爬虫是什么 怎么预防
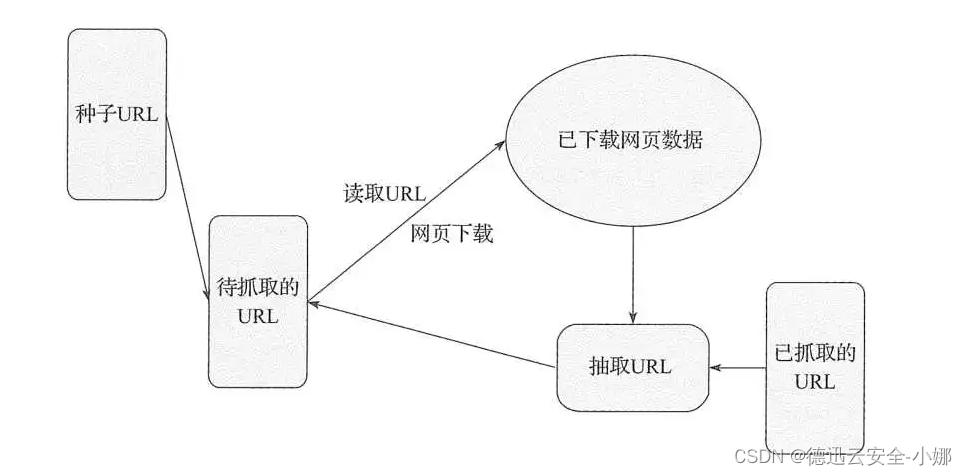 ? ?
? ?
爬虫是一种自动化程序,用于从网页或网站中提取数据。它们通过模拟人类用户的行为,发送HTTP请求并解析响应,以获取所需的信息。
爬虫可以用于各种合法用途,如搜索引擎索引、数据采集和监测等。然而,有些爬虫可能是恶意的,用于非法目的,如数据盗取、内容抄袭、信息泄露等。
爬虫的分类
1.robots协议
? ? robots协议实际上是一个robots.txt文件,是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎也就是通用网络爬虫,此网站中的哪些内容是不应被获取。但遗憾的是robots协议并不是一个规范,而只是约定俗成的,所以并不能阻止一些别有用心的恶意爬信息收集或爬取。
2.爬虫的危害 ?
? ? ? ? 第一种情况是爬虫超范围收集数据,搜集一些非必要的、无关的数据,还有就是涉密的用户隐私数据。
? ? ? ?第二种情况是多线程的爬虫大量爬取某一特定网站会实质性的占用网站的大量带宽资源,造成正常用户无法使用,这在实际效果上和DOS(拒绝服务)攻击没什么区别。
3.恶意爬虫的防御
? ? ? ?1、 服务端可以利用浏览器http头指纹,根据你声明的自己的浏览器厂商和版本(来自 User-Agent ),来鉴别你的http header中的各个字段是否符合该浏览器的特征,如不符合则作为爬虫程序对待。这个技术有一个典型的应用,就是 PhantomJS 1.x版本中,由于其底层调用了Qt框架的网络库,因此http头里有明显的Qt框架网络请求的特征,可以被服务端直接识别并拦截。
? ? ? ? 2、 对所有访问页面的http请求,在 http response 响应中种下一个 cookie token ,然后在这个页面内异步执行的一些ajax接口里去校验来访请求是否含有cookie token,将token回传回来则表明这是一个合法的浏览器来访,否则说明刚刚被下发了那个token的用户访问了页面html却没有访问html内执行js后调用的ajax请求,很有可能是一个爬虫程序。如果你不携带token直接访问一个接口,这也就意味着你没请求过html页面直接向本应由页面内ajax访问的接口发起了网络请求,这也显然证明了你是一个可疑的爬虫
? ? ? ? 3、 使用headless browser,让程序可以操作浏览器去访问网页,这样编写爬虫的人可以通过调用浏览器暴露出来给程序调用的api去实现复杂的抓取业务逻辑。
? ? ? ? 4、 目前的反抓取、机器人检查手段,最可靠的还是验证码技术。但验证码并不意味着一定要强迫用户输入一连串字母数字,也有很多基于用户鼠标、触屏(移动端)等行为的行为验证技术,这其中最为成熟的当属Google reCAPTCHA。
以下是一些常见的预防爬虫的措施:
? robots.txt文件:使用robots.txt文件来定义哪些页面可以被搜索引擎爬取,哪些页面不应被爬取。爬虫通常会遵守robots.txt规则,因此可以通过适当配置该文件来限制爬虫的访问。
? IP封禁和访问频率限制:监控网站的访问日志,识别异常的访问模式和高频率的请求,并使用IP封禁、访问频率限制等措施来阻止恶意爬虫的访问。
? 验证码和人机验证:在敏感操作或访问权限受限的页面上,使用验证码或其他人机验证机制,以区分人类用户和自动化爬虫。
? 反爬虫技术:使用反爬虫技术,如动态生成内容、请求限制、隐藏关键信息等,来阻止爬虫的抓取行为。
? 会话管理:为爬虫请求和正常用户请求设置不同的会话标识,通过会话管理来区分和限制爬虫的访问。
? User-Agent检测:通过检测User-Agent字段,识别和过滤掉常用的爬虫User-Agent,或者只允许特定的User-Agent访问。_
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux 安装Jupyter notebook 并开启远程访问
- 智能小程序环境配置流程
- springMVC-@RequestMapping
- drools规则引擎介绍
- 【新书推荐】2.2节 进制算术运算
- K8S学习指南(52)-k8s包管理工具Helm
- Docker自建私人云盘系统
- ARCGIS PRO SDK 地图图层单一符号化_____面图层
- 可回收箱控制主板升级助推生活垃圾数据化、资源化
- 图书进销存软件哪个好用?(比较好用的图书进销存软件推荐)