爬取A站视频,涉及m3u8格式的处理
发布时间:2024年01月22日
一、抓包分析
1.进入A站进行抓包分析
进入一个页面,右点击鼠标按钮,点击检查

?接着点击network,点击Fetxh/XHR,然后刷新网页,得到下面的页面
?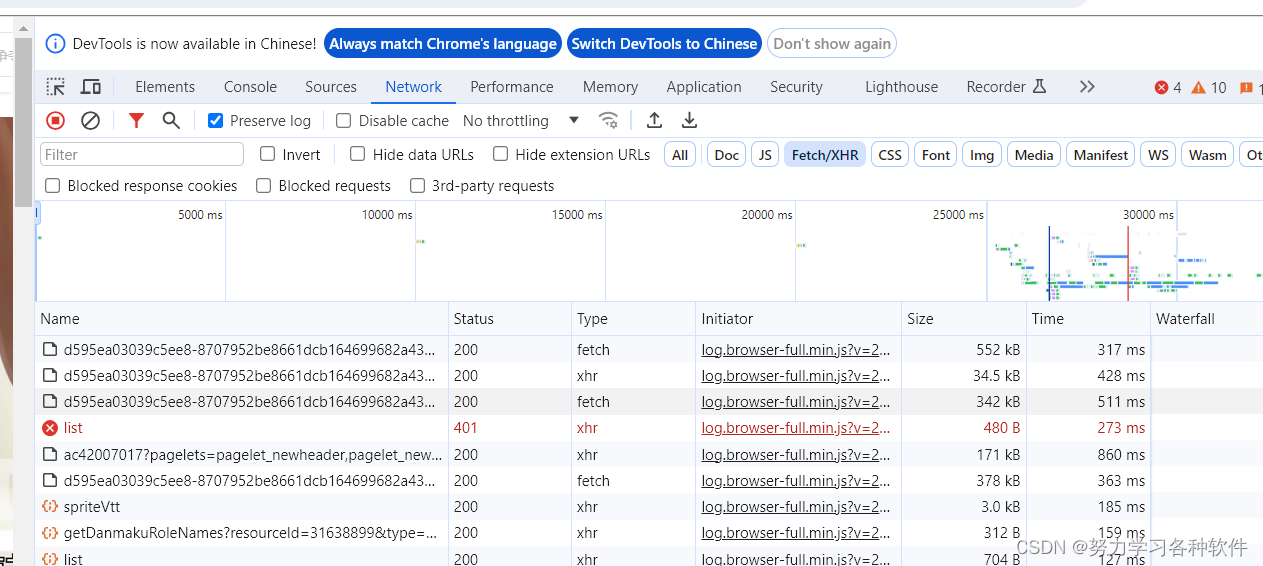 发现其中有许多d595开头的文件,它们是ts文件,点击其中一个。在General中复制其requests URL在浏览器打开,会自动下载一个文件,保存为ts,用视频打开发现是一个三四秒的视频。复制其中的一部分进行搜索。
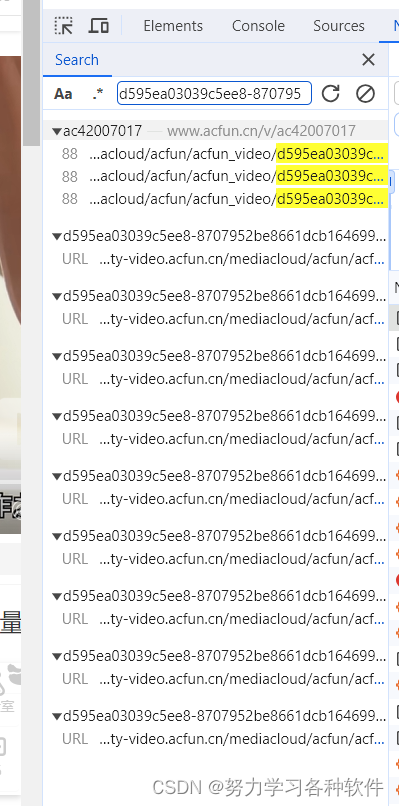
发现其中有许多d595开头的文件,它们是ts文件,点击其中一个。在General中复制其requests URL在浏览器打开,会自动下载一个文件,保存为ts,用视频打开发现是一个三四秒的视频。复制其中的一部分进行搜索。

 ?
?
 ?
?
点击搜索中的最后一个包,查看这?个包,点击preview,可以得到我们想要的下载ts的地址。
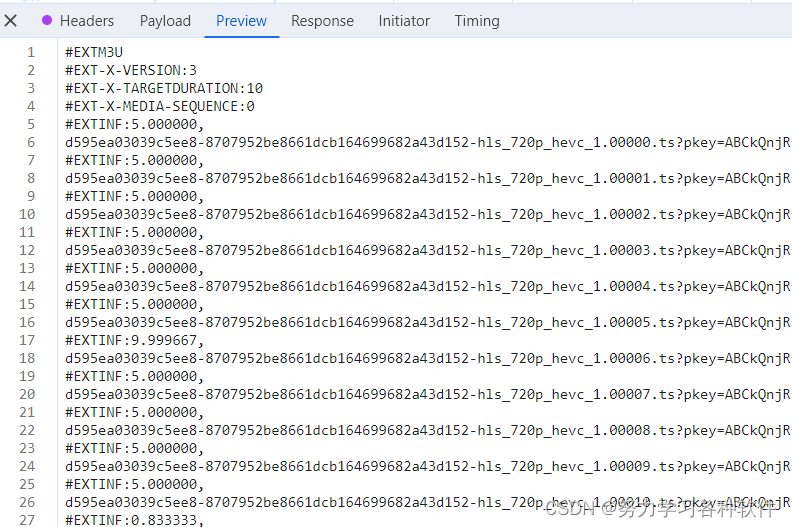
?现在的问题来到,如何找到这个包的url,最后可以在源代码中找到这个包的url。
2.爬虫步骤分解
首先访问该页面源代码,提取到含有视频ts格式地址的包的url,然后访问这个url,提取所有的视频ts地址,然后对视频ts地址进行访问保存视频,最后将视频合成一个。
二、代码展现与讲解
import re
import requests
import time
import os
import zipfile
from tqdm import tqdm
ac_id = input('请输入你想要下载的视频ID:')
url = f'https://www.acfun.cn/v/{ac_id}' # 网页源代码的url地址
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers) # 得到网页源代码
m3u8_url = re.findall('backupUrl(.*?)\"]',response.text)[0].replace('"','').split('\\')[2] # 利用正则提取我们想要抓取的包的url
title = re.findall('<title >(.*?) - AcFun弹幕视频网 - 认真你就输啦 \(\?ω\?\)ノ- \( ゜- ゜\)つロ</title>',response.text)[0] # 获取视频的名称
m3u8_data = requests.get(url=m3u8_url,headers=headers).text # 获取报的内容
m3u8_data = re.sub('#EXTM3U','',m3u8_data) # 利用正则剔除无用的内容
m3u8_data = re.sub('#EXT-X-VERSION:\d','',m3u8_data)
m3u8_data = re.sub('#EXT-X-TARGETDURATION:\d','',m3u8_data)
m3u8_data = re.sub('#EXT-X-MEDIA-SEQUENCE:\d','',m3u8_data)
m3u8_data = re.sub('#EXTINF:\d\.\d+,','',m3u8_data)
m3u8_data = re.sub('#EXT-X-ENDLIST','',m3u8_data)
filename = f'{title}\\' # 生成一个文件夹保存视频
if not os.path.exists(filename):
os.mkdir(filename)
m3u8_data = m3u8_data.split()# 以空格分割 # 分割后,将字符串转化为列表
print('正在下载ts文件内容,请稍后..........')
for link in tqdm(m3u8_data):
link_url = 'https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/'+link # 观察ts的下载地址,对url进行补全
link_name = link.split('.')[1] # 获取每一个ts的名称
link_content = requests.get(url=link_url,headers=headers).content #以二进制保存视频
with open(filename+link_name+'.ts',mode='wb') as f:
f.write(link_content)
print('ts视频片段下载完成.........')
三、总结
1.学到一个库tqdm的使用
2.m3u8视频是分成许多部分的,要找到那个含有所有部分url的包,然后就是找这个包的url
3.合成视频使用zipfile库
files = os.listdir(filename) # 获取文件夹下所有的小视频
with zipfile.ZipFile(filename+title+'.mp4',mode='w') as z:
? ? ? ? z.write(content)
文章来源:https://blog.csdn.net/m0_57265868/article/details/135758428
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- iter() 函数和 next() 函数的理解
- 基于萤火虫算法优化BP神经网络回归分析,基于GSO-BP的回归预测
- K8Spod组件
- JDK17:Java ArrayList源码解读
- Improve PDF Management with XMP Extraction
- 多维时序 | Matlab实现GRO-CNN-BiLSTM-Attention淘金算法优化卷积神经网络-双向长短期记忆网络结合注意力机制多变量时间序列预测
- harmony开发之状态state修饰器的使用
- RTTI结构详细分析(VC++)
- 使用MySQL建立外键约束时,报错3780的问题分析,和解决办法
- 【RT-DETR有效改进】 主干篇 | SwinTransformer替换Backbone(附代码 + 详细修改步骤 +原理介绍)