/'+ name+'.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page,end_page+1):
# (1)请求对象的定制
request = create_request(page)
# (2)获取网页源码
content = get_content(request)
# (3)下载
down_load(content)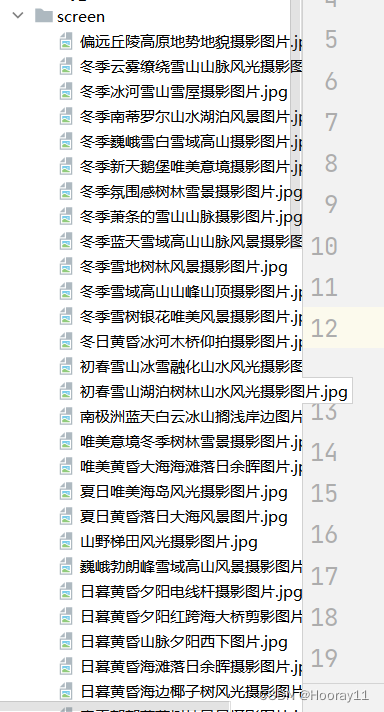
文章来源:https://blog.csdn.net/Hooray11/article/details/134789745
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!