Multi-bit的实现方法和应用 (上)
在两年前的一篇文章简单介绍了Multi-bit的一些基本知识,详情请戳:芯片设计里的Multi-Bit FF探究
在此篇旧文的基础上,其实MBFF (Multi-bit FF)还有不少技术细节值得再次学习和理解。据此,这里再次把MBFF相关的技术和流程相关的细节梳理的更为清晰一些。闲言少叙,ICer GO!

MBFF是中后端设计实现常用的手段,这里结合中后端流程,来探讨MBFF的优势和使用策略。
MBFF的优势和劣势
MBFF是把数个single bit FF(SBFF)被封装(banking/merge)到一个MBFF上,对时序优化有一些影响,具体见下:
- 面积优势
在std-cell构画的时候,进行逻辑共享,面积有明显提升

- 功耗优势:由于gate级别的整合,在面积提升的基础上,功耗也有明显收益
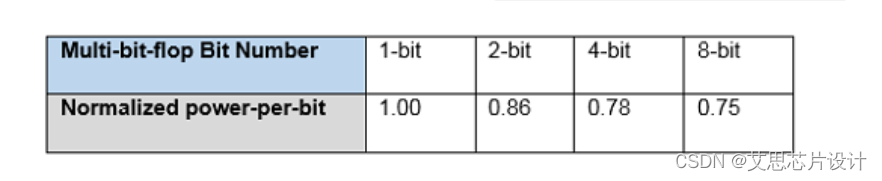
- 时序劣势:
下图示例了SBFF到MBFF的物理布局的转变
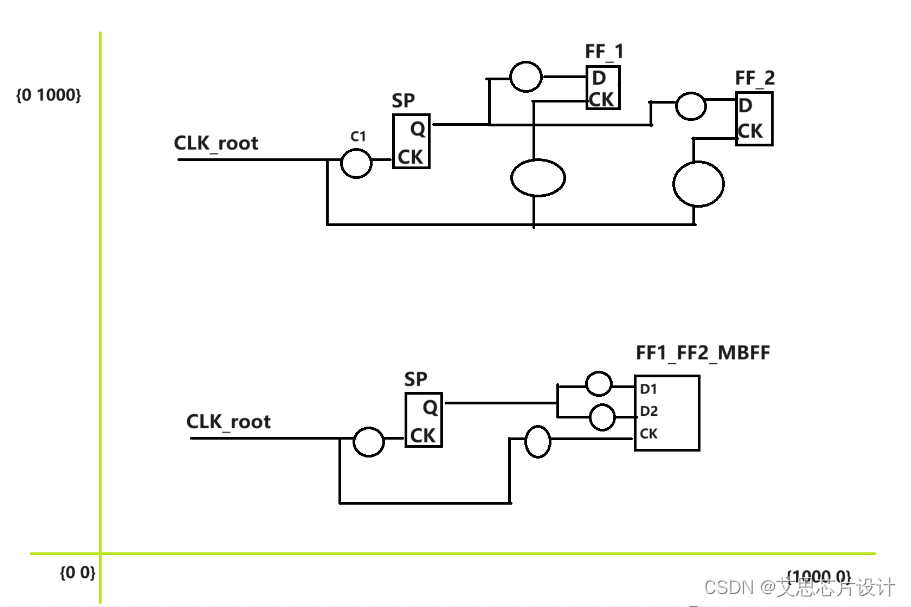
- SBFF被封装成MBFF后,数据路径的终点会改变,可以变近(如上图FF2),也可能变远(如上图FF1),setup/hold会有变化
- SBFF被封装成MBFF后,时钟路径的终点会整合,不能像SBFF对每个单独的SBFF的时钟路径灵活使用useful skew进行精细控制
虽然PPA的优化,MBFF二对一胜出,但是实际情况确实,在中后端几十年以来的timing_driven 实现策略确实这个天平不可忽略的重要因素。具体范例和冲突,本文后面也会单独讨论
MBFF的封装方式
基于MBFF的特性,在整个中后端设计流程中,用户可以在三个地方有选择的进行MBFF的封装操作
- RTL阶段
- 综合阶段
- APR阶段
RTL阶段的MBFF封装
基于中后端设计流程,MBFF的第一个入口是RTL,DC用户可以通过synopsys原语来知道DC对RTL相应的设计进行MBFF的构建。PS:并非显性地(explicit)在RTL中例化MBFF,这样会对设计人员带来很大的约束,也不利于后面的流程。
- RTL指定MB封装
原语:synpsys infer_multibit REG_NAME

在DC的默认配置下,elaborate命令执行的时候,会对上述设计以及原语解析,会对应输出下列日志:

上述日志表达了两个意思:
- 使用原语的q0:
synopsys infer_multibit "q0",被封装成了MBFF。(当然需要满足前文所述的MBFF逻辑设计要求) - 未使用原语的q1,并未被封装成了MBFF。(即便满足前文所述的MBFF逻辑设计要求)
这里S家也贴心的给中端工程师提供了一个配置供选择。
用户通过变量hdlin_infer_multibit来控制DC elaborate的对应操作。

这个变量有三个选项:
default_none:DC仅仅根据RTL里边的原语infer_multibit进行MBFF识别。如果没有碰到,就不转化MBFF。PS:这个是DC的默认设置。前提是RTL设计人员需要使用原语进行MBFF指定,否则In-compile MBFF flow无法实现MBFF的封装。具体细节见后续描述default_all: DC根据RTL代码的逻辑连接关系,主动地去做MBFF的识别,无论是不是使用原语infer_multibit,DC都会根据逻辑连接关系,尽量进行MBFF的封装,除非DC遇到禁止MBFF封装的原语(后文会提供细节)。never:DC工具忽略infer_multibit原语,也不主动去封装MBFF,所以,在elaborate命令下,不会有任何的MBFF封装动作发生
下图截取了三个不同配置下,elaborate命令的日志,MB列的结果有不同

S家为了配合上述变量的灵活使用,当hdlin_infer_multibit配置成default_all的时候,可以使用原语dont_infer_multibit进行排外处理:所有定义这个原语的寄存器,即便用户使用了 hdlin_infer_multibit=default_all的配置,elaborate的时候,也不会对dont_infer_multibit指定寄存器进行MBFF的封装。
如下图示例的q1,即便用户已经使用了default_all,这里在elaborate时,仍然没有发生MB的封装

综合阶段的MBFF封装
RTL的MBFF是通过简单的原语来进行MBFF封装指定(infer_multibit)或者MBFF封装排外指定(dont_infer_multibit)。
除过elaborate对MBFF进行未映射( unmapped)级别的封装,综合流程主要还是通过compile等命令来进行MBFF的映射(mapped)实现的。
无论是RTL使用原语对MBFF进行指定,抑或使用hdlin_infer_multibit=default_all进行MBFF识别,任何在elaborate阶段的FF,只有存在MB==Y的情形,才是有可能在后期通过compile命令完成MBFF的封装,譬如下图的q0_reg,在compile命令执行中,才是有可能被映射实现成MBFF的

Compile步骤里边,通常有两种方式进行MBFF的映射实现(mapped)。
- In-compile MBFF实现:基于数据库的形态,使用compile 命令,直接进行MBFF的映射实现
- In-place MBFF实现:基于DCT的物理布局数据,对距离相近的FF进行MBFF的封装实现(banking)
这两种方法各有优缺,这里一起来看一下
In-compile MBFF实现
Compile命令,通过下列命令set_multibit_options对MBFF的实现进行配置,已完成从unmapped MBFF到真实的MBFF的实现
PS:顾名思义,这个步骤也需要目标工艺库提供MBFF的支持,因为在elaborate的时候,只是一个基于逻辑的MBFF评判,最终的实现还是在compile挂靠工艺库的操作

default: 将所有的MBFF的优化配置恢复为defaultexclude_registers_with_timing_exceptions: 设置为true时,对所有带有timing exception的寄存器跳过MBFF的映射实现mode:MBFF的模式选择,有下列四种模式可供选择none:compile命令中跳过MBFF封装non_timing_driven:无论时序好坏,工具尽可能的去做MBFF,这样实现的MBFF的比率最高timing_driven:时序驱动的方式去做MBFF映射实现,最后的结果是timing 得到保障的情况下,面积也可以得到了优化timing_only:仅仅时序驱动的方式,时序会最优解,但是面积可能不是最优化的结果。
ignore_timing_exception: 当exclude_registers_with_timing_exceptions== true的时候,在进行MBFF映射实现的时候,对指定的timing_exception的类型可以进行MBFF的映射,相当于对exclude_registers_with_timing_exceptions选项的一个二次细化。目前支持GROUP_PATH, FALSE_PATH, MULTI_CYCLE_PATH, MIN_DELAY, MAX_DELAY等五类。譬如:
set_multibit_options \
exclude_registers_with_timing_exceptions true \
ignore_timing_exception FALSE_PATH
是对除过FALSE_PATH 的其他所有拥有timing exception的SBFF跳过MBFF映射实现。言下之意就是拥有FALSE_PATH 的SBFF会被封装实现为MBFF。
critical_range: 当时序驱动模式打开时,这里定义的时序范围都被考量,这个和group_path里的critical_range类似path_group:当时序驱动模式打开时,只有这里指定的path_group被考虑。如果不定义这个选项,则所有的path_group都被考虑
所以,一个实现MBFF的compile命令类似下例:
dc_shell> set_multibit_options -mode timing_driven
dc_shell> compile_ultra -gate_clock -scan
compile结束后,可以通过命令report_multibit_banking查看MBFF的替换结果统计

对于MBFF的替换计算,这里设定,
MBFF_cnt(n): 拥有n-bit宽度的MBFF的instance数量SBFF_cnt:拥有single-bit的SBFF的instance数量Total_bit_cnt: 所有的SBFF和MBFF折算成SBFF对应的bit数。这个也就是数据库在不采用MBFF flow的时候的全部FF的数量MBFF_ratio: 所有的MBFF对应SBFF的数量占比
推导出:
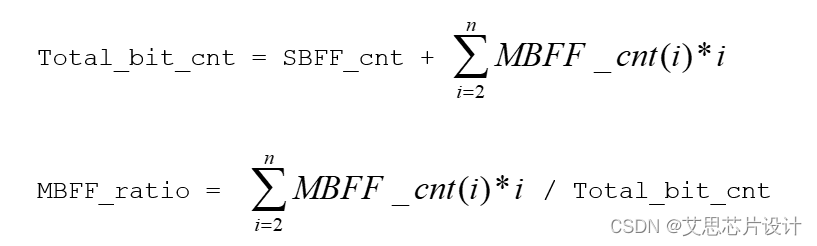
综上,衡量一个数据库的MBFF的占比主要是MBFF_ratio这个值,这个值越高,说明数据库中被封装成MBFF的FF越多,相应获得的面积/功耗收益就越大。PS:由于MBFF的类型较多,分别有2、4、8bit等,单纯查看MBFF的instance数量是不全面的。
未完待续…
【敲黑板划重点】

MBFF对PPA有较大贡献,也是现在std-cell的标准交付器件,充分理解MBFF的实现方法和手段,对整个前端、中后端的设计实现会提供很大的灵活性和可控性,无论时设计人员还是实现人员,都是工作中的必备技能。
参考资料
Synopsys Design Compiler? User Guide
Synopsys Multibit Register Synthesis and Physical Implementation Application Note
艾思考后端实现 芯片设计里的Multi-Bit FF探究
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!