(2024,LadaGAN,Ladaformer,自调制归一化)使用线性加性注意力 Transformer 的高效 GAN
Efficient generative adversarial networks using linear additive-attention Transformers
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
尽管深度生成模型在图像生成方面的能力,如扩散模型(DMs)和生成对抗网络(GANs),在近年来有了显著的提升,但它们的成功很大程度上归因于计算昂贵的架构。这限制它们在研究实验室和资源丰富的公司中的采用和使用,同时显著提高了训练、微调和推理的碳足迹。在这项工作中,我们介绍了 LadaGAN,一种基于名为 Ladaformer 的新型 Transformer 块的高效生成对抗网络。该块的主要组成部分是一个线性的加法注意力机制,它计算每个头部的单个注意力向量,而不是二次的点积注意力。我们在生成器和鉴别器中都使用了 Ladaformer,这降低了计算复杂性并克服了通常与 Transformer GANs 相关的训练不稳定性。在不同分辨率的基准数据集上,LadaGAN 在效率上始终优于现有的卷积和 Transformer GANs。此外,与最先进的多步生成模型(例如 DMs)相比,LadaGAN 在使用计算资源的数量上表现出有竞争力的性能。
源代码:https://github.com/milmor/LadaGAN
2. 相关工作
受到在自然语言处理和图像分类方面取得的成功的启发,基于 Transformer 的架构已经被提出用于GANs,与最先进的卷积模型(如 BigGAN [16] 和 StyleGANs [10],[11])相比,显示出有竞争力的结果。其中一个最早的基于 Transformer 的 GAN 是 TransGAN [17],它采用梯度惩罚 [8],[18] 来稳定 transformer 鉴别器的训练。TransGAN 通过使用网格自注意力来解决二次限制,该注意力机制将全尺寸特征图分割成几个不重叠的网格。TransGAN 的实验表明,网格自注意力比 Nystr¨om [19] 和 Axis attention [20] 取得更好的结果。另一方面,ViTGAN [7] 生成补丁,缩短了transformer 输出序列的长度。为了稳定 transformer 鉴别器,该模型采用了 L2 attention [21] 并对原始的谱归一化 [9] 进行了修改。此外,为了提高性能,生成器使用了隐式神经表示 [22]。然而,训练 TransGAN 和 ViTGAN 都需要多个 GPU;TransGAN 在 16个V100 GPU 上进行训练,而ViTGAN 在一个 TPU 上进行训练。尽管 Swin-Transformer 块已经在 ViTGAN 中得到了探讨以降低计算需求,但它表现不及原始的 Transformer 块。
由于发现 transformer 鉴别器影响对抗训练的稳定性 [7],最近的一些工作依赖于基于卷积的鉴别器,仅在生成器中使用 transformers。例如,HiT [23] 是一种通过使用多轴阻塞自注意力来解决二次复杂性的架构。同样,StyleSwin 生成器的主要块 [14] 由 SwinTransformer 组成。然而,除了不充分利用 transformers 在鉴别器中的作用外,这些架构的设计也没有优先考虑效率,因此它们的训练需要超过一个单独的 GPU;StyleSwin 在 8 个 32GB V100 GPU 上进行训练,而 HiT 在一个TPU 上进行训练。
另一方面,GANsformer [24] 结合了自注意力和卷积的归纳偏差。这个模型由一个二分图组成,导致对 StyleGAN 的一种泛化,因此它只部分利用了 transformers 的能力。结合卷积和 transformers已经提升了图像分类任务中的神经架构 [25],[26],[27];然而,在图像生成任务中它的探索较少。LadaGAN 也结合了卷积和自注意力,但与 GANsformer 不同,它在鉴别器和生成器中都使用了加法注意力,以解决二次复杂性和训练不稳定性。
在过去的几年中,扩散模型 [28],[29] 在几个图像生成任务中胜过了GANs [30],[31]。这类模型学习逆转一个多步噪声过程,其中每一步都需要通过整个网络进行前向传播。最突出的扩散模型包括 DDPM(去噪扩散概率模型) [29] 和 ADM(消融扩散模型) [31]。然而,这些模型在参数和FLOPs 方面都比较复杂,生成需要多次前向传播,导致训练和推理成本高昂。这导致了减少生成中的采样步骤的努力 [32],[29],包括一致性训练(CT) [33],将多步生成过程减少到 2 步。然而,与 ADM 相比,CT 的训练成本更高(例如 ADM-IP 使用 75M 图像和 CT 使用 409M 图像在CIFAR-10 上达到类似的性能),并在生成质量方面表现不佳。
3. 方法
A. 线性加法注意力(Lada)
LadaGAN 的注意力机制受到 Fastformer 的加法注意力的强烈启发 [15]。这种高效的 𝑂(𝑁) Transformer 架构最初是为了文本处理而设计的,与原始的点积注意力相比,可以在计算成本的一小部分内实现可比较的长文本建模性能。与计算输入序列向量之间的成对交互不同,Fastformer 的加法注意力通过使用从 query 中计算的单一注意力向量创建一个全局向量,总结整个序列。
具体而言,这种线性加法注意力通过将相应的查询向量 q_𝑖 ∈ R^𝑑 投影到一个向量 w ∈ R^𝑑 上来计算每个权重,即:
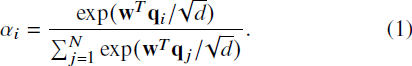
其中 𝑑 是注意力头的维度。
(注:不同于传统注意力的矩阵乘法,这里使用单一的向量 w 计算注意力权重,计算复杂度从二次变为线性。但问题里,文章中没有给出 w 如何获得)
为了建模交互,全局向量的计算如下:

对每个 key 向量 k_𝑖 ∈ R^𝑑 和 g 进行逐元素操作,以传播学到的信息,得到一个向量 p_𝑖 ∈ R^𝑑,使得
![]()
其中符号 ⊙ 表示逐元素乘积。与 Fastformer [15] 不同,LadaGAN 的注意力机制不计算 key 的全局向量;相反,对每个向量 p_𝑖 和相应的 value 向量 v_𝑖 ∈ R^𝑑 进行逐元素操作。该操作允许传播注意力权重 𝛼_𝑖,𝑖 = 1, . . . , 𝑁 的信息而不是压缩它。最后,我们计算每个输出向量 r_𝑖 ∈ R^𝑑,如下所示:
![]()

B. Ladaformer
生成器和鉴别器的主要块是 Ladaformer,它遵循视觉 Transformer(ViT)架构 [12],如图 1 所示。然而,由于引入自调制已经显示出是提高性能的有效策略 [35],[7],LadaGAN 生成器块使用自调制层归一化,而不是标准层归一化。具体而言,第 ? 层的输入 h_? 的层归一化参数通过如下调整进行适应:
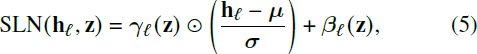
其中除法操作是逐元素进行的。 请注意,这与 ViTGAN 的自调制层归一化略有不同,后者通过将潜在向量 z 通过投影网络进行处理并计算出一个向量 w,然后将其注入;相比之下,LadaGAN 直接注入 z。此外,与 ViT、ViTGAN 和 Fastformer 不同,LadaGAN 生成器没有从注意力模块的输出到多层感知机(MLP)的输出的残余连接。
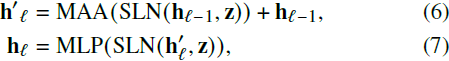
其中 MAA(·) 表示多头线性加法注意力,而 MLP(·) 是一个两层全连接网络,第一层使用 GELU 激活函数。
C. 生成器
LadaGAN 生成器采用像素洗牌(pixel shuffle)操作逐渐将潜在向量转换为图像。这个操作是一种常见的增加空间分辨率的技术,其中输入从 (𝐵,𝐶 × 𝑟^2, 𝐻,𝑊) 重塑为 (𝐵,𝐶, 𝐻 × 𝑟,𝑊 × 𝑟),其中 𝑟 是一个缩放因子,𝐵 是批量大小,𝐶 是输出通道数,𝐻 和 𝑊 分别是输入的高度和宽度。尽管这个技术最初被提出作为超分辨率架构中标准 ConvNet-based 上采样的有效替代方法,但它已被广泛应用于图像生成 Transformer,包括最近的 Transformer GANs。
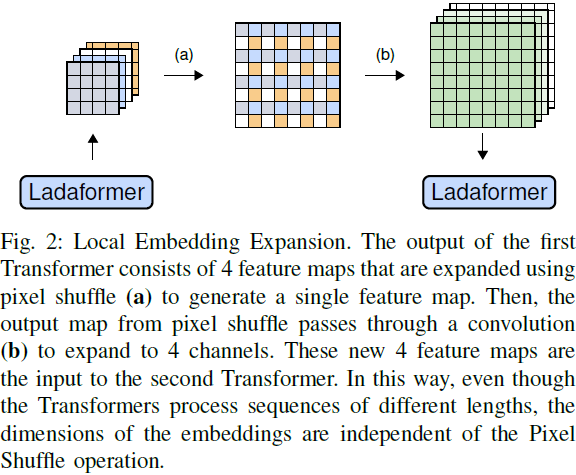
由于像素洗牌操作减少了输入中的通道数 𝐶(图 2 中的过程 (a)),因此我们在此操作之后应用一个卷积层来增加通道数;我们将这个操作称为嵌入的局部扩展(Local Expansion of the Embedding):
![]()
其中 Conv(·) 是一个具有 𝐾 个滤波器的标准卷积层,而 PixelShuffle(·) 表示像素洗牌操作,其中 𝑟 = 2。
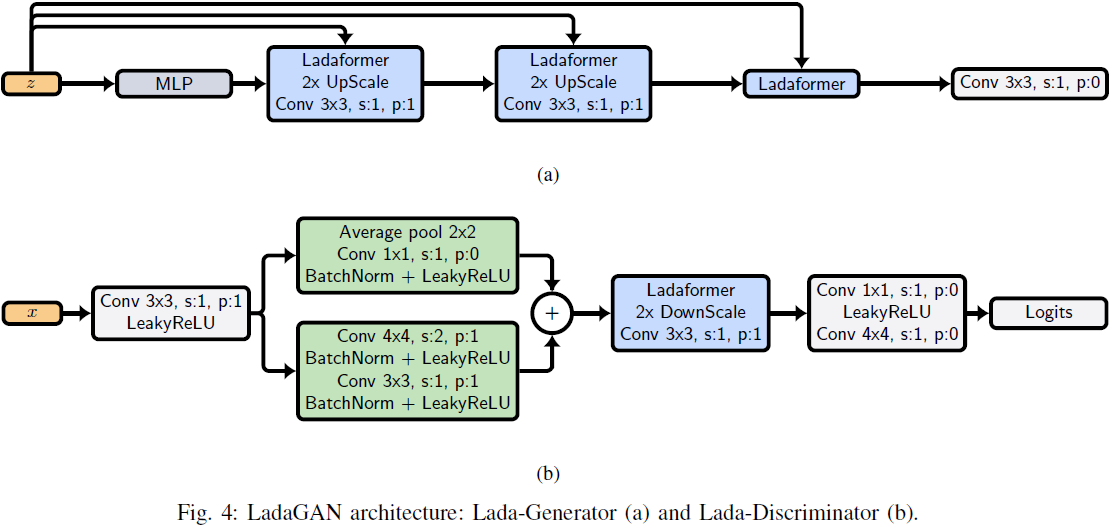
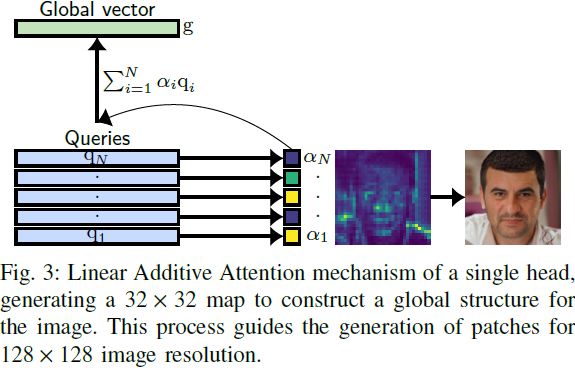
LadaGAN 生成器对分辨率为 32×32、64×64、128×128 和 256×256 的情况使用相同的架构,包括三个 Ladaformer 块,如图 4(a) 所示。由于增加 Transformer 模型的序列长度通常提高了自然语言处理任务的性能,我们认为在图像生成任务中也可以获得类似的好处。因此,利用 Ladaformer 块的 𝑂(𝑁) 复杂性,我们的目标是生成一个长序列(1024 个标记)作为最终 Transformer 块的输出。
给定潜在向量 z ∈ R^(𝐷_𝑧) 和 𝐿 个 Transformer 块,LadaGAN 生成器的操作如下:

其中 ? = 1, . . . , 𝐿,Linear(·) 表示线性投影
![]()
分别是块 𝐿 和 ? ? 1 的位置嵌入,X ∈ R^(𝐻×𝑊×𝐶) 是输出图像。请注意,在方程 13 中的最后一个卷积层和每个像素洗牌操作之前,都会执行一个 reshape 操作来生成一个 2D 特征图。另一方面,如果方程 11 中 LEE 卷积的输出通道数等于输入通道数,则不会扩展嵌入维度。这导致卷积只加强像素洗牌的局部性。图 3 显示了 LadaGAN 的生成过程。
D. 鉴别器
LadaGAN 鉴别器类似于 FastGAN [36] 鉴别器,但使用 Ladaformer 而不是残差卷积块;LadaGAN 鉴别器的架构如图 4(b) 所示。Lada 与卷积的兼容性允许将类似于 FastGAN 的残差块 [36] 作为输入馈送到 Ladaformer。我们发现,将 Ladaformer 和类似于 FastGAN 的残差块 [37] 结合使用可以实现稳定性。特别是,在卷积特征提取器中,批量归一化模块 [37] 对于补充 Lada 鉴别器的稳定性至关重要。请注意,批量归一化通常不被 Transformer 鉴别器所采用,例如 ViTGAN 和 TransGAN。
与 LadaGAN 生成器不同,鉴别器 Ladaformer 块具有标准的 MLP 残差连接,如图 1(b) 所示。此外,在输出时执行 SpaceToDepth(·) 操作。与 PixelShuffle(·) 相反,SpaceToDepth(·) 通过将输入从? (𝐵,𝐶, 𝐻 × 𝑟,𝑊 × 𝑟) 重塑为 (𝐵,𝐶 × 𝑟2, 𝐻,𝑊) 对输入进行下采样。与 TransGAN 和 ViT 鉴别器的最后一层使用类嵌入 [38] 不同,LadaGAN 鉴别器的最后一层由步长为 2 的卷积层组成。通过这种方式,卷积逐渐减小注意力图的表示。
E. 损失函数
LadaGAN 采用标准的非饱和逻辑 GAN 损失与 R1 梯度惩罚 [39]。R1 项对真实数据上的梯度进行惩罚,使模型能够收敛到一个良好的解。因此,在具有卷积鉴别器的最先进的 GANs 中,它被广泛采用。具体而言,损失函数定义如下:
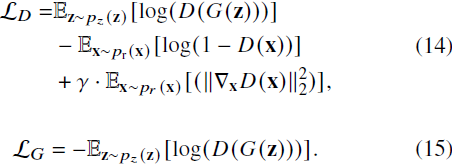
请注意,Lada 的稳定性允许在具有梯度惩罚的 𝑂(𝑁) Transformer 鉴别器上进行训练。这是特别重要的,因为已经发现点积 Transformer 鉴别器和梯度惩罚不兼容 [7],通常会导致训练不稳定。?
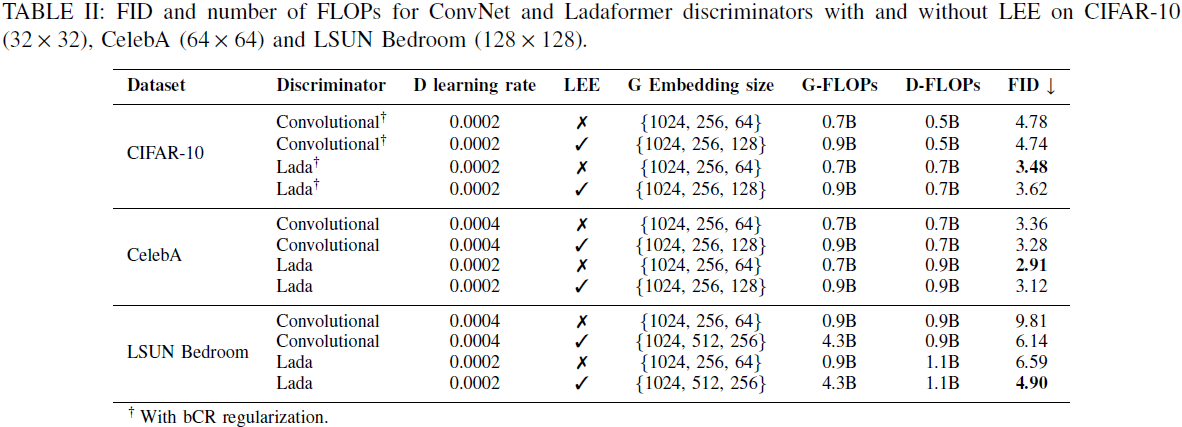
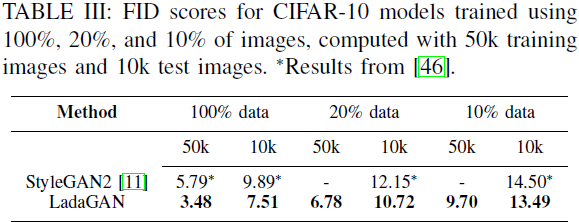
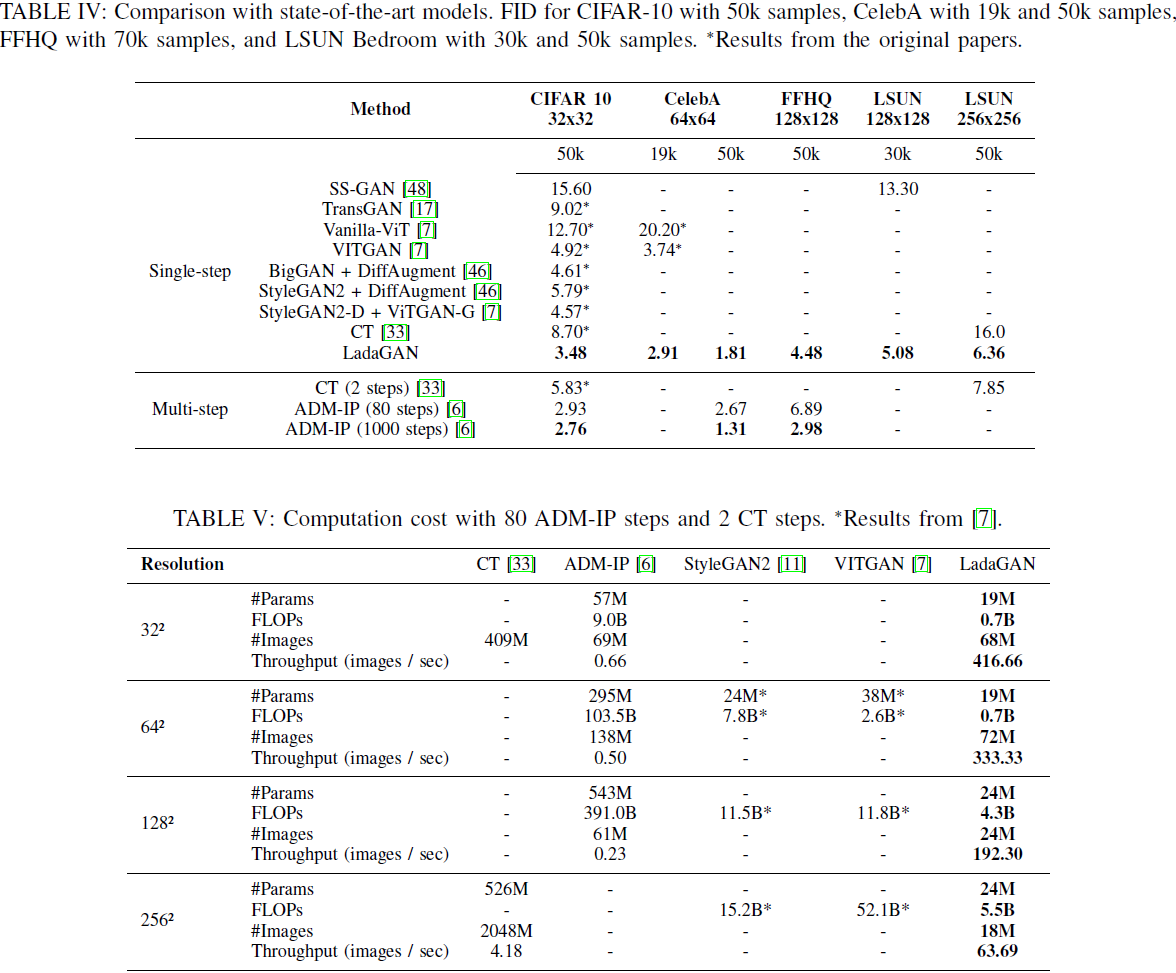
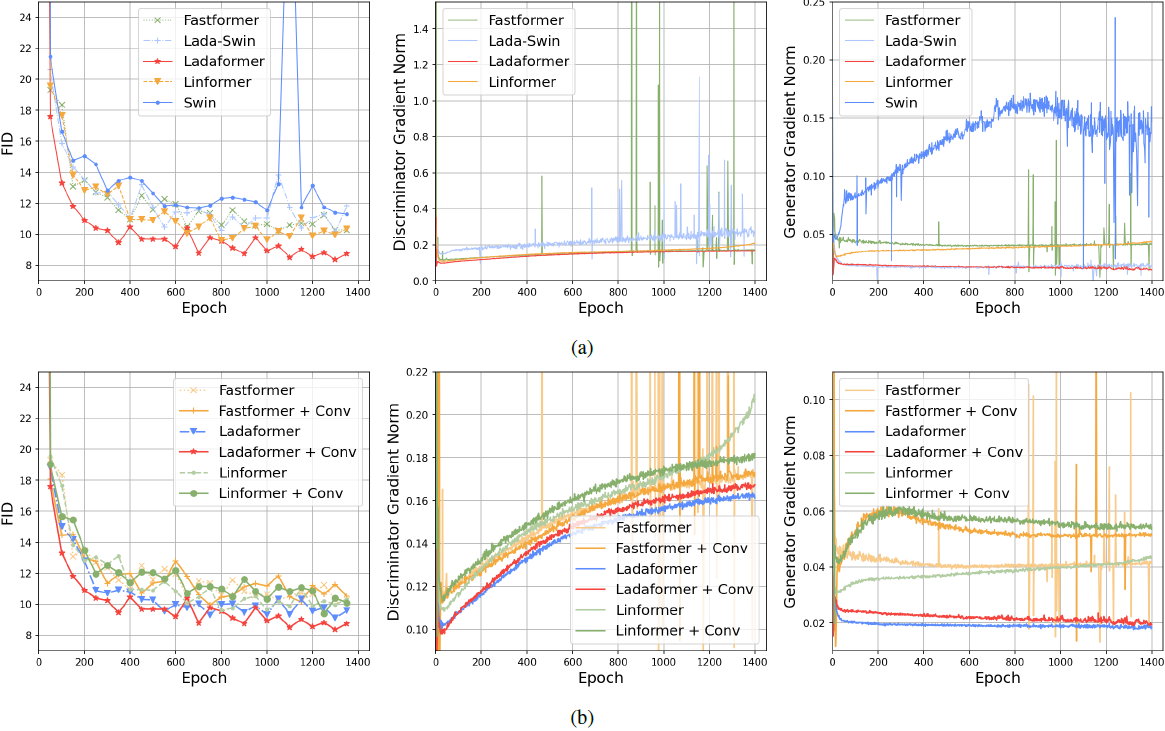
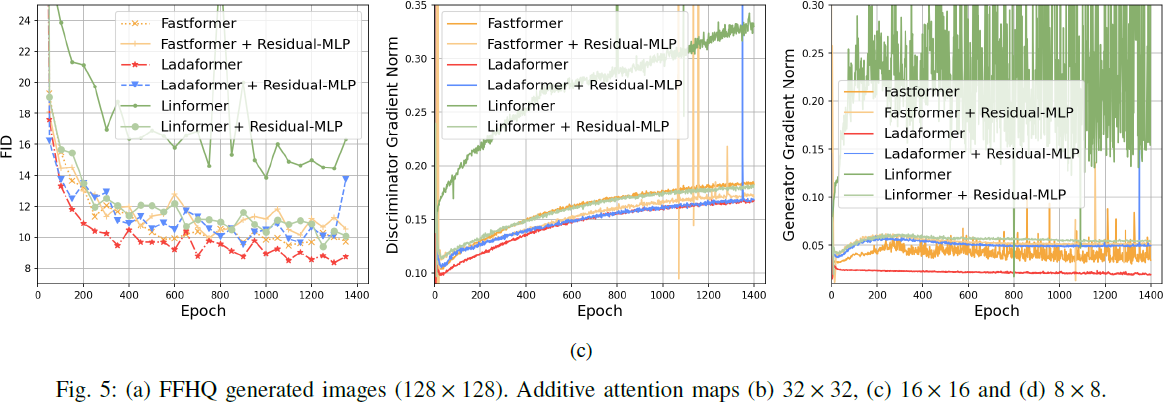
4. 实验
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用集群提交作业步骤
- C# 执行多条语句实现事务
- ThinkPHP5.0.0~5.0.23路由控制不严谨导致的RCE
- nvcc -V显示command not found
- JavaWeb笔记之前端开发JQuery
- springboot/java/php/node/python地摊管理系统【计算机毕设】
- 【shell-09】 shell控制台颜色输出
- 2024/1/16 DFS BFS
- 深度剖析C语言数据在类型中的存储之浮点型在内存中的存储
- Leetcode 剑指 Offer II 058. 我的日程安排表 I