爬虫之牛刀小试(二):爬古诗文网的数据
发布时间:2024年01月11日
古诗文网
import requests
import re
import time
HEADERS = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
def spider_page(url):
response = requests.get(url,headers=HEADERS)
text_raw = response.text
titles=re.findall(r'<div\sclass="cont">.*?<b>(.*?)</b>',text_raw,re.DOTALL)
dynasties=re.findall(r'<p\sclass="source">.*?<a.*?>.*?<a.*?>(.*?)</a>',text_raw,re.DOTALL)
names=[]
img_urls=[]
text=re.findall(r'<p\sclass="source">.*?<a.*?>(.*?)</a>',text_raw,re.DOTALL)
for text_item in text:
img_url = re.search(r'<img src="(.*?)"', text_item)
name = re.search(r'alt="(.*?)"', text_item)
if img_url and name:
names.append(name.group(1))
img_urls.append(img_url.group(1))
contents_pre=re.findall(r'<div\sclass="contson".*?>(.*?)</div>',text_raw,re.DOTALL)
contents=[]
for content_pre in contents_pre:
content=re.sub(r'<.*?>|\n',"",content_pre)
contents.append(content.strip())
poems=[]
for value in zip(titles,dynasties,names,contents,img_urls):
title,dynastie,name,content,img_url=value
poem={
'title':title,
'dynastie':dynastie,
'author':name,
'img_url':img_url,
'content':content
}
poems.append(poem)
return poems
def spider():
poems=[]
for x in range(1,11):
print('第{}页正在爬取'.format(x))
url='https://www.gushiwen.org/default_{}.aspx'.format(x)
print(url)
poems+=spider_page(url)
time.sleep(1)
for poem in poems:
print(poem)
print('='*40)
if __name__=='__main__':
spider()
spider_page(url): 这个函数从给定的 URL 获取古诗。它首先发送一个 GET 请求到 URL,然后解析返回的 HTML 文档,提取出诗词的标题、朝代、作者、内容和图片 URL。
spider(): 这是主函数,它遍历诗词列表页的 URL,对每个诗词列表页调用 spider_page(url) 函数获取诗词信息,然后将所有诗词的信息打印出来。
这次利用的是re,上一篇用的是xpath和bs4。
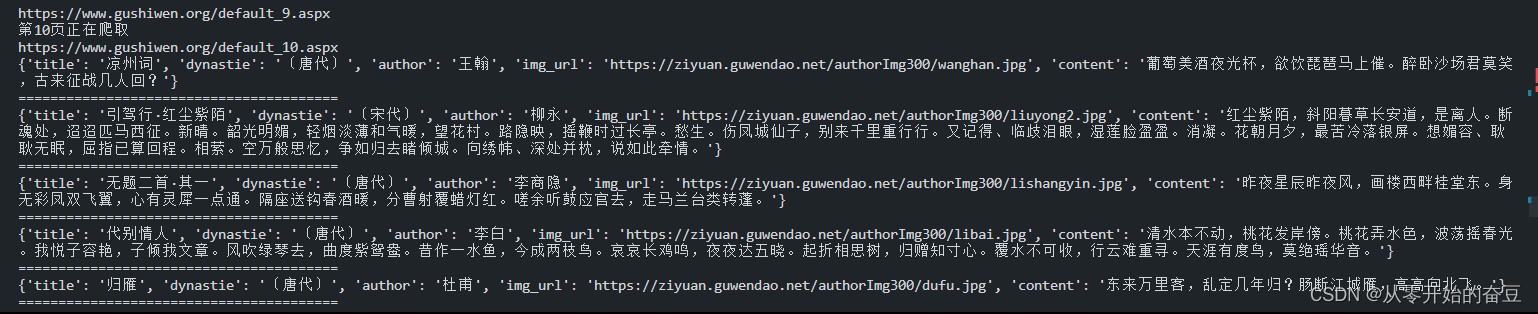
结果:
注意不要爬太多。
最近新开了公众号,请大家关注一下。

文章来源:https://blog.csdn.net/m0_68926749/article/details/135531420
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue3 状态管理 Vuex
- 华为云磁盘性能指标(参考)
- 天锐绿盾 | 自动智能透明加密保护数据 \ 防泄密系统
- Android 横竖屏切换之窗体泄露leaked window DecorView XXXActivity
- Pytorch如何使用RNN而不是RNNCell进行单步(迭代,递归)更新
- 338. 计数问题
- C语言系统化精讲(五):C语言格式化输入和运算符与表达式
- 【java】设计模式
- Wilcoxon秩和检验-校正P值(自备)
- 分享一些网站关键词优化的技巧和工具