TDengine Connector实战使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
本文主要介绍
`提示:本文只展示了Kafka直接接入TDengine方式。
一、TDengine是什么?
TDengine 是一款专为物联网、工业互联网等场景设计并优化的大数据平台,它能安全高效地将大量设备、数据采集器每天产生的高达 TB 甚至 PB 级的数据进行汇聚、存储、分析和分发,对业务运行状态进行实时监测、预警,提供实时的商业洞察。其核心模块是高性能、集群开源、云原生、极简的时序数据库 TDengine OSS。
二、使用步骤
TDengine3.0相比起之前的版本,简化了接入kafka流程步骤,省略了Confluent的安装。具体流程如下:
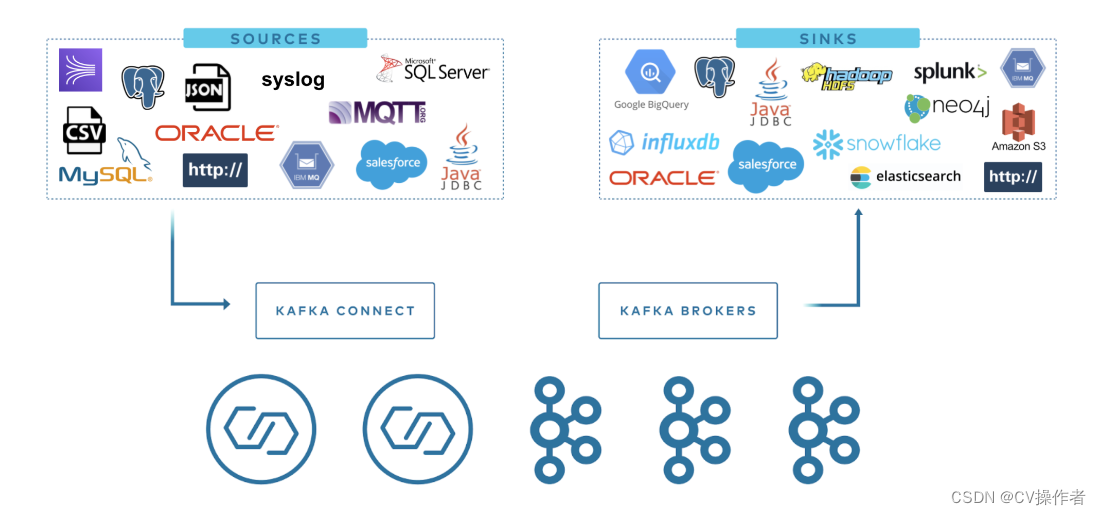
TDengine Kafka Connector 包含两个插件: TDengine Source Connector 和 TDengine Sink Connector。用户只需提供简单的配置文件,就可以将 Kafka 中指定 topic 的数据(批量或实时)同步到 TDengine, 或将 TDengine 中指定数据库的数据(批量或实时)同步到 Kafka。
参考https://docs.taosdata.com/third-party/kafka/
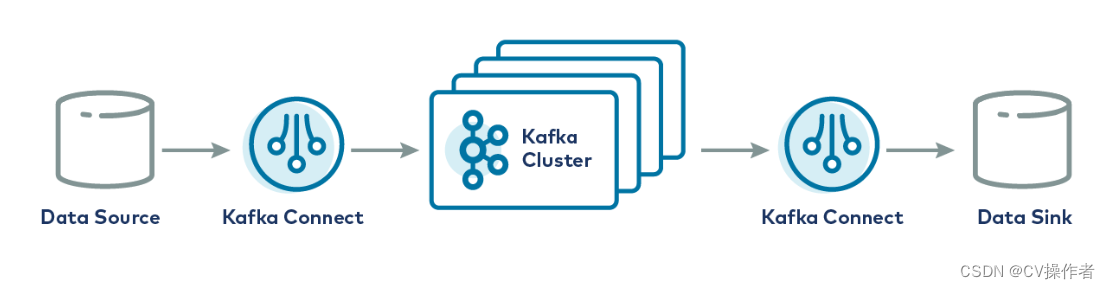 TDengine Source Connector 用于把数据实时地从 TDengine 读出来发送给 Kafka Connect。TDengine Sink Connector 用于 从 Kafka Connect 接收数据并写入 TDengine。
TDengine Source Connector 用于把数据实时地从 TDengine 读出来发送给 Kafka Connect。TDengine Sink Connector 用于 从 Kafka Connect 接收数据并写入 TDengine。
1.前置条件
前提条件:
Linux 操作系统
KAFKA
已安装 Java 8 和 Maven
已安装 Git、curl、vi
已安装并启动 TDengine。如果还没有可参考安装和卸载
2.安装 TDengine Connector 插件
代码如下(示例):
git clone --branch 3.0 https://github.com/taosdata/kafka-connect-tdengine.git
cd kafka-connect-tdengine
mvn clean package -Dmaven.test.skip=true
unzip -d $KAFKA_HOME/components/ target/components/packages/taosdata-kafka-connect-tdengine-*.zip
以上脚本先 clone 项目源码,然后用 Maven 编译打包。打包完成后在 target/components/packages/ 目录生成了插件的 zip 包。把这个 zip 包解压到安装插件的路径即可。上面的示例中使用了内置的插件安装路径: $KAFKA_HOME/components/。
3.配置插件
将 kafka-connect-tdengine 插件加入 $KAFKA_HOME/config/connect-distributed.properties 配置文件 plugin.path 中
plugin.path=/usr/share/java,/opt/kafka/components
4.启动kafka
zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
connect-distributed.sh -daemon $KAFKA_HOME/config/connect-distributed.properties
5.验证是否成功
输入命令
curl http://localhost:8083/connectors
如果启动成功,会得到如下输出
[]
6.TDengine Sink Connector 的使用
采用的接收协议分为三种:
InfluxDB 行协议、OpenTSDB 行协议、OpenTSDB JSON 格式协议
主要介绍OpenTSDB JSON 格式协议
使用OpenTSDB JSON 格式协议的请求参数如下:
{
"name": "TDengineSinkConnector20",
"config": {
"connector.class":"com.taosdata.kafka.connect.sink.TDengineSinkConnector",
"tasks.max": "4",
"topics": "iiot.data.center",
"connection.url": "jdbc:TAOS-RS://IP:端口?user=XXX&password=XXXX",
"connection.user": "XXX",
"connection.password": "XXXX",
"connection.database": "test",
"db.schemaless": "json",
"data.precision": "ns",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name" : "dead_letter_topic",
"errors.deadletterqueue.topic.replication.factor" :1
}
}
需要注意的是最开始使用jdbc:TAOS:配置没有起效对与指定子表名,所以这里换成了jdbc:TAOS-RS,
各协议的配置基本相同,上面配信息的db.schemaless决定采用的是什么协议。
json是OpenTSDB JSON 格式协议,OpenTSDB 行协议是telent,InfluxDB 行协议是line
另外需要注意的是因为TDengine是时序数据库,时间戳是主键,所以数据的时间戳的格式要按照
"data.precision": "ns"
定义的不然会导致数据存储不进去的问题
总结
以上就是TDengine3.0直接接入kafka的使用,有问题随时留言
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- day6:进程间的通信
- Jmeter 命令行压测 & 生成 HTML 测试报告,你真的会?
- “React学习之旅:从入门到精通的点滴感悟“
- R语言实现文献计量分析(1)——bibliometrix
- 利用格式工厂,做视频的剪辑
- 30天精通Nodejs--第二十一天:express-依赖注入
- RViz成功显示多个机器人模型以及解决显示的模型没有左右轮
- groovy XmlParser 递归遍历 xml 文件,修改并保存
- Linux rpm命令教程:如何使用rpm命令进行软件包管理(附实例详解和注意事项)
- 力扣92. 反转链表 II