功能真强大!5个令人惊叹的 Jupyter 黑科技
Jupyter 是一种功能强大的交互式计算环境,被广泛应用于数据分析、机器学习、科学计算等领域。
除了常见的基本功能外,Jupyter还隐藏着许多令人惊叹的黑科技,这些功能可以帮助用户更高效地完成工作,提升工作体验。
在本文中,我来总结了5个Jupyter黑科技,与大家分享
按照老规矩,如果你觉得这篇文章对你有所帮助,欢迎点个赞、收藏
GUI自动生成代码Visual Python
VisualPython是一个开源项目,它是一款基于图形界面(GUI)的 「Python代码生成器」,在 Jupyter Notebook 上作为扩展插件使用。
VisualPython的初衷是为那些在数据科学课程中为编码而苦苦挣扎的学生而开发。对于程序员而言,使用该工具可以保存和重用用户代码;非程序员使用该工具,可以更轻松地学习 Python 语言,以最少的编码技能探索和利用数据科学解决实际问题。
主要特征包括:
-
基于图形界面自动生成 Python 代码。
-
可以按任务创建代码块,如数据处理任务、可视化任务等。
-
可以将分析过程导出为 .vp 文件与他人共享。
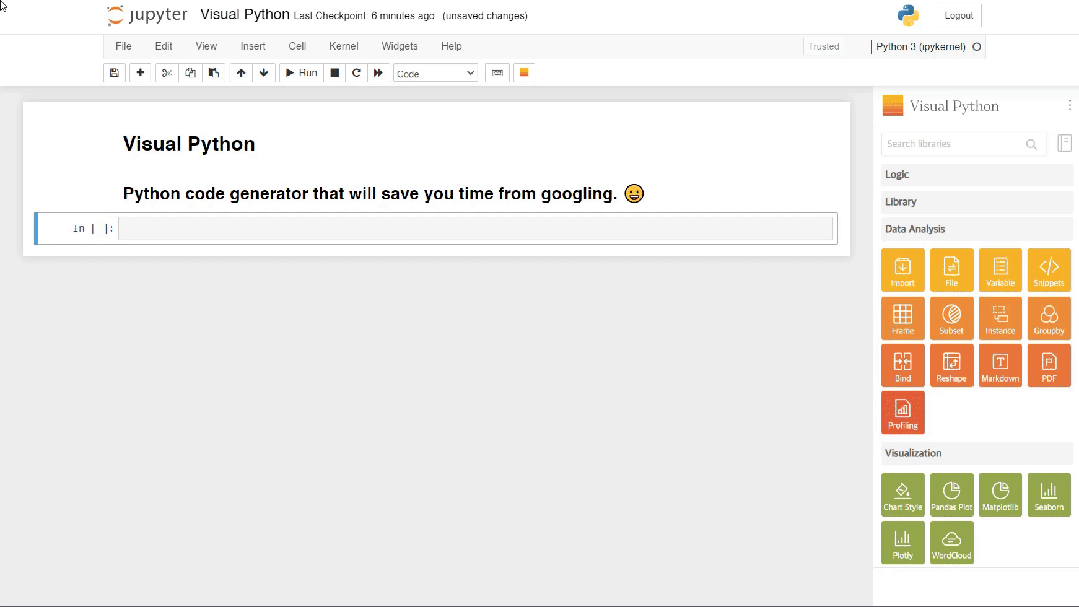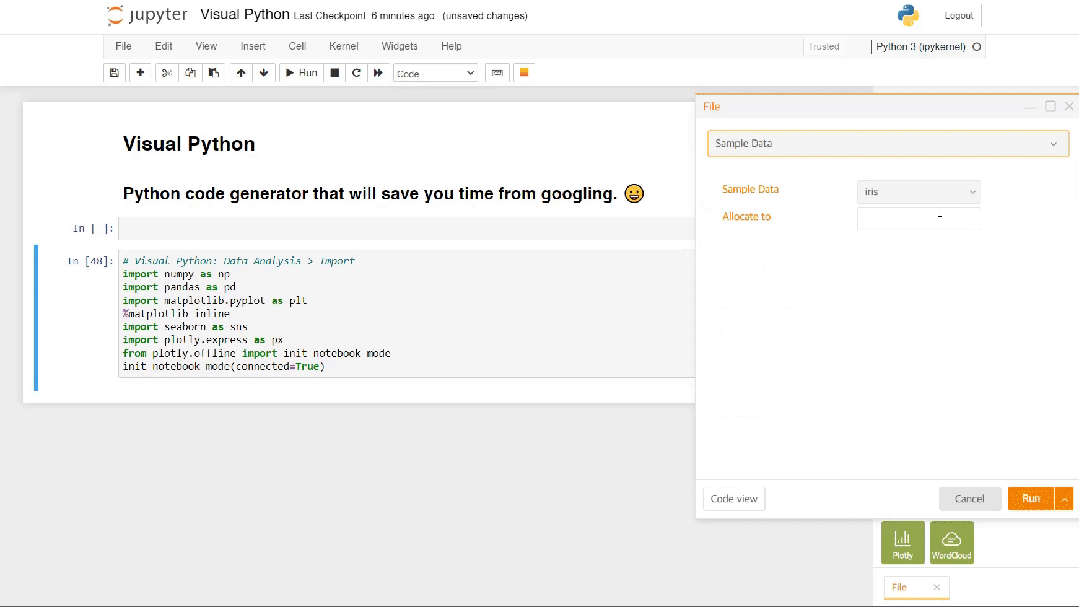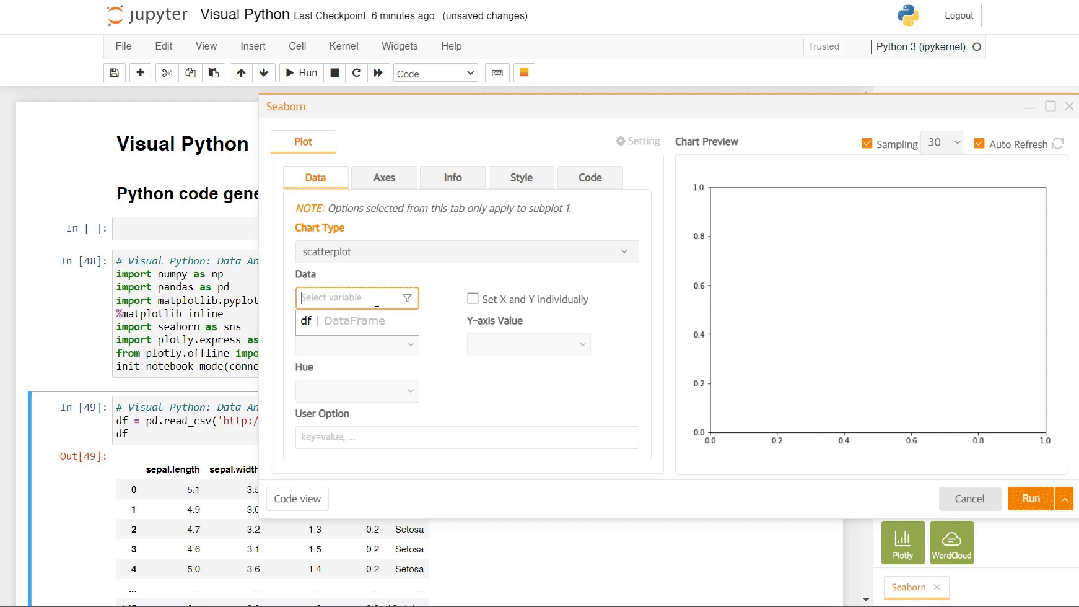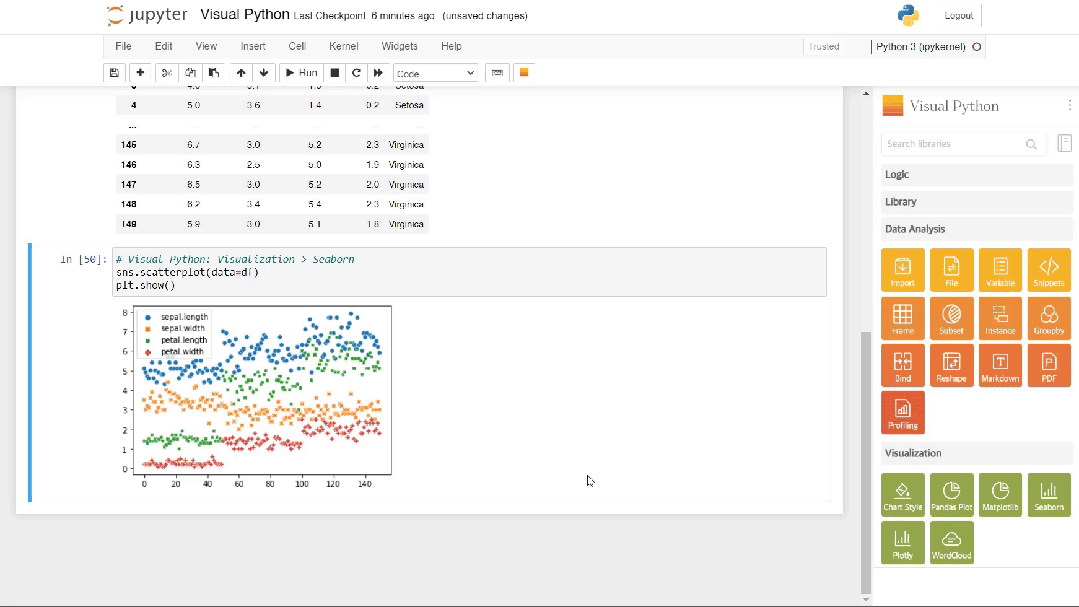
Jupyter Notebook环境安装并激活visualpython,即可看到开发界面工具栏的最右边多了一个黄色的小方块按钮,这个小方块就是Visual Python提供的功能。点击黄色的小方块即可直接进入到无代码的拖拽式开发页面了,代码开发页面和组件拖拽会同时出现在编辑页面中。如下图所示。
技术交流
独学而无优则孤陋而寡闻,技术要学会交流、分享,不建议闭门造车。
好的文章离不开朋友之间的分享、推荐,记得点赞支持。
资料干货、技术答疑、数据&源码,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:Python学习与数据挖掘,后台回复:技术交流
方式②、添加微信号:dkl88194,备注:技术交流
我们打造了《100个超强算法模型》,特点:从0到1轻松学习,原理、代码、案例应有尽有,所有的算法模型都是按照这样的节奏进行表述,所以是一套完完整整的案例库。
很多初学者是有这么一个痛点,就是案例,案例的完整性直接影响同学的兴致。因此,我整理了 100个最常见的算法模型,在你的学习路上助推一把!

编Pandas代码时生成有用的提示
使用未优化的pandas通常会减慢数据分析速度,此时可以使用Dovpanda工具,提供有关数据操作步骤的建议或警告。

Jupyter单元格执行完成后获取通知
在Jupyter单元格中运行一些代码后,经常会导航到其他工作区。此时,必须不断返回Jupyter标签,以检查单元格是否已执行。
为了避免这种情况的发生,则可以使用jupyternotify中的%%notify魔法命令在浏览器通知用户Jupyter单元格的执行情况。这对于长时间运行的代码或者需要监控执行情况的代码来说非常方便。
每当单元格完成其执行时,将收到以下通知,单击通知又可以回到Jupyter标签。
深入挖掘数据信息
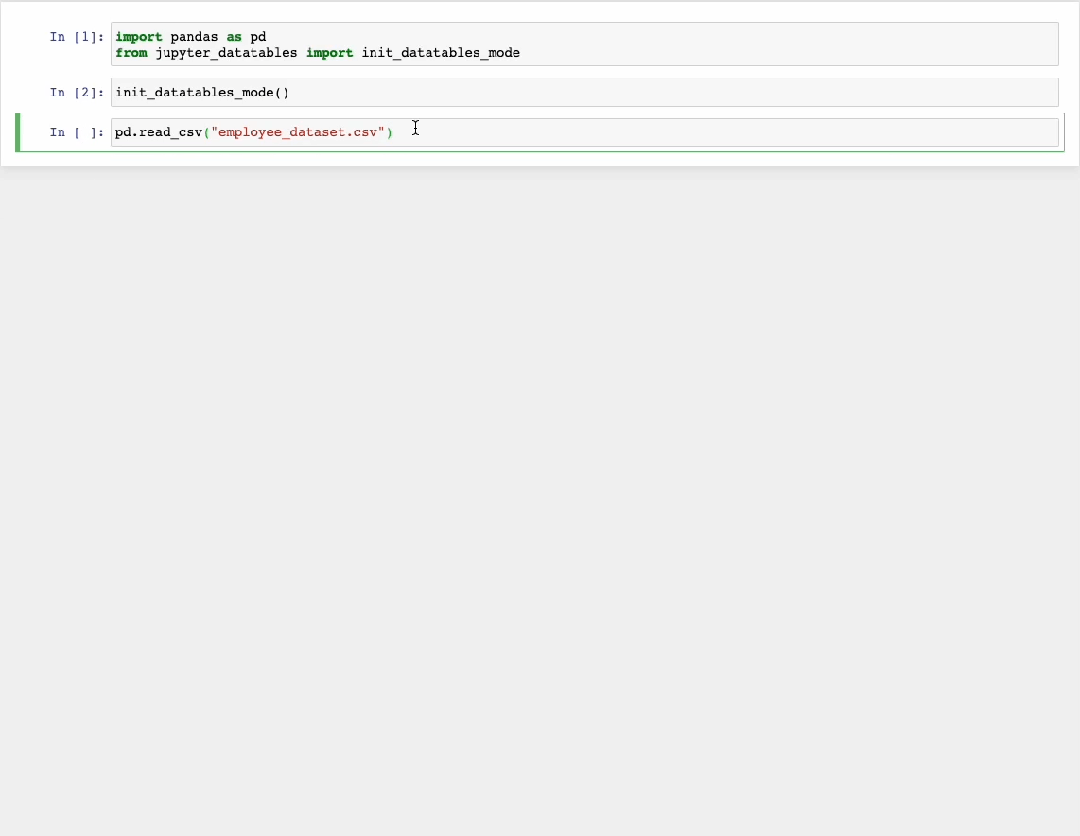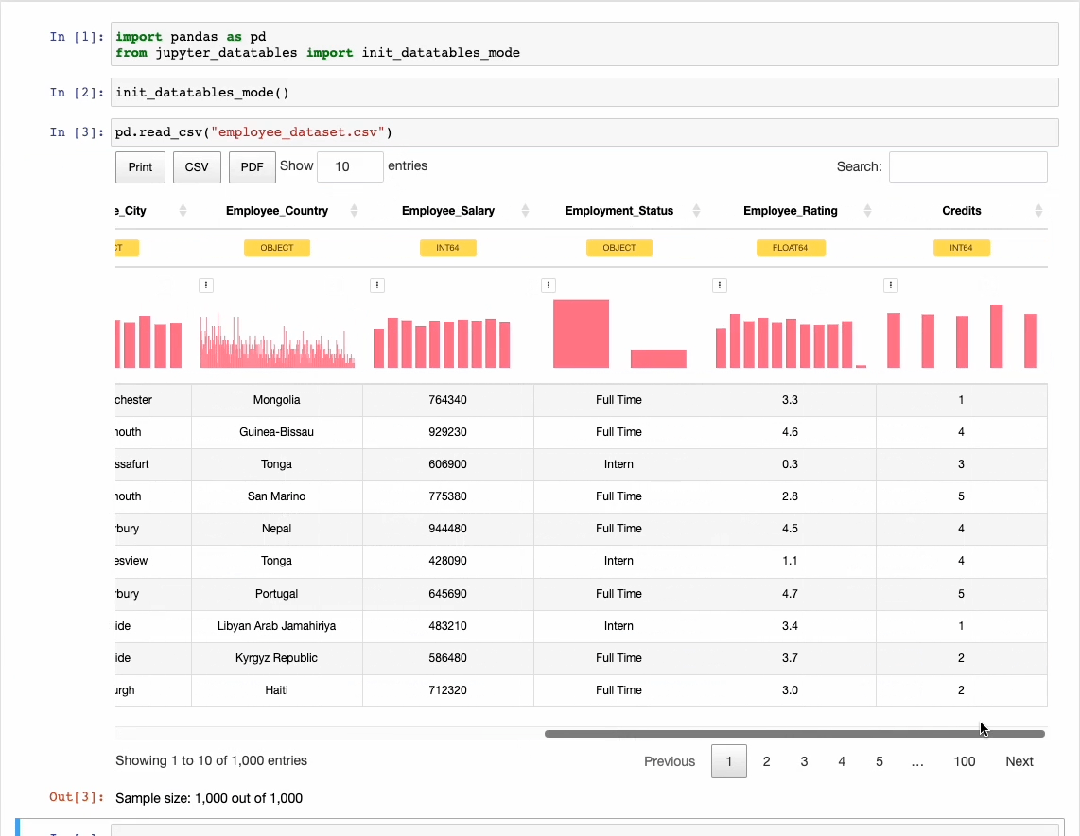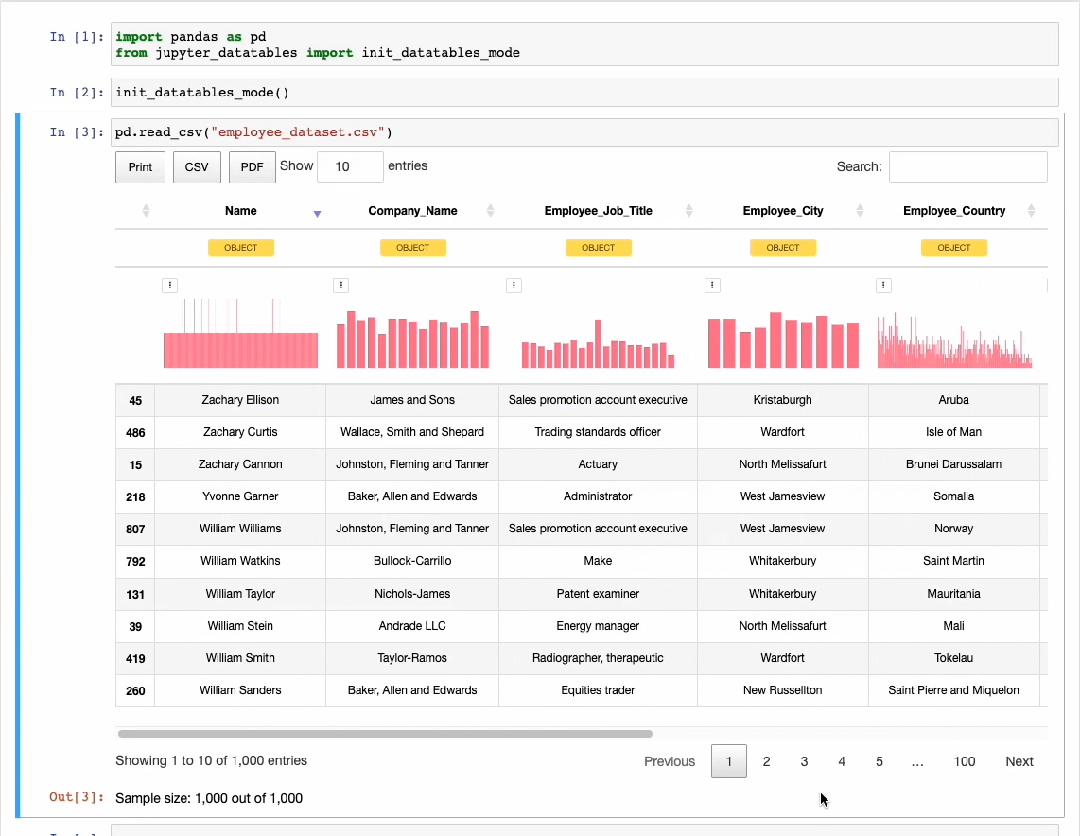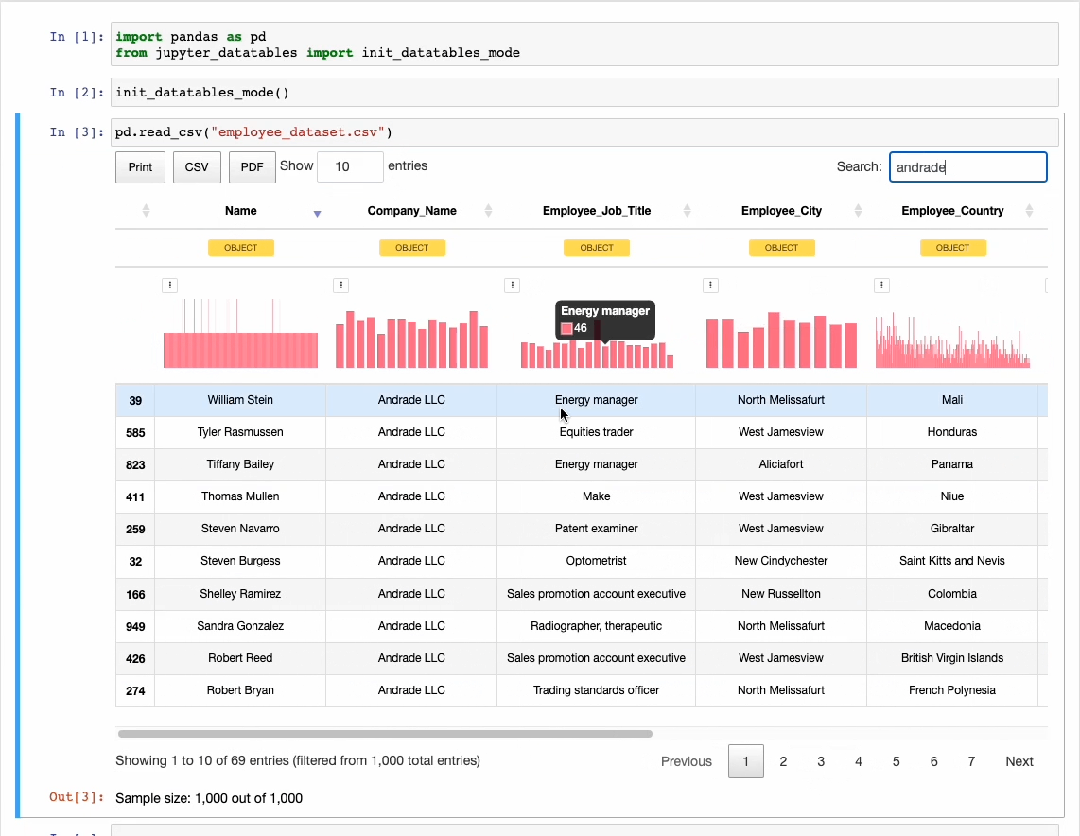
通常,在Jupyter中加载DataFrame时,会打印预览数据,如下所示:
然而,它几乎没有告诉我们数据内部的任何信息。此时,可以使用Jupyter-DataTables深入挖掘数据信息。如下图所示,通过预览可以看到排序、过滤、导出和分页操作等数据信息。
一键标记数据
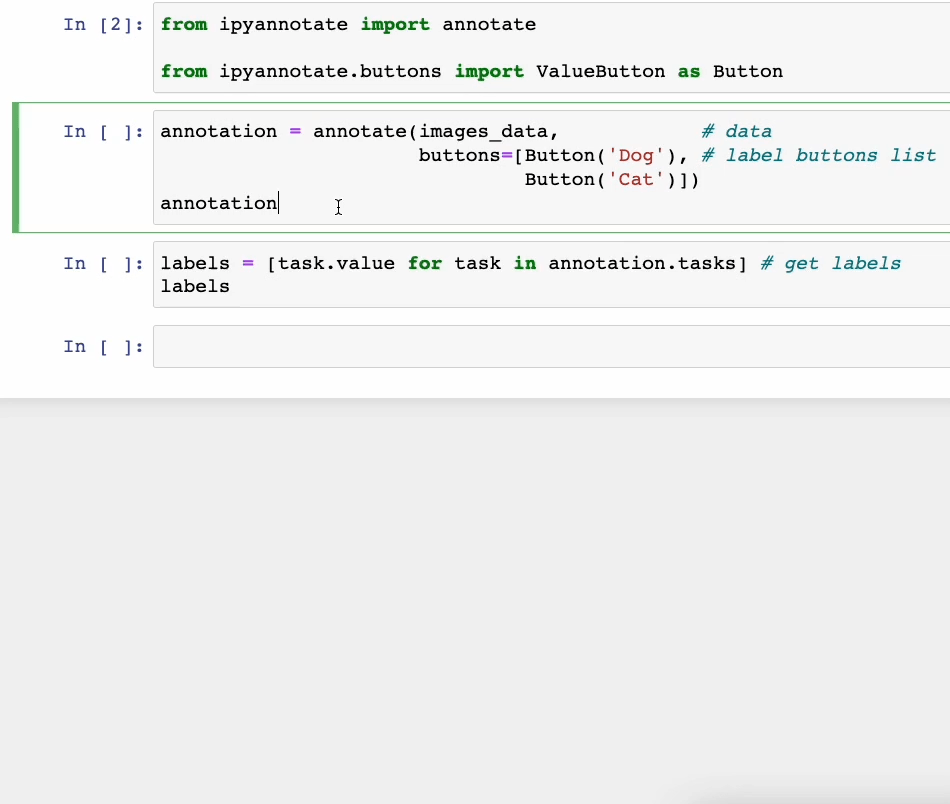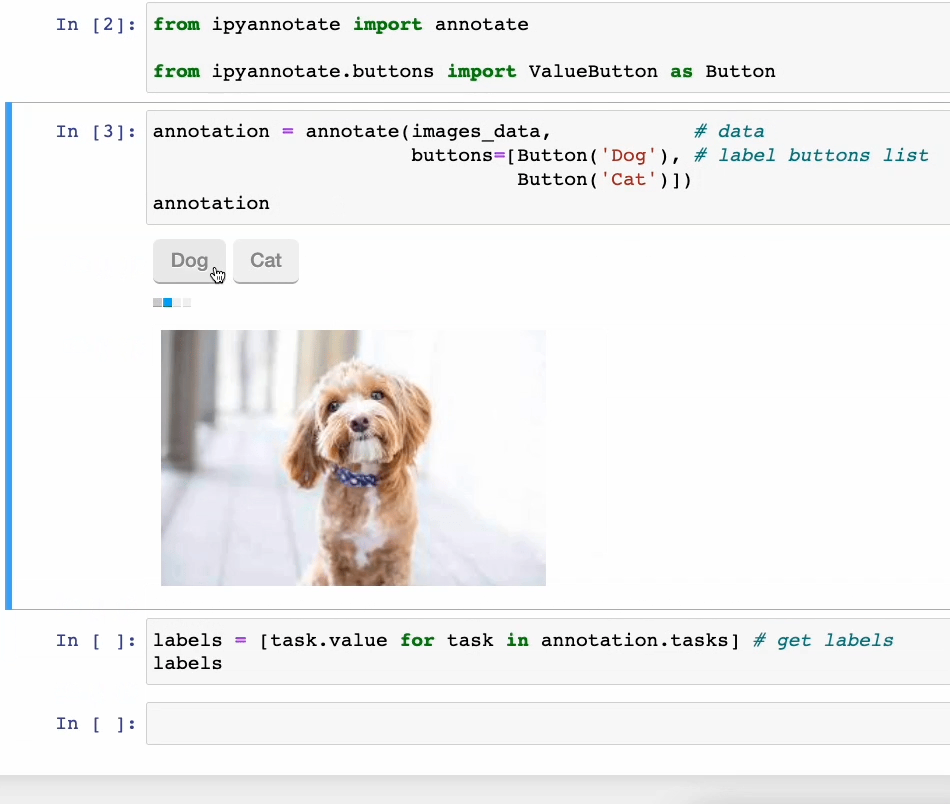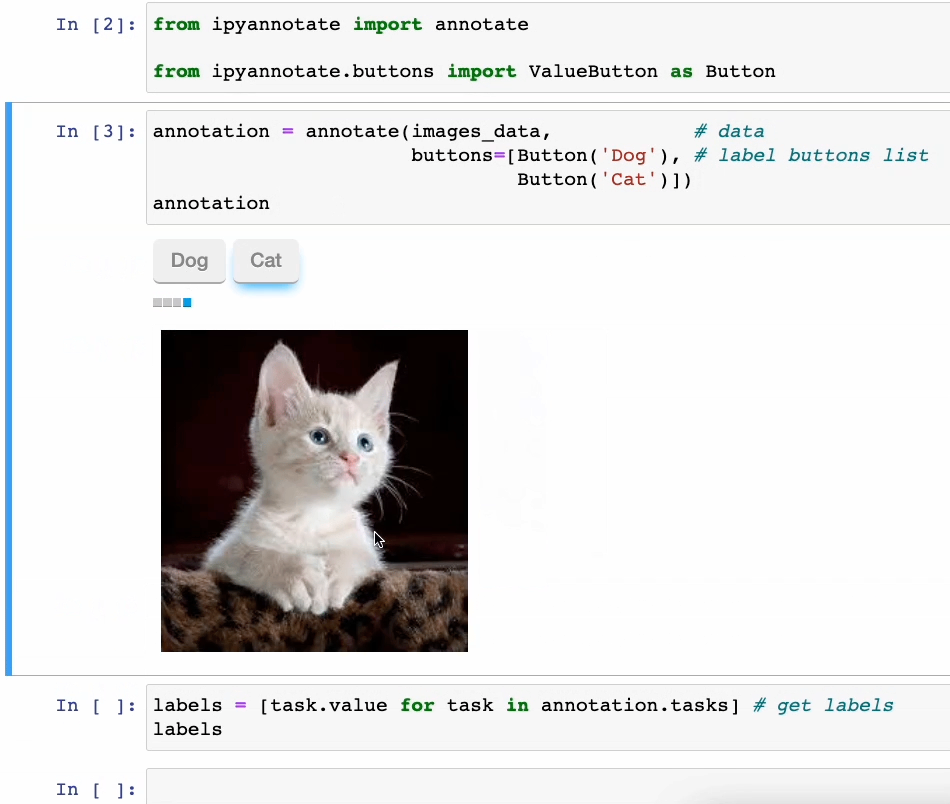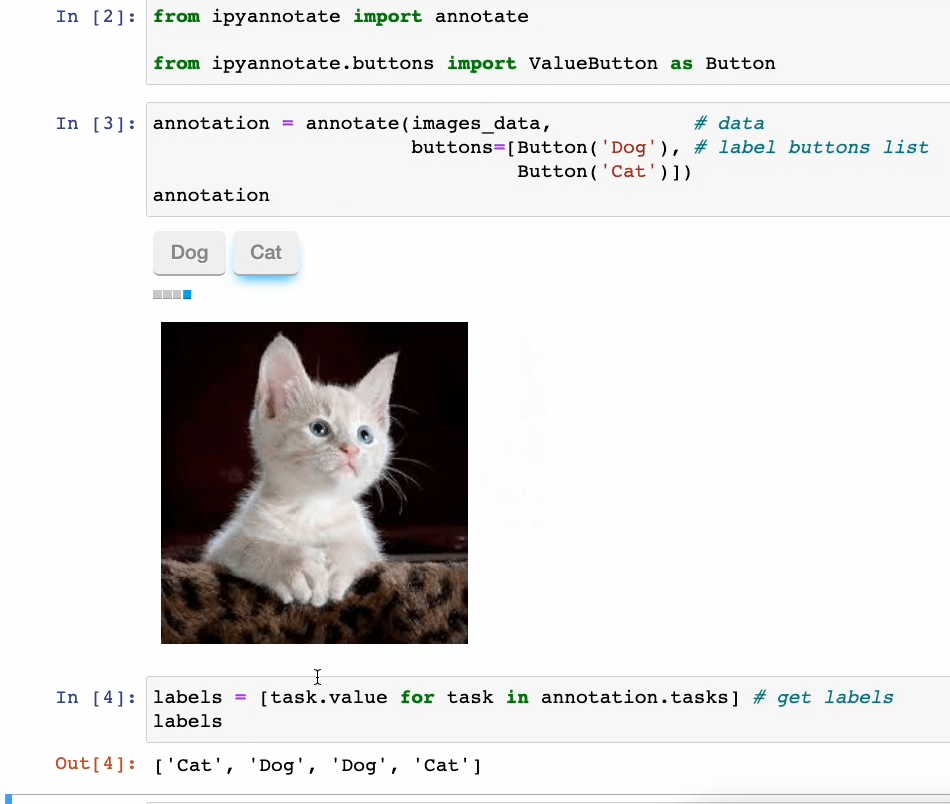
处理未标记的数据是,可以使用ipyannotate,在几行代码中进行注释,然后通过点击按钮进行数据标注。如下所示。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Pointnet++改进系列:全网首发RepVGG结构重参数化 |即插即用,实现有效涨点
- 【JavaEE进阶】实现验证码
- 使用react+vite开发项目时候,部署上线后刷新页面无法访问解决办法
- 十大经典排序算法(个人总结C语言版)
- 二十三、关于vite项目中无法使用minio的解决方案
- 自己动手写数据库系统:解释执行 update 和 delete 对应的 sql 语句
- Thinkphp5.0.23远程命令执行
- BigQuery 分区表简介和使用
- Mybatis 36_使用sql定义可复用的SQL片段 项目0413定义可复用的SQL片段
- Docker compose