K8s 源码剖析及debug实战之 Kube-Scheduler(六):调度流程总结
0. 引言
欢迎关注本专栏,本专栏主要从 K8s 源码出发,深入理解 K8s 一些组件底层的代码逻辑,同时借助 debug Minikube 来进一步了解 K8s 底层的代码运行逻辑细节,帮助我们更好了解不为人知的运行机制,让自己学会如何调试源码,玩转 K8s。
本专栏适合于运维、开发以及希望精进 K8s 细节的同学。同时本人水平有限,尽量将本人理解的内容最大程度的展现给大家~
前情提要:
《K8s 源码剖析及debug实战(一):Minikube 安装及源码准备》
《K8s 源码剖析及debug实战(二):debug K8s 源码》
《K8s 源码剖析及debug实战之 Kube-Scheduler(一):启动流程详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(二):终于找到了调度算法的代码入口》
《K8s 源码剖析及debug实战之 Kube-Scheduler(三):debug 到预选算法门口了》
《K8s 源码剖析及debug实战之 Kube-Scheduler(四):预选算法详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(五):优选算法详解》
文中采用的 K8s 版本是 v1.16。上篇介绍了优选算法的主要逻辑,本文总结 K8s 的 Kube-Scheduler 调度的主要逻辑。
1. 回顾
回顾下上节的整体流程,我们这里介绍调度计算完成后,pod 绑定节点的流程!
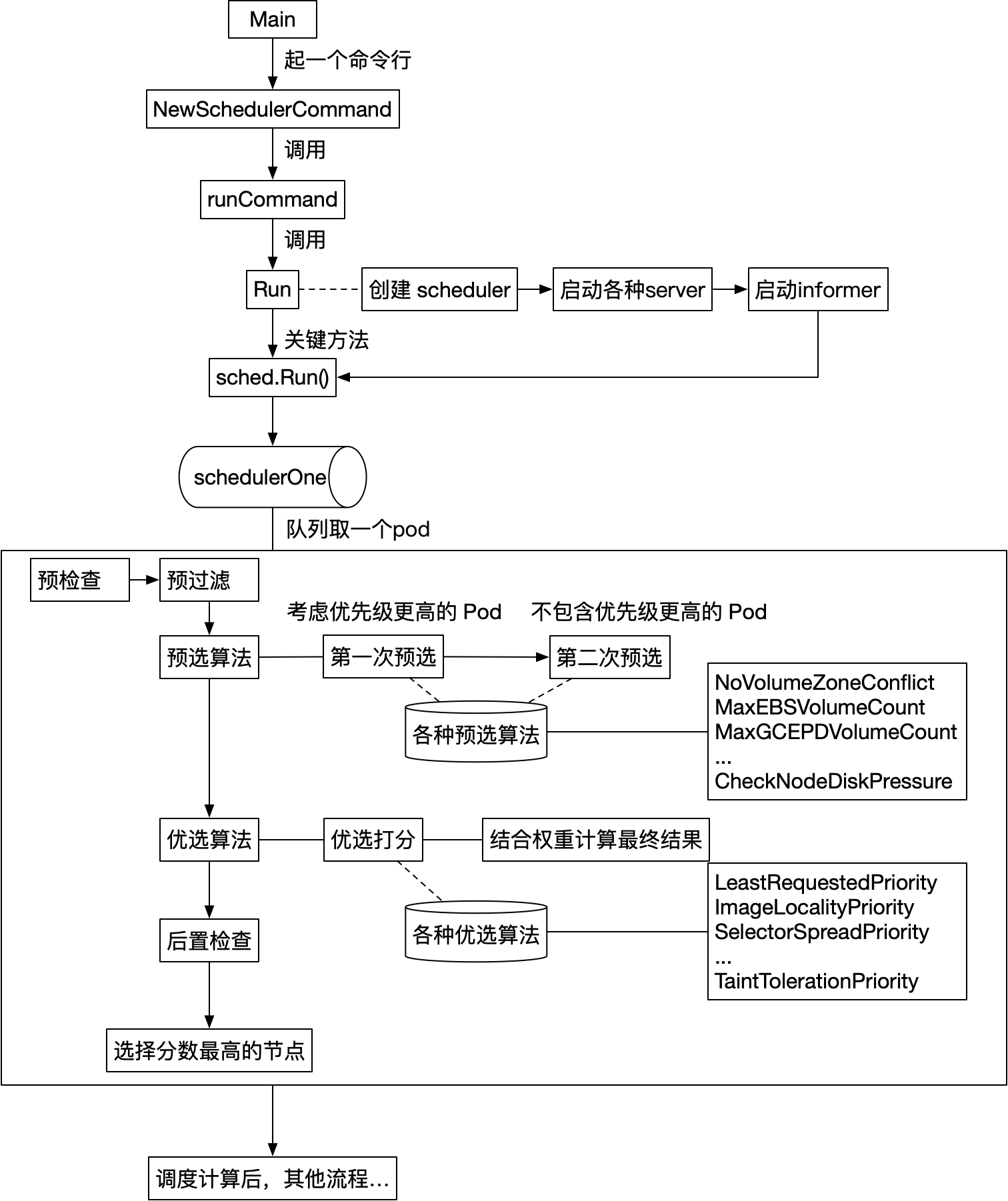
2. pod 绑定节点
我们在 《K8s 源码剖析及debug实战之 Kube-Scheduler(二):终于找到了调度算法的代码入口》 介绍了调度的整体逻辑,如下:
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne() {
...
// 1. 执行调度
pod := sched.NextPod()
scheduleResult, err := sched.schedule(pod, pluginContext)
// 2. 绑定pv,更新缓存
assumedPod := pod.DeepCopy()
allBound, err := sched.assumeVolumes(assumedPod, scheduleResult.SuggestedHost)
// 3. 执行预留的插件
if sts := fwk.RunReservePlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {...}
// 4. 假设pod调度成功,更新缓存
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
// 5. 起一个协程,异步绑定pod到host上
go func() {...}()
}
而后我们主要详细介绍了 sched.schedule 的逻辑,其中第2步到第4步逻辑不是很关键,现在来介绍下第5步,如何绑定 pod 到一个节点。
第5步这个协程的主要内容展开看下:
func (sched *Scheduler) scheduleOne() {
...
// 5. 起一个协程,异步绑定pod到host上
go func() {
// 5.1 一般不用考虑,准入插件
permitStatus := fwk.RunPermitPlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost)
// 5.2 一般不用考虑,bind前的插件
preBindStatus := fwk.RunPreBindPlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost)
// 5.3 执行bind
err := sched.bind(assumedPod, scheduleResult.SuggestedHost, pluginContext)
// 5.4 一般不用考虑,bind后的插件
fwk.RunPostBindPlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost)
}()
}
很显然,主要就是步骤5.3,执行 bind,主要逻辑如下:
func (sched *Scheduler) bind(assumed *v1.Pod, targetNode string, pluginContext *framework.PluginContext) error {
...
// 1. 排除if语句的干扰,实际执行这句来执行bind
err = sched.GetBinder(assumed).Bind(&v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumed.Namespace, Name: assumed.Name, UID: assumed.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: targetNode,
},
})
// 2. 更新缓存
if finErr := sched.SchedulerCache.FinishBinding(assumed); finErr != nil {...}
}
sched.GetBinder(assumed).Bind() 是一个接口,实际调用的是 pods 的实现
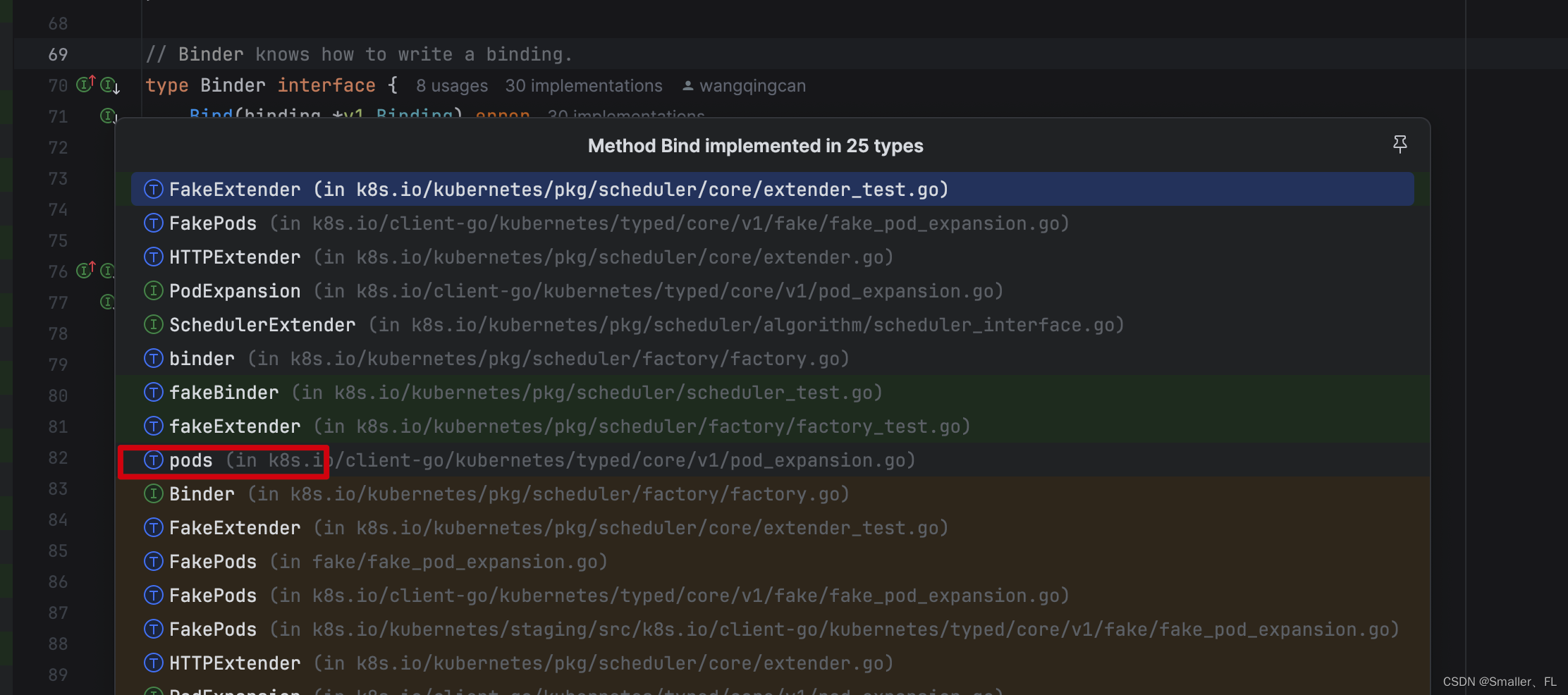
真正调用的是这个:
// Bind applies the provided binding to the named pod in the current namespace (binding.Namespace is ignored).
func (c *pods) Bind(binding *v1.Binding) error {
return c.client.Post().Namespace(c.ns).Resource("pods").Name(binding.Name).SubResource("binding").Body(binding).Do().Error()
}
这样一来就清楚了,这里是访问 K8s apiserver,把 pods 和节点信息更新到 etcd 中,而后就把 pod 和 节点信息绑定了。
3. 总结
基于之前的所有逻辑,我整理一个大致整体的流程,如下:
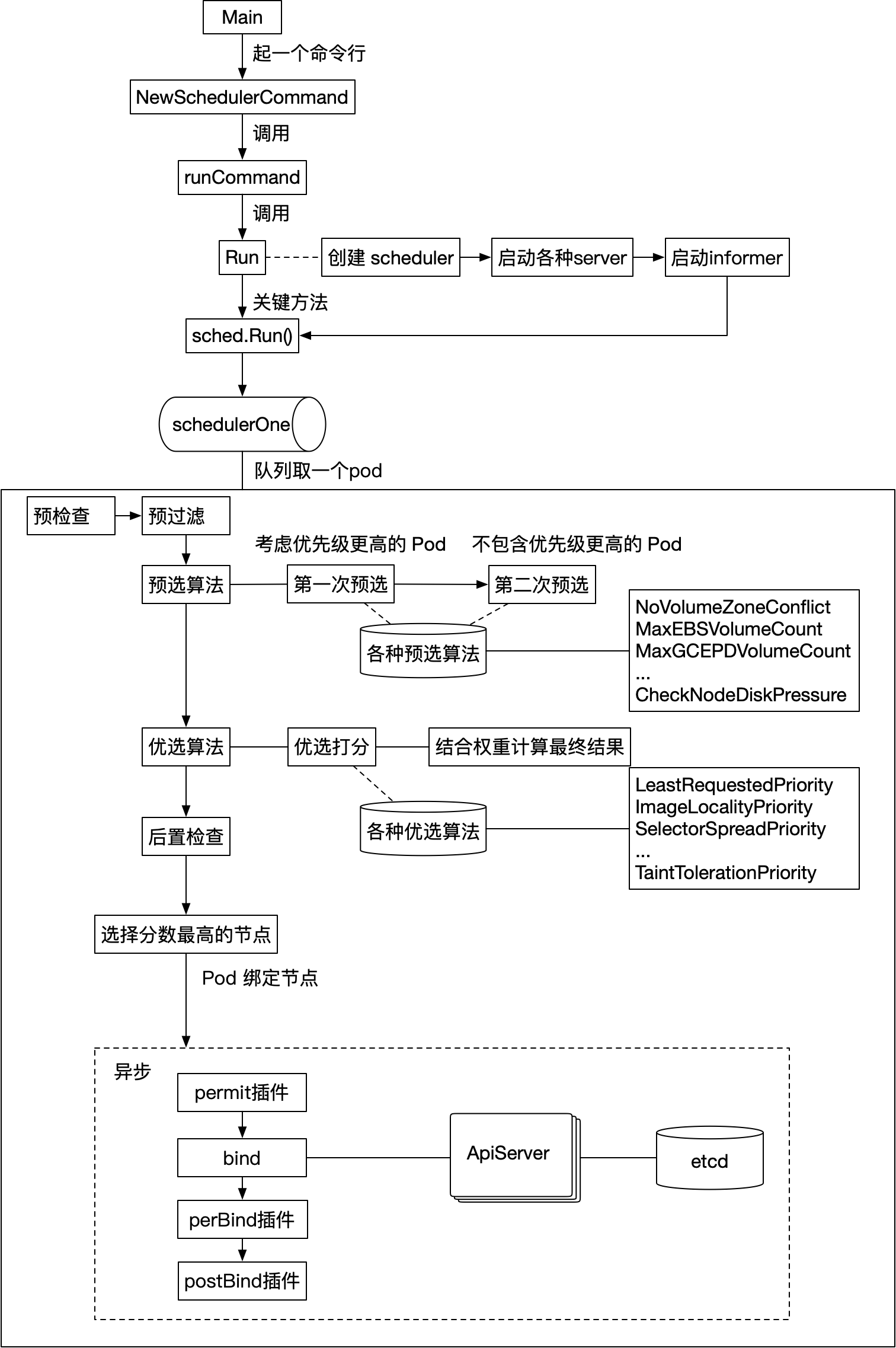
好了,到现在为止,调度的整体流程就讲解完成了。
4. 参考
《K8s 源码剖析及debug实战(一):Minikube 安装及源码准备》
《K8s 源码剖析及debug实战(二):debug K8s 源码》
《K8s 源码剖析及debug实战之 Kube-Scheduler(一):启动流程详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(二):终于找到了调度算法的代码入口》
《K8s 源码剖析及debug实战之 Kube-Scheduler(三):debug 到预选算法门口了》
《K8s 源码剖析及debug实战之 Kube-Scheduler(四):预选算法详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(五):优选算法详解》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
也欢迎关注我的wx公众号:一个比特定乾坤

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《码农的噩梦与修电脑的奇幻之旅》
- 你真的读懂了“in”运算符吗?
- 常用的数据库链接工具都有哪些
- Mysql中insert float类型,结果为int类型
- 「第三章」python-docx 添加标题,word标题从入门到精通
- 苏宁易购商品详情API:电商实时数据
- 数据结构之美:如何优化搜索和排序算法
- ssm基于Java的网络音乐系统的设计与实现论文
- K8S学习指南(30)-k8s网络插件flannel
- yolov8实战第三天——yolov8TensorRT部署(python推理)(保姆教学)