Faster R-CNN
1?Faster R-CNN的改进


2 RPN理解
1 对比Fast R-CNN
2 PRN的详细步骤
1 特征图提取:
- 输入图像首先通过基础卷积网络(例如VGG16, ResNet等),这个网络不负责做最终的对象检测,而是用来提取图像的特征。
- 输出是一个特征图(feature map),这个特征图包含了输入图像的抽象特征表示。
2 3x3卷积层:
- 在特征图上应用3x3卷积。这步操作不会改变特征图的尺寸,但会增加每个像素点的感受野(即该点能“看到”的周围区域)。把感受区域增大。
- 这意味着,经过这步操作后,特征图上每个点的特征都是由其周围区域共同决定的。
- 就如下图所示,经过3x3卷积之后,变成一个点,而特征图尺寸不变,增大了感受区域

3 定义Anchor Boxes:
- 在特征图的每个位置定义预先设定的多个Anchor Boxes。这些Anchor Boxes有不同的尺寸和长宽比,用来适应不同大小和形状的目标对象。
- 例如,在每个位置,你可能会定义9个Anchor Boxes:3种不同尺寸 × 3种不同长宽比。
- 如下例子

4 边界框回归和分类分支:
在介绍边界框回归和分类分支之前,首先要理解一件事情:
在Faster R-CNN的RPN过程中,特征图上的每个点对应多个Anchor Boxes,这些Anchor Boxes的顺序通常是预先定义好的,并在整个训练和推理过程中保持一致。
举个例子来说:假设你有 S 个不同的尺寸和 R 个不同的比例,那么总共会有 S×R 个Anchor Boxes。进行排序,可以首先按尺寸排序,对于每个尺寸,再按比例排序。如果有3个尺寸(128x128, 256x256, 512x512)和3个比例(1:1, 1:2, 2:1),那么首先排列尺寸为128x128的所有比例的Anchor Boxes,然后是256x256的,最后是512x512的。对于每个尺寸,先排列比例为1:1的Anchor Box,然后是1:2的,最后是2:1的。
在训练和预测阶段,模型会按照这个顺序对每个位置的Anchor Boxes生成预测结果。
对于边界框回归,模型会按照顺序为每个Anchor Box输出四个参数(偏移量和尺寸调整,也就是四个通道数)。
对于分类,模型会按照顺序为每个Anchor Box输出分类概率(在二分类问题中通常是对象和背景的概率,也就是两个通道数)。
其实对于模型来说,在一开始并不“知道”每个Anchor Box的具体意义,但它通过训练学习到如何为每个按顺序排列的Anchor Box生成准确的预测结果。其实就是说,对于一开始对一个点进行划分Anchor Boxes,放进模型里训练,其实我觉得对于模型来说是不是尺寸的划分并没有什么用,有用的是通过模型的预测与实际划分的尺寸的区域的损失来训练模型,
上面的内容的话,可以先看下面具体步骤,再来看这些
- 边界框回归(Bounding Box Regression):
- 在经过3x3卷积的特征图上,对每个Anchor Box应用一个小的网络(1x1卷积),输出每个Anchor Box的4个调整参数。这4个参数是相对于Anchor Box位置和尺寸的调整值,分别代表边界框中心的x、y坐标的偏移量以及宽度和高度的缩放因子。
- 如果特征图尺寸为WxH(宽x高),共有A个Anchor Boxes,那么边界框回归层将有WxHxAx4个输出。
就是说,假设你有 A 个Anchor Boxes,每个Anchor Box需要预测4个回归值(通常是中心点的x、y坐标的偏移量,以及宽度和高度的缩放因子)。因此,对于特征图上的每个位置(每个点),1x1卷积后你会得到 4A 个通道的输出。
这 4A 个通道的值按顺序对应于这个位置的 A 个Anchor Boxes的4个回归值。比如说,第1到第4个通道对应于第一个Anchor Box的4个回归值,第5到第8个通道对应于第二个Anchor Box的4个回归值,以此类推。
- 分类(Classification):
- 同样在经过3x3卷积的特征图上,对每个Anchor Box应用另一个小网络(1x1卷积),输出每个Anchor Box包含对象的概率。
- 分类层输出2A个值(对于二分类问题:对象vs背景),所以如果特征图尺寸为WxH,共有A个Anchor Boxes,那么分类层将有WxHxAx2个输出。
对于分类,假设你有 A 个Anchor Boxes,每个Anchor Box需要预测2个值(在二分类问题中,通常是对象和背景的概率)。因此,对于特征图上的每个位置,1x1卷积后你会得到 2A 个通道的输出。
这 2A 个通道的值按顺序对应于这个位置的 A 个Anchor Boxes的2个分类值。比如说,第1和第2个通道对应于第一个Anchor Box的对象和背景的概率,第3和第4个通道对应于第二个Anchor Box的对象和背景的概率,以此类推。
5 生成提议(Region Proposals):
- 使用边界框回归层的输出调整每个Anchor Box的位置和尺寸,得到调整后的提议。
- 使用分类层的输出评估每个提议是对象的概率。
6 应用非极大值抑制(NMS):
????????这一步可以在这里做,也可以在后面使用RPN提议进行后续处理来做
- 对生成的提议应用NMS。NMS通过去除那些与高分提议高度重叠的低分提议,保证最终的提议之间有较少的重叠。
- 选择NMS阈值是一个实验性的过程,需要根据具体任务和数据集调整。
7 训练RPN:
- 使用真实标注数据(ground truth data)定义正样本和负样本Anchor Boxes。
- 对于每个Anchor Box,使用多任务损失函数来同时优化边界框的位置(通过回归损失)和分类准确性(通过分类损失)? ? ? ? ??
8 使用RPN提议进行后续处理:
具体来说,Proposal Layer执行以下操作:
-
得分排序:
- 对于每个锚框,RPN会输出一个对象得分,即该锚框包含对象的概率。Proposal Layer会根据这个得分对所有锚框进行排序。
-
应用NMS:
- 在排序后的锚框中,很多高得分的锚框可能会有重叠。为了减少重复检测,非极大值抑制(NMS)被用来去除那些与得分最高的锚框重叠度较高的其他锚框。
-
选择Top-N提议:
- 在应用NMS之后,Proposal Layer会选择得分最高的N个提议。这个数字N可以根据需要设置,常见的值比如2000个提议用于训练,300个用于测试。
-
RoI Pooling:
- 选出的这些提议随后会被送到后续的网络结构中进行更详细的分类和边界框回归。这通常涉及到一个RoI Pooling层,它会将不同大小的提议区域转换成固定大小的特征图,以便进行后续的处理。
Proposal Layer是连接RPN和后续对象检测网络的重要组件,它确保了网络能够专注于那些最有可能包含对象的区域,从而提高了检测的效率和准确性。

第五步提到的IoU匹配与样本选择是为了训练第二次边界框回归。在Faster R-CNN中,这个步骤的确切目的是确定每个提议(由RPN生成并经过NMS处理的)是否作为正样本用于训练,这是通过计算每个提议与真实边界框(Ground Truth)之间的IoU来完成的。因为第一次是生成提议,生成的所有的anchor boxs都要进行边框回归,Proposal Layer之后的提议与真实边框可能iou比较小,所以进行分类正负样本。
上述有一个问题,在Faster R-CNN的不同实现和描述中,术语的使用可能会有所变化。有时,“Proposal Layer”可能被泛指为处理RPN提议的整个后续流程,即便这部分实际上是属于Fast R-CNN的组成。这可能包括提议的进一步筛选、训练样本的选择以及最终的RoI Pooling操作。上述图片中的“Proposal Layer”就是泛指为处理RPN提议的整个后续流程
3?Faster R-CNN的训练方式和多尺度问题
3.1 三种训练方式
3.2 多尺度问题

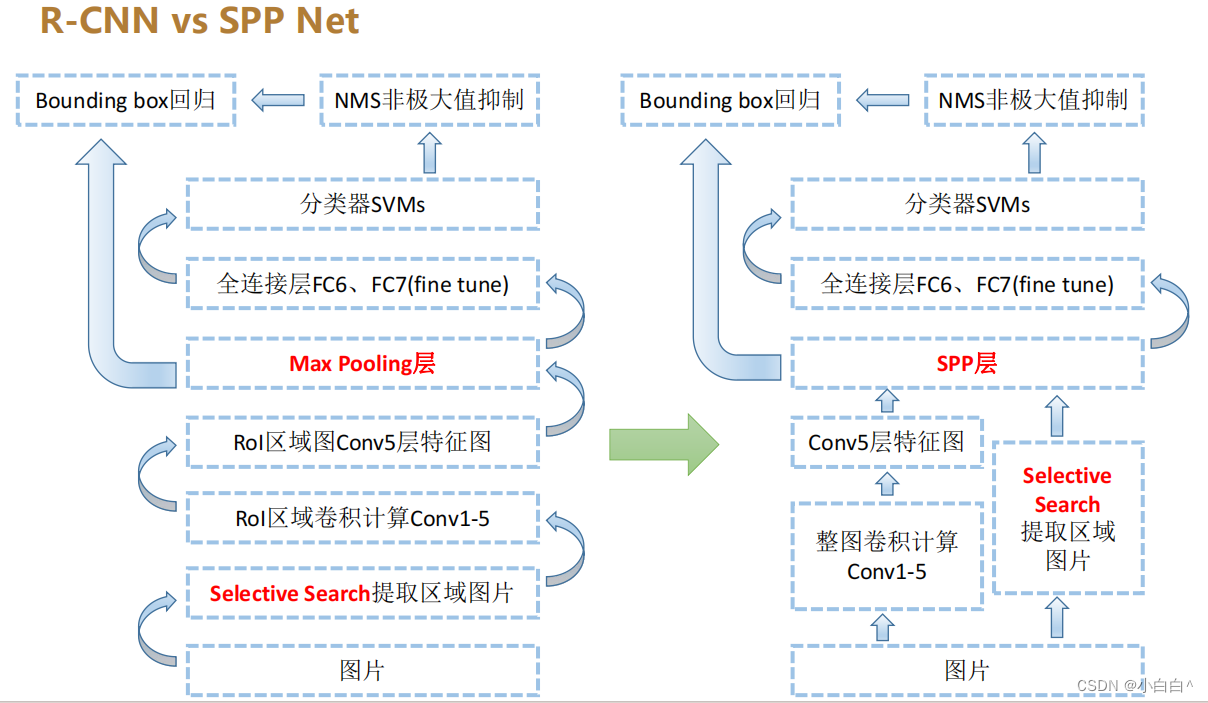
4 R-CNN、SPP Net、Fast R-CNN、Faster R-CNN的区别



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!