self-attention(上)李宏毅
发布时间:2024年01月07日
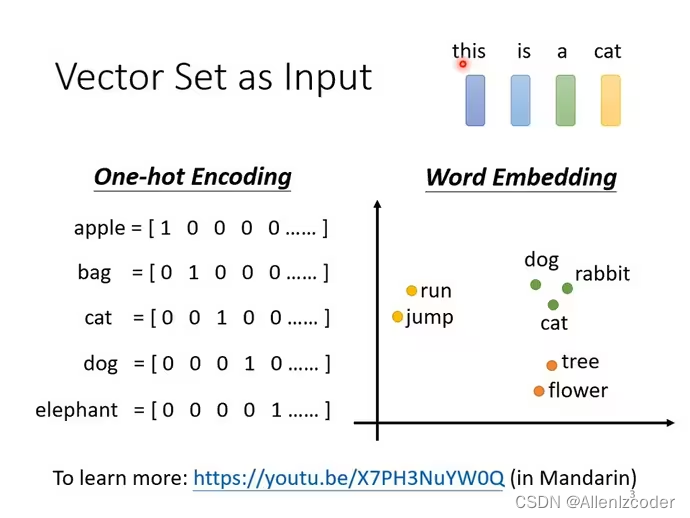
word embedding
https//www.youtube.com/watch?v=X7PH3NuYW0Q
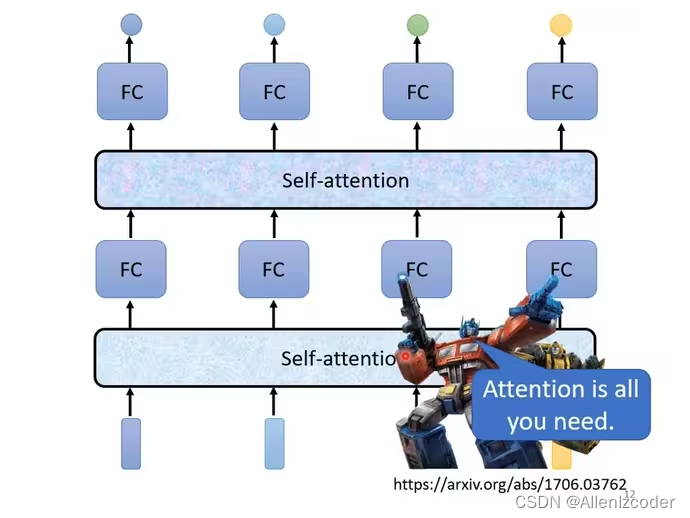
self-attention处理整个sequence,FC专注处理某一个位置的资讯,self-attention和FC可以交替使用。
transformer架构
self-attention的简单理解
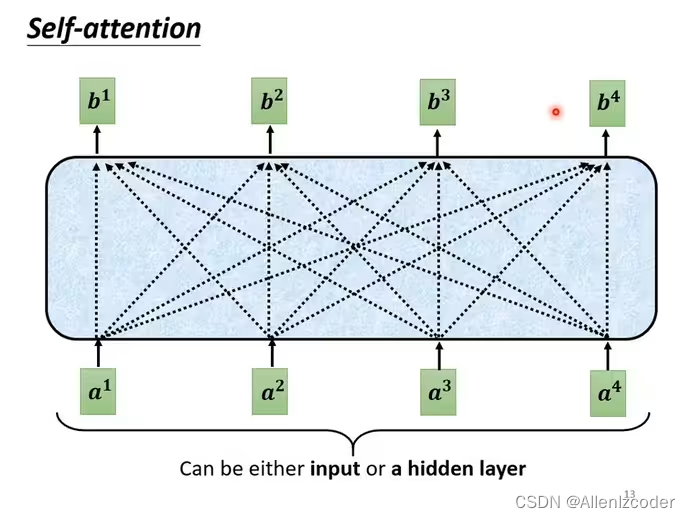
a1-a4可能是input也可以作为中间层的输入,b1~b4每个向量都会考虑整个input sequence
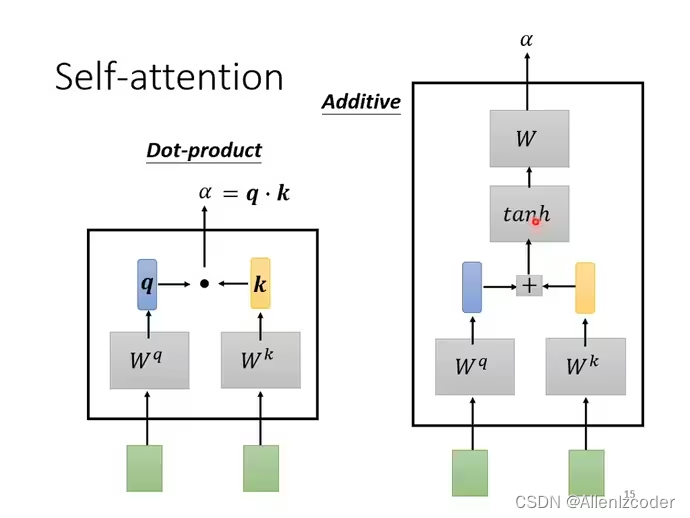
计算关联性(例如向量a1和a2的关联性,一般都是使用下图左边的方法Dot-product)
计算a1和a1自身以及a2,a3,a4的关联性,得到a11,a12,a13,a14
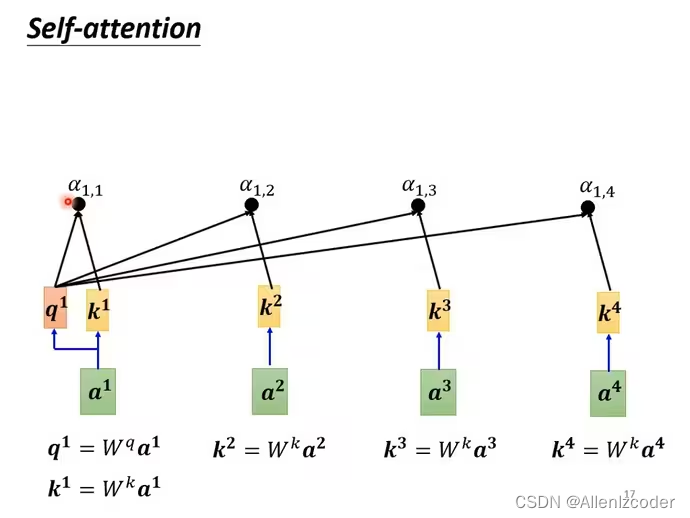
得到关联性向量之后,再经过softmax处理(和分类是一个softmax)
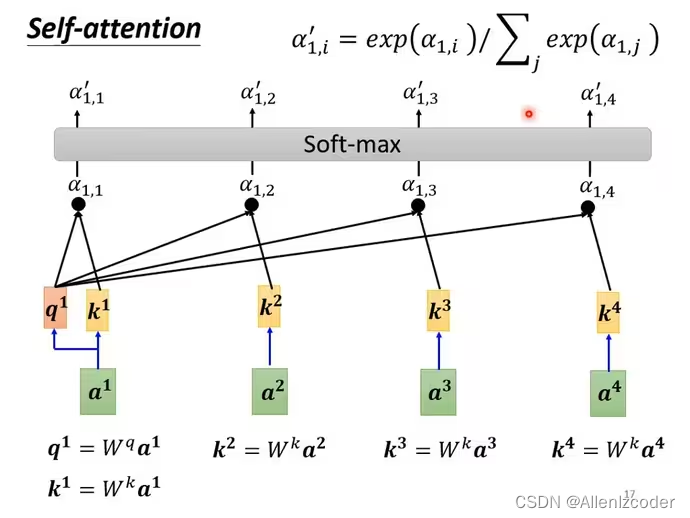
基于attention scores抽取信息
a1-a4每个向量都可以×Wv得到对应的value: v1-v4。然后将关联性向量a11‘-a14’乘上对应的value,然后结果相加得到b1
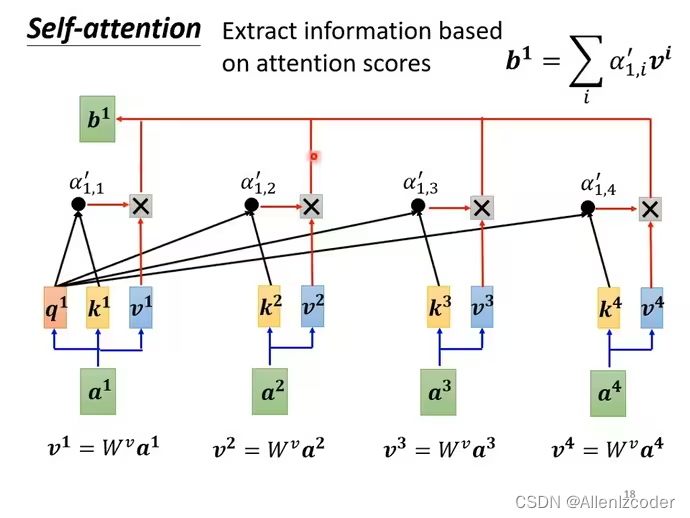
然后依次计算b2,b3,b4,所以哪个关联性更大,得到的结果也就越接近那个关联性数据(比如a11’最大,得到的b1也就最接近a11‘,或者说b1的主要构成是由a11’构成)
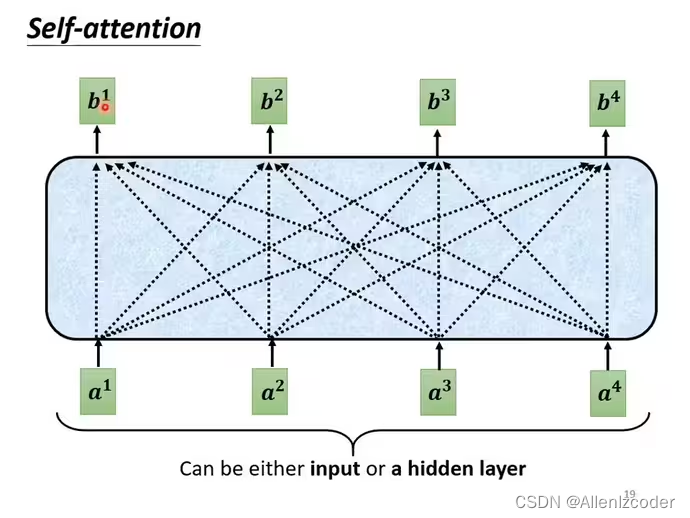
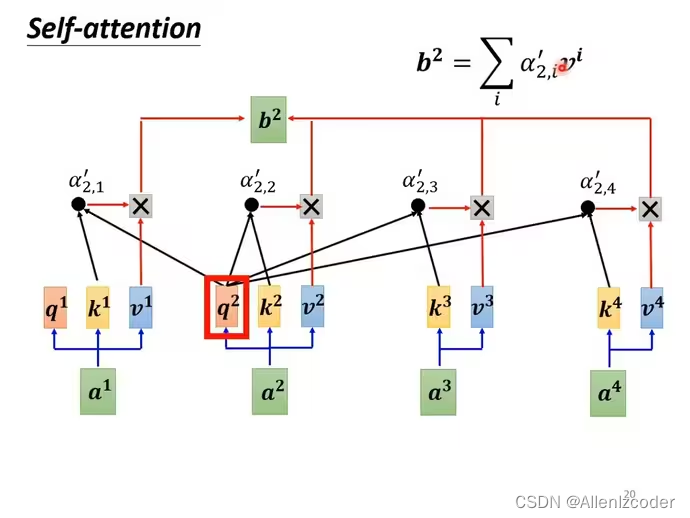
概括计算b2流程
a1-a4乘上martix Wq,得到q1-q4,a1-a4乘上martix Wk,得到k1-k4,q2和k1-k4做dot-product操作,得到self-attention score(可能还会经过softmax处理): a21‘,a22‘,a23‘,a24‘,然后各自与v1~v4相乘,然后相加得到b2。
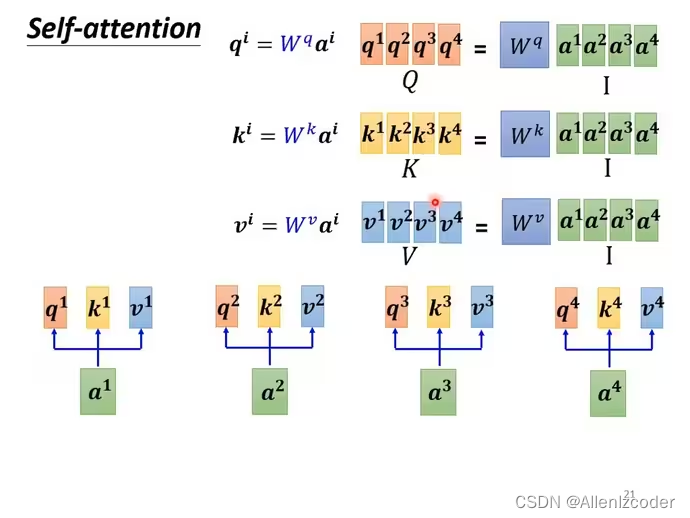
从矩阵角度理解计算过程
我的理解:这样就很容易提高运算速度,因为并行度高
文章来源:https://blog.csdn.net/Allenlzcoder/article/details/135437865
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JVM实战(26)——SystemGC
- 【Python常用函数】一文让你彻底掌握Python中的numpy.append函数
- mysql进阶 - 存储过程
- 中通快递批量查询方法
- openGauss学习笔记-170 openGauss 数据库运维-备份与恢复-导入数据-更新表中数据-使用合并方式更新和插入数据
- 我的创作纪念日——redis的历史纪录
- 【算法基础 & 数学】快速幂求逆元(逆元、扩展欧几里得定理、小费马定理)
- 【Docker】Docker基础
- 代码随想录刷题题Day17
- ES6的默认参数和rest参数