python 爬虫 request get或post传参
发布时间:2024年01月10日
爬虫传参
import requests
url = 'http://www.xxx'
# get 或 post 传参数据
data = {
"pageNo": 1652,
"pageSize": 10,
}
headers = {
'Cookie': '',
'Host': '',
'Origin': '',
'Referer': '',
'User-Agent': '',
}
# get 请求
# res = requests.get(
# url,
# params=data,
# headers=headers,
# )
# post 请求
res = requests.post(
url,
data=data,
headers=headers,
)
print(res.content.decode('utf-8'))
post 传参的请求可从浏览器复制字典粘贴。
header 请求头参数,提供如下工具脚本:
把请求头参数复制到content.txt 文件中
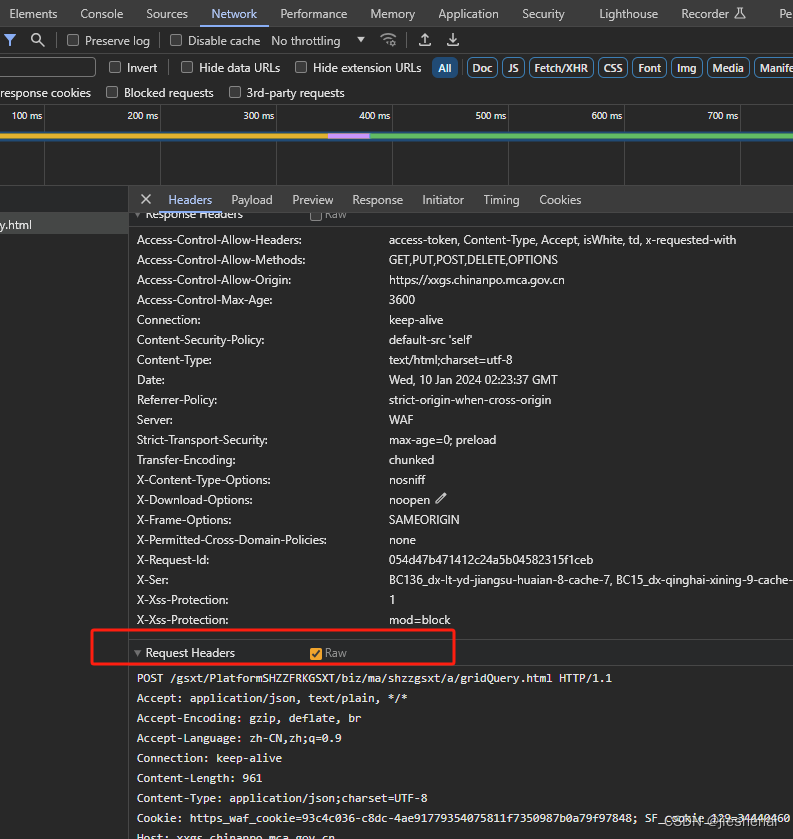
content.txt:
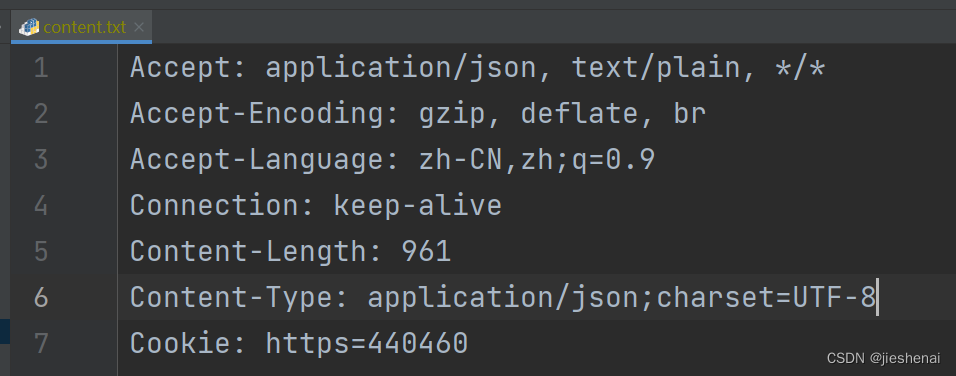
工具:
# 假设txt文件内容如下
txt = open('content.txt').read()
# 使用splitlines()方法将txt内容分割为行,然后使用json.loads()方法将每一行转换为字典
lines = txt.splitlines()
data = [line.split(': ') for line in lines]
headers_dict = {k: v for k, v in data}
# 输出字典
print(headers_dict)
文章来源:https://blog.csdn.net/sjxgghg/article/details/135496984
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 5.向量点乘
- 虚拟机安装intel架构的银河麒麟V10(SP1)
- 水仙花数代码(C++11)
- Goby 漏洞发布| Apache OFBiz webtools/control/ProgramExport 远程代码执行漏洞(CVE-2023-51467)
- Python中通过字符串访问与修改局部变量
- 关于java数组的声明及创建
- 工厂设计模式看这一篇就够了
- vue3 require is not defined
- Http---URL
- 静态网页设计——红旗汽车官网(HTML+CSS+JavaScript)