【Java并发】聊聊concurrentHashMap的put核心流程
发布时间:2024年01月09日
结构介绍
1.8中concurrentHashMap采用数组+链表+红黑树的方式存储,并且采用CAS+SYN的方式。在1.7中主要采用的是数组+链表,segment分段锁+reentrantlock。本篇主要在1.8基础上介绍下.
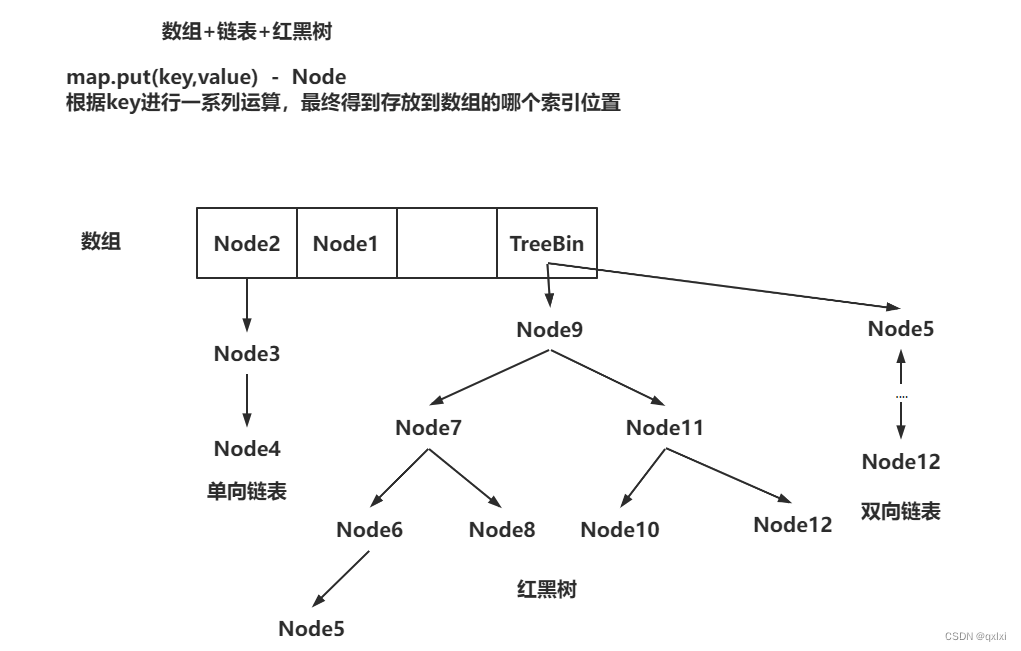
那么,我们的主要重点是分析什么呢,其实主要就是put 的整体流程。数组如何初始化,添加到数组、链表、红黑树、以及对应的扩容机制。
//添加数据
public V put(K key, V value) {
return putVal(key, value, false);
}
散列函数
put方法实际上调用的是putVal()方法。
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 1.判断为空 直接返回空指针
if (key == null || value == null) throw new NullPointerException();// key和value不允许null
int hash = spread(key.hashCode());//两次hash,减少hash冲突,可以均匀分布
}
这里为什么要对 h >>> 16 ,然后在进行 异或运算 & 操作。
其实主要还是为了让hash高16位也参与到索引位置的计算中。减少hash冲突。
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
我们假设h 位 :00011000 00000110 00111000 00001100
00011000 00000110 00111000 00001100 h
^
00000000 00000000 00011000 00000110 h >>> 16
00011000 00000110 00111000 00001100
&
00000000 00000000 00000111 11111111 2048 - 1
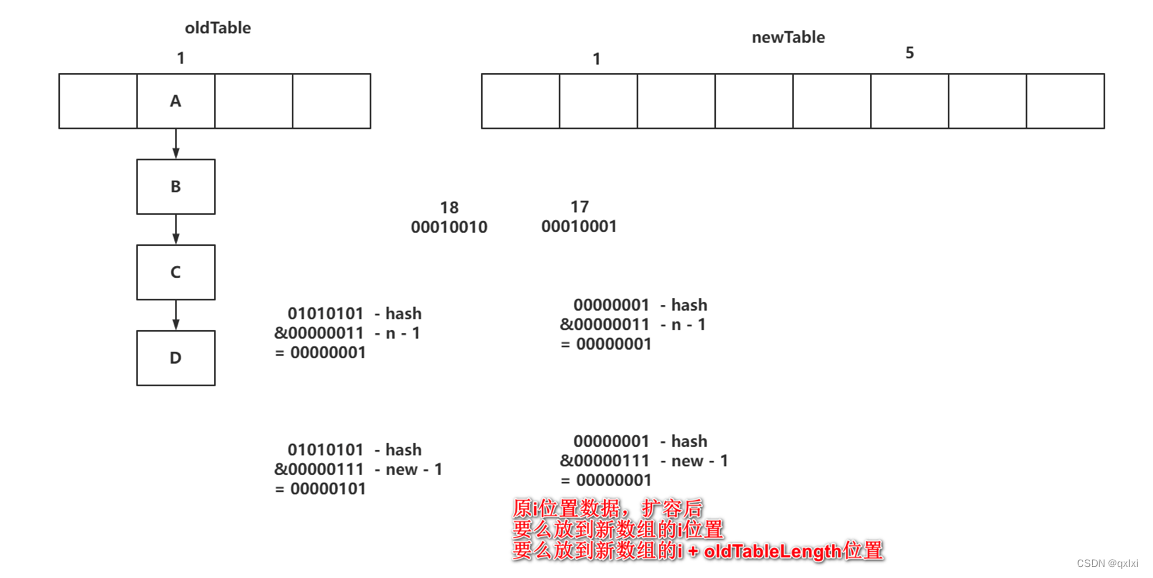
ConcurrentHashMap是如何根据hash值,计算存储的位置?
(数组长度 - 1) & (h ^ (h >>> 16))
00011000 00000110 00110000 00001100 key1-hash
00011000 00000110 00111000 00001100 key2-hash
&
00000000 00000000 00000111 11111111 2048 - 1
Node中的hash值除了可能是数据的hash值,也可能是负数。
// static final int MOVED = -1; // 代表当前位置数据在扩容,并且数据已经迁移到了新数组
// static final int TREEBIN = -2; // 代表当前索引位置下,是一个红黑树。 转红黑树,TreeBin有参构造
// static final int RESERVED = -3; // 代表当前索引位置已经被占了,但是值还没放进去呢。 compute方法
初始化数组
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();// key和value不允许null
int hash = spread(key.hashCode());//两次hash,减少hash冲突,可以均匀分布
int binCount = 0;//i处结点标志,0: 未加入新结点, 2: TreeBin或链表结点数, 其它:链表结点数。主要用于每次加入结点后查看是否要由链表转为红黑树
for (Node<K, V>[] tab = table; ; ) {//CAS经典写法,不成功无限重试
Node<K, V> f;
int n, i, fh;
//检查是否初始化了,如果没有,则初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
}
调用构造方法的时候,其实并没有进行初始化数组。而是延迟初始化操作。通过CAS的方式,先判断table数组为空的话,进行初始化。
/**
* 这里需要先介绍一下一个属性,sizeCtl是标识数组初始化和扩容的标识信息。
= -1 正在初始化 < -1 : 正在扩容 =0 : 代表没有初始
> 0:①当前数组没有初始化,这个值,就代表初始化的长度! ②如果已经初始化了,就代表下次扩容的阈值!
*/
private transient volatile int sizeCtl;//控制标识符
// 初始化操作数组
private final Node<K, V>[] initTable() {
Node<K, V>[] tab;
int sc;
// 先判断是否为空
while ((tab = table) == null || tab.length == 0) {
// 说明线程正在初始化或者正在扩容 线程让步
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// cas的方式将sizeCtl 修改成-1 正在初始化状态
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 再次判断数组是否初始化没有
if ((tab = table) == null || tab.length == 0) {
// 获取到数组初始化的长度 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 初始化数组 16个Node数组
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
// 赋值给table全局变量
table = tab = nt;
// 计算下次扩容的阈值 也就是*2操作
sc = n - (n >>> 2);
}
} finally {
// 将最终的阈值设置给sizeCtl
sizeCtl = sc;
}
break;
}
}
return tab;
}
添加数据-数组
数据添加到数组上(没有hash冲突)
final V putVal(K key, V value, boolean onlyIfAbsent) {
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 上面的逻辑就是初始化数组
// 通过 n-1 & hash 计算当前数据的索引位置
// f 其实就是对应位置的引用 如果这个位置为空,说明这个数组都没有添加过数据
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// CAS的方式构建一个Node阶段,然后将hash值,key,value存储到Node中
// 跳出
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 这里说明f对应的hash为move 说明当前位置数据已经迁移到新数组。
else if ((fh = f.hash) == MOVED)
// 帮助扩容完。
tab = helpTransfer(tab, f);
}
添加数据-链表
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 拿到binCount
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// n: 数组长度。 i:索引位置。 f:i位置的数据。 fh:是f的hash值
Node<K,V> f; int n, i, fh;
// 到这,说明出现了hash冲突,i位置有数据,尝试往i位置下挂数据
else {
V oldVal = null;
//上面的逻辑如果都没有走到,那么说明出现了hash冲突,
//先进行加syn 锁,注意这个锁的粒度是一个桶的粒度。
synchronized (f) {
// 再次判断
if (tabAt(tab, i) == f) {
// fh
if (fh >= 0) {
// binCount 赋值为1 记录链表中Node的长度
binCount = 1;
//e 指向数组位置数据
// 在遍历链表的过程中,会记录当前链表的个数
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 拿到当前hash值比对
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
// 走到这里,说明桶中的有元素就冲突
oldVal = e.val;
// 如果是put方法,进去覆盖值
// 如果是putIfAbsent,进去不if逻辑
if (!onlyIfAbsent)
e.val = value;
break;
}
//走到这里。说明一直遍历完毕,说明桶中没有元素冲突。
// 挂在链表的最后
Node<K,V> pred = e;
if ((e = e.next) == null) {
// 封装成一个Node节点
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 否则就是红黑树套路
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//binCount不为0
if (binCount != 0) {
// 如果>= 8 那么进行扩容操作。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
return null;
触发扩容
// 判断是否需要转红黑树 或者扩容
private final void treeifyBin(Node<K,V>[] tab, int index) {
//N : 数组 sc:sizeCtl
Node<K,V> b; int n, sc;
if (tab != null) {
// 数组长度小于64 不转红黑树 先扩容(将更多的数据落到数组上)
//只有数组长度>= 64并且链表长度达到8 才转为红黑树
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
// 转红黑树操作
// 将单向链表转换为TreeNode对象(双向链表),再通过TreeBin方法转为红黑树。
// TreeBin中保留着双向链表以及红黑树!
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
//.....
}
}
}
}
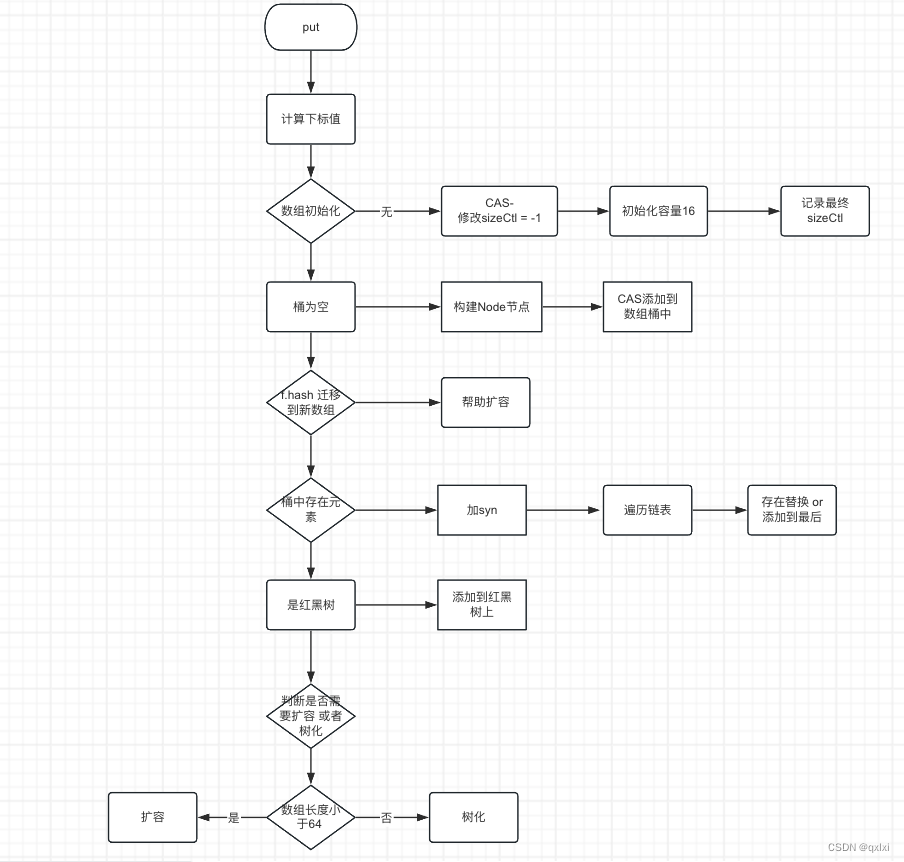
流程图
文章来源:https://blog.csdn.net/jia970426/article/details/135490877
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大厂前端面试题总结(百度、字节跳动、腾讯、小米.....),附上热乎面试经验!
- OpenGl L6坐标系统
- 在网格上获取UV对应的射线
- CSS属性position的值及其意义
- 通信入门系列——连续卷积定理、循环卷积、离散卷积定理
- mysql开启可以使用IP有权限访问
- 在Ubuntu系统中,要优化文件句柄数、线程和网络
- 线程池最佳实践!这几个坑使用不当绝对生产事故!!
- RabbitMQ的基本使用&入门
- Java并发- ABA问题