C语言总结九:数据的存储详细总结
? ? ? ?了解数据在内存中的存储能够更好的加深对于计算机的数据的理解,对于排除错误和加深对C语言的理解至关重要,本篇博客主要总结整数和浮点数在内存中的存储方式,相信学完本篇博客,会有更大的收获!
一、数据类型介绍
1.1 基本内置类型

类型的意义:
? ? ??1. 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
? ? ? 2. 如何看待内存空间的视角。数据的存储方式
注意事项:
? ? ? 1. C语言没有字符串类型,存储字符串用的是字符数组(栈区)或者字符串指针(常量区)。
? ? ? 2. 对于long类型字节的规定:c语言对long定义的标准:sizeof(long) >= sizeof(int)
? ? ? ? ?在32位机器:占用4字节,在64位机器:占用8字节。? ? ? 3.?C语言没有内置布尔类型bool,C语言其实原来并没有为布尔值单独设置一个类型,而? ? ? ? ? ?是使用整数
0在表示假,非零表示真。在C99中也引入了布尔类型,是专门表示真假。? ? ? ? ? ? ?布尔类型变量的取值是:true或者false。
二、类型的基本归类
2.0 signed 和 unsigned的理解
(1)signed和unsigned关键字用于指定整数类型的符号:
- ?signed: 有符号整数类型,可以表示正数和负数。默认情况下所有整数类型(char、short、int、long)都是signed的。
- ?unsigned: 无符号整数类型,只能表示非负整数,范围比signed类型更大。
(2)主要区别:
- 存储表示:signed类型用二进制最高位表示数值的符号,正数为0,负数为1。unsigned类型最高位都是数值本身,不表示符号。
- 数值范围:signed类型的范围依赖于其位宽。unsigned类型没有符号位,所以范围比signed类型更大。
2.1 整型家族

更长的整型 //C99中引入?long long:占用8个字节,默认情况下为:signed
- ?signed?long long
- ?unsigned long long?
以char类型为例:
(1)?signed char表示的数值范围:最高位为符号位,0表示正数,1表示负数。


(2)unsigned char表示的数值范围:全部为数值位。


其他整型类型同理,下面给出表格:

2.2 浮点数家族

单精度浮点数:精度低,存储数值范围小;
双精度浮点数:精度高,存储数值范围大。
2.4 构造类型
? ? ? ?构造类型也成为自定义类型,主要包括以下内容:

//数组是一组相同类型数据的集合,也可认为是自定义类型
如: int arr[10]={0} 类型为:int [10]
如: char arr[10]={0} 类型为:char [10]2.5?指针类型
- 字符指针 char *
- 短整型指针 short *
- 整型指针 int *
- void *
- ...
注意事项:
? ? ? 指针大小只与平台有关,与类型无关,x86(32位)指针占4个字节大小,x64(64位)指针占8个字节大小。那么为什么指针还要分类型?指针类型的意义在哪里?
1、指针的类型决定了指针解引用访问数据的访问权限,访问的字节数;
2、指针的类型决定了指针走一步能走多大步,即指针+1的能力!
2.6?空类型
void 空类型
? ? ? ? ?通常用于函数的返回类型,函数的参数,指针类型
三、整型在内存中的存储
3.1 原码、反码、补码
? ? ? ?这一节在上一期已经总结过,这里简单说明。

3.2 大小端介绍
3.2.1 什么是大小端?
- 大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址 中;
- 小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地 址中。

3.2.2 为什么会有大小端?
为什么会有大小端模式之分呢?
? ? ? ?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short 型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32 位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。 例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为 高字节,0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中,0x22 放在高 地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则 为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
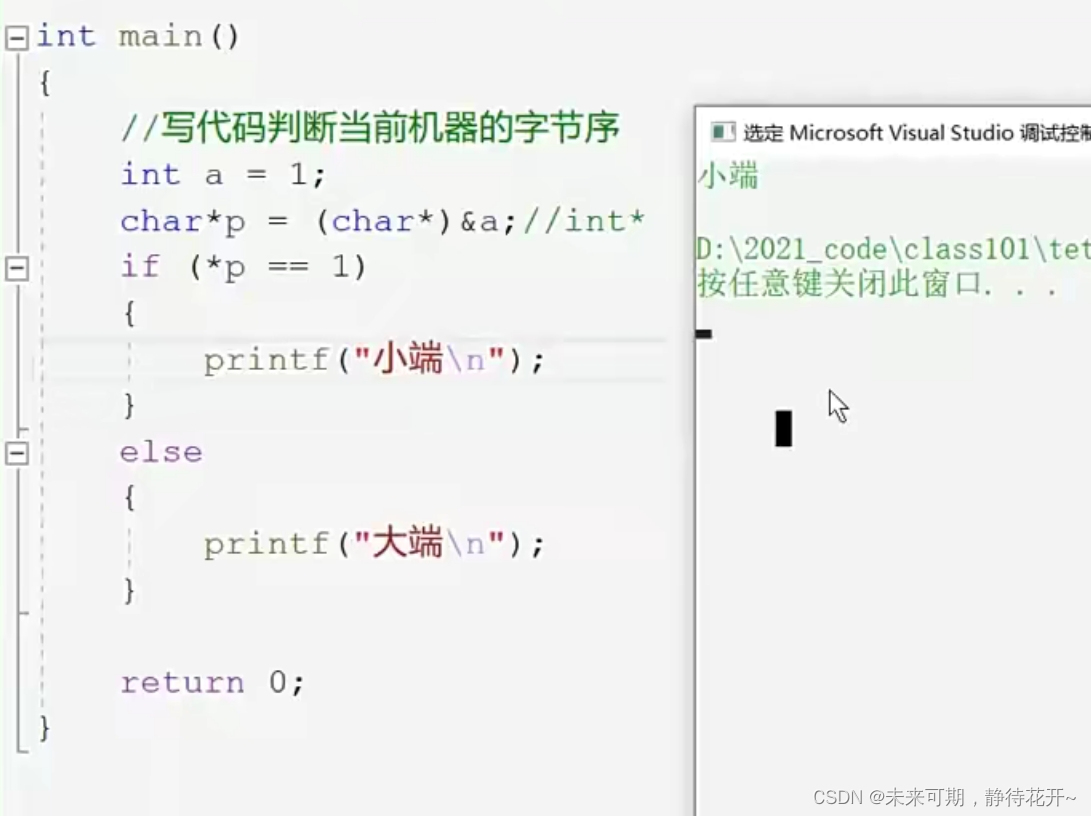
设计一个小程序判断当前机器的字节序
思路:
? ? ? ?假设int a = 1 时,a的补码转换成16进制0x00000001,取a的第一个字节的内容,即从低地址取一个字节的内容;如果第一个字节为01,则为小端字节序;如果第一个字节为00,则为大端字节序。?
?

3.3 练习
3.3.1?整型值赋值给signed char和unsigned char
解题入手点:
- 将整型值转换为补码二进制
- 截断,将整型值的补码的低八位存储到signed char或unsigned char变量中
- 输出时,signed char和unsigned char都需要需要整型提升;
- 将signed char的整型提升后的补码转换成原码后输出,unsigned char直接输出。
(1)%d打印该二进制序列(补码)对应的有符号的十进制数(认为这个数的最高位是符号位),如果最高位是0,代表是正数,不需要转换原码,如果最高位是1,代表是负数,需要转换成原码,然后输出。
(2)%u打印该二进制序列(补码)对应的无符号的十进制数(认为这个数全是数值位),不需要转换成原码,直接计算输出。
(1)将整型值-1分别赋值分signed char和unsigned char
1.//输出什么?
#include <stdio.h>
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d\nb=%d\nc=%d", a, b, c);
return 0;
}

结果分析:
-1的二进制如下:
原码->1000 0000 0000 0000 0000 0000 0000 0001
反码->1111 1111 1111 1111 1111 1111 1111 1110
补码->1111 1111 1111 1111 1111 1111 1111 1111
-1的低八位:1111 1111
则变量a 的二进制位:1111 1111
? ? ? ? 变量b的二进制:1111 1111
? ? ? ? 变量c的二进制:1111 1111
输出:%d为有符号的十进制整型值打印,a,b,c为char,需要进行整型提升
a和b为符号数,则整型提升的二进制如下:
补码->1111 1111 1111 1111 1111 1111 1111 1111 1111 ,%d打印认为它是有符号数,且最高位为1,是负数,因此需要转换成原码。
原码->1000 0000 0000 0000 0000 0000 0000 0001->十进制为-1
c为无符号数,整型提升的二进制如下
补码->0000 0000 0000 0000 0000 0000 1111 1111
%d打印认为它是有符号数,且最高位为0,是正数,因此不需要转换成原码。
原码->0000 0000 0000 0000 0000 0000 1111 1111->十进制为255
(2)将整型值-128赋值给signed char?
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n",a);
printf("%d\n",a);
return 0;
}

结果分析:
-128的二进制如下
原码->10000000 00000000 00000000 10000000
反码->1111 1111 1111 1111 1111 1111 0111 1111
补码->1111 1111 1111 1111 1111 1111 1000 0000
-128的低八位:1000 0000
a存储的二进制为:1000 0000
输出:
%u打印该二进制序列(补码)对应的无符号的十进制数(认为这个数全是数值位),不需要转换成原码,直接计算输出。
a为char,则需要进行整型提升,整型提升的二进制如下
补码->1111 1111 1111 1111 1111 1111 1000 0000
将整型提升的补码直接输出
? ? ? ? ? ?1111 1111 1111 1111 1111 1111 1000 0000->十进制4294967168%d打印该二进制序列(补码)对应的有符号的十进制数(认为这个数的最高位是符号位),如果最高位是0,代表是正数,不需要转换原码,如果最高位是1,代表是负数,需要转换成原码,然后输出。
整型提升的二进制
补码->1111 1111 1111 1111 1111 1111 1000 0000,最高位为1,代表是负数,需要转换成原码再输出对应的十进制数
原码->1000 0000 0000 0000 0000 0000 1000 0000->十进制-128
?(3)?将整型值128赋值给signed char
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n",a);
printf("%d\n",a);
return 0;
}
结果分析:
?128的二进制如下(正整数原码、补码、反码相同)
补码->0000 0000 0000 0000 0000 0000 1000 0000
128的低八位1000 0000
a存储的二进制:1000 0000输出:
%u打印该二进制序列(补码)对应的无符号的十进制数(认为这个数全是数值位),不需要转换成原码,直接计算输出。
a为char,则需要进行整型提升,整型提升的二进制如下
补码->1111 1111 1111 1111 1111 1111 1000 0000
将整型提升的补码直接输出:
? ? ? ? ? ?1111 1111 1111 1111 1111 1111 1000 0000->十进制4294967168%d打印该二进制序列(补码)对应的有符号的十进制数(认为这个数的最高位是符号位),如果最高位是0,代表是正数,不需要转换原码,如果最高位是1,代表是负数,需要转换成原码,然后输出。
整型提升的二进制
补码->1111 1111 1111 1111 1111 1111 1000 0000,最高位为1,代表是负数,需要转换成原码再输出对应的十进制数
原码->1000 0000 0000 0000 0000 0000 1000 0000->十进制-128
(4) 无符号数与有符号数计算输出
#include <stdio.h>
int main()
{
int i= -20;
unsigned int j = 10;
printf("%d\n", i+j); //按照补码的形式进行运算,最后格式化成为有符号整数
printf("%u\n", i+j);
return 0;
}

?结果分析:
? ? ?-20的二进制序列补码如下:
原码->1000 0000 0000 0000 0000 0000 0001?0100反码->1111? 1111 1111 1111 1111 1111 1110 1011
补码->1111? 1111?1111 1111 1111 1111 1110 1100
? ? ?10的二进制序列补码如下:补码->0000 0000 0000 0000 0000 0000 0000?1010
两个相加结果如下:
? ? ? ? ??1111? 1111?1111 1111 1111 1111? 1111 0110
输出:
%d打印该二进制序列(补码)对应的有符号的十进制数(认为这个数的最高位是符号位),如果最高位是0,代表是正数,不需要转换原码,如果最高位是1,代表是负数,需要转换成原码,然后输出。
? ? ?观察结果的补码,最高位为1,代表是负数,需要转换成原码:补码:?1111? 1111?1111 1111 1111 1111? 1111 0110
反码:?1000 0000 0000 0000 0000 0000 0000 1001
原码:?1000 0000 0000 0000 0000 0000 0000 1010->十进制数-10
?%u打印该二进制序列(补码)对应的无符号的十进制数(认为这个数全是数值位),不需要转换成原码,直接计算输出。
两个相加结果如下:
? ? ? ? ??1111? 1111?1111 1111 1111 1111? 1111 0110?
全部当成数值位,直接将补码输出,? ??1111? 1111?1111 1111 1111 1111? 1111 0110?->十进制数4294967286
?(5)将负数赋值给unsigned int
#include <stdio.h>
int main()
{
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
sleep(1000)
}
return 0;
}
?
?结果分析:
?当i变为-1时
-1的二进制如下:
原码->1000 0000 0000 0000 0000 0000 0000 0001
反码->1111 1111 1111 1111 1111 1111 1111 1110
补码->1111 1111 1111 1111 1111 1111 1111 1111
将二进制1111 1111 1111 1111 1111 1111 1111 1111保存到unsigned int变量i中
1111 1111 1111 1111 1111 1111 1111 1111->十进制为4294967295
程序陷入无限循环。
(无符号数永远大于等于0,上限取决于位宽,因此会陷入死循环)
?(6)将-1,-2…-1000依次赋值给char str[1000]
#include <stdio.h>
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}
?结果分析:
char的取值范围[-128,127]
str[0] = -1,str[1] = -2…str[127] = -128;
当str[128] = -129时,超出char的取值范围时,则
-129的二进制
原码->1000 0000 0000 0000 0000 0000 1000 0001
反码->1111 1111 1111 1111 1111 1111 0111 1110
补码->1111 1111 1111 1111 1111 1111 0111 1111
str[128]存储的二进制为0111 1111
二进制0111 1111->十进制127
直到str[255] = -256时,
-256的二进制
原码->1000 0000 0000 0000 0000 0001 0000 0000
反码->1111 1111 1111 1111 1111 1110 1111 1111
补码->1111 1111 1111 1111 1111 1111 0000 0000
str[255]存储的二进制为0000 0000->十进制0,0对应的字符为’\0’
?

?(7)死循环问题
#include <stdio.h>
int main()
{
unsigned char i = 0;
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}?
?结果分析:
? ? ? 无符号数char取值范围:0-255,恒成立,陷入死循环!
四、浮点型在内存中的存储
浮点型家族
- float
- double
- long double(c99)的范围在<float.h>头文件中定义
整型家族表示范围在<limits.h>头文件中定义
4.1 浮点数存储例子

num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大? 要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法
4.2 浮点数在内存中的存储格式
4.2.1 浮点数的表示形式
根据国际标准IEEE754,任意一个二进制浮点数V可以写成:
浮点数公式:(-1)^S * M * 2^E
- S表示符号位,0表示正数,1表示负数;
- M表示有效数字, 1 <= M < 2;
- E表示指数位
例子1:
假设一个十进制浮点数V = 5.0f,化成二进制为101.0
根据二进制科学计数法,101.0 -> 1.01 * (2 ^ 2)-> (-1)^0 * 1.01 * (2^2)
则此时S = 0、M = 1.01、E = 2
例子2:
假设一个十进制浮点数V = 9.5f,化成二进制为1001.1
根据二进制科学计数法,1001.1->1.0011 * (2 ^ 3) -> (-1)^0 * 1.0011 * (2^3)
则此时S = 0、M = 1.0011、E = 3
4.2.2 浮点数的存储格式


4.3 IEEE 754对有效数字M和指数E的规定
4.3.1 对存储有效数字M的规定
1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。 IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的 xxxxxx部分。比如保存1.01的时 候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位 浮点数为例,留给M只有23位, 将第一位的1舍去以后,等于可以保存24位有效数字。
4.3.2 对存储指数E的规定
? ? ? 首先,E为一个无符号整数(unsigned int) 这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们 知道,科学计数法中的E是可以出 现负数的!如何解决呢?
? ? ? ? IEEE754规定,存入内存的值为E的真实值再加上一个中间值
下面根据不同位数进行叙述:
(1)E在32位浮点数的存储格式
E的取值范围:0~255
E的中间值:127
存储值 = 真实值+中间值
例如:
当一个浮点数的指数为2^10时,E的真实值为10,则存储值 = 10 + 127 = 137,即10001001,不够23位,用0补齐
则M在内存的表示为 1000 1001 0000 0000 0000 000
(2)E在64位浮点数的存储格式
E的取值范围:0~2047
E的中间值:1023
存储值 = 真实值+中间值


4.3.3 对读取有效数M和指数E的规定
(1)当E在内存存储的值不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
(2) 当E在内存存储的值为全0时
浮点数的指数E的真实值 = (1 - 127) 或 (1-1023)
有效数字M不再加上第一位1,而是还原为0.xxx的小数。
这样做是为了表示正负0,以及接近于0的很小的数。
(3)当E在内存存储的值为全1时
这时,如果有效数字M全为1,表示正负无穷大(正负取决于符号位S)

? ?以上便是数据存储的所有内容, 相信你一定大有收获,可以留下你们点赞、关注、评论,您的支持是对我极大的鼓励,下期再见!?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 支付宝小程序源码系统:自由DIY+完整的安装部署教程
- C/C++ 递增/递减运算符和指针
- 人工智能如何改变未来的教育
- LDR6020 | 140W智能分配一拖二快充数据线
- 基于ssm的药品销售网站的设计与实现(源码+LW+调试)
- 【BERT】深入理解BERT模型1——模型整体架构介绍
- linux安装tomcat
- 认定高新技术企业可获得哪些资金优惠?
- WndProc函数(窗口消息处理函数)
- lxml,一个超实用的 Python 库!