ES集群G1回收器,堆空间无法被回收问题
? ES堆空间不足的问题,困扰了我有两年的时间。dump堆去分析,也未能分析出来,堆到底是被什么占用了。 我把堆空间给了31.9G,这是指针压缩生效的临界值,如果再大就指针压缩失效了。
? 痛苦的是,随着时间的增长。堆空间在持续增长,且GC和FGC都不能把堆给回收掉。GC完了还是28G。
? 堆空间不足以后,毋庸置疑的是,会带来各种各样的问题。垃圾回收更频繁(STW会让卡着),节点通信不稳定,节点假离线、同时对写入和查询都会频繁的触发堆的父级熔断。不管是哪个问题都会导致服务不可用,大量的慢查询。
背景
垃圾回收器G1
堆空间大小:31.96G
ES集群,上百个节点
问题:GC 堆空间无法释放,老年代无法被回收。堆空间严重不足。
1.堆占用高且无法回收问题
1.1 以一个节点为例
从监控上,总是看到堆是红色的!

1.2 节点的堆利用都到达 85以上
在kibana上看监控也是这样,可以看到节点的堆利用都到达 85 以上了。?

1.3 对比GC日志
这是正常点的节点GC

多了5个?超大的regin,?old?regin?也一直回收不掉。?可用的eden分区?只有几十个。最大的问题是老年代回收不掉。
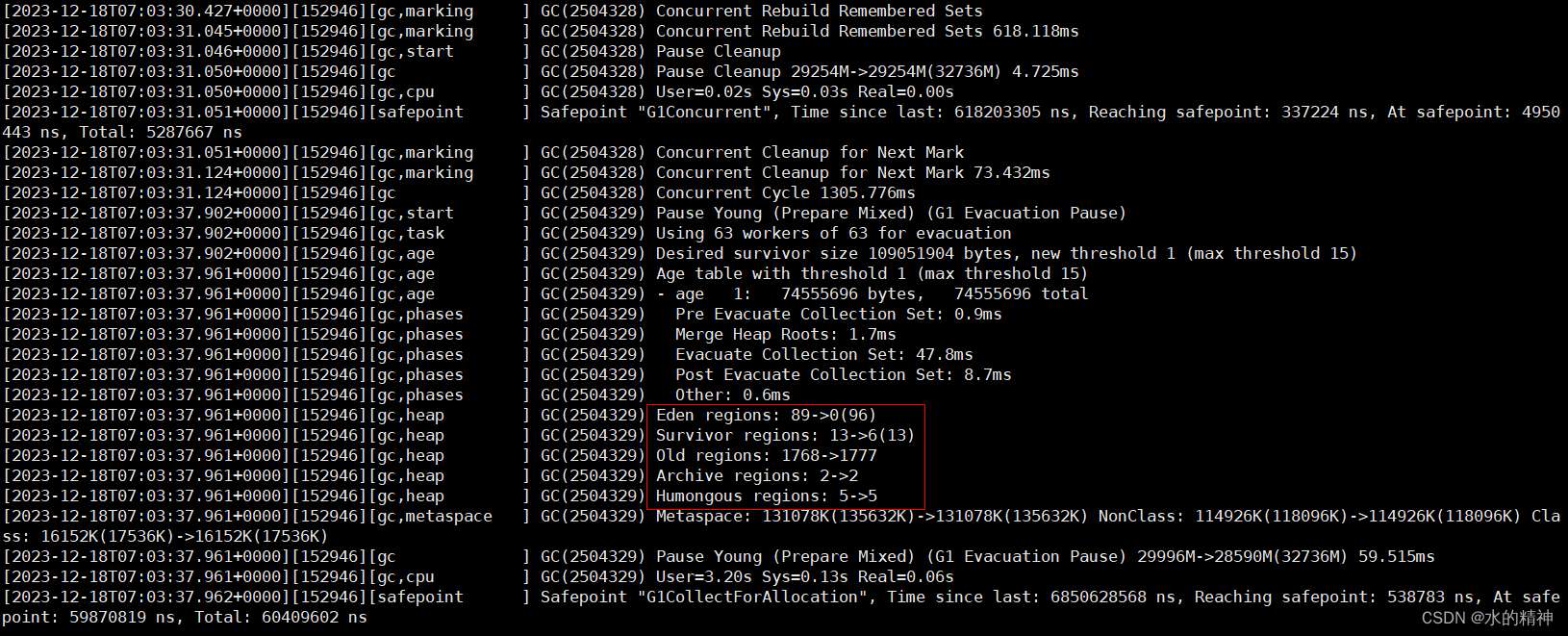
2. 无心插柳柳成荫
? 还是去想分析堆,于是去dump堆快照。在对堆打快照的时候,发现堆被正常回收了。
2.1 操作如下
2.1.1 先查看一下es的进程id
ps -ef | grep elasticsearch?进程id如下
?2.1.2 去dump堆快照
进入到节点的安装目录,然后进入到jdk目录下的bin目录下,去dump堆快照
./jmap -dump:live,format=b,file=dump.hprof 222319?打完快照时间大概在45s

快照大小25G
![]()
如果有兴趣,这里可以再进行堆的分析。?
2.1.3 堆分析结果
ES千亿级检索实战 堆OOM 问题深度分析_es oom-CSDN博客
ES堆占用高问题分析与解决方案_es占用内存太大-CSDN博客
3. 注意事项
? 在堆快照期间,节点有短暂的离线(实际上和节点重启没有什么区别,位于的区别就是节点的进程没有变化)然后再加入集群的动作。这个操作实际上是会影响到请求的延迟的。因为在快照期间,节点STW不响应集群了。已经在节点上执行的请求,还未结束的请求,会变成慢查询。等待响应。接着是master节点联系不到该节点。大概是30s的时间,master会联系3次节点,每次等10s,如果联系不上,则任务该节点掉线了。会进行把别的副本提为主分片(这里可以考虑把索引设置为多久后再分配)。然后等快照结束,节点正常和master通信,重新加入节点,然后把分片初始化进来。
4. 堆问题暂时性被解决?
? 不能说完全解决问题,但是这是目前唯一可操作的,影响最小的方案。如果有人遇到过类似的问题解决了,可以教教我(不胜感激)
? 在所有的节点都依次操作后,结果如下(几天后还是这个效果),虽然堆空间有上涨,但是是以缓慢的速度增长的。目前我还没有能力排查到到底是不是bug引起的。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 行为树保姆级教程(以机器人的任务规划为例
- 【损失函数】Cross Entropy Loss 交叉熵损失
- Linux 系统拉取 Github项目
- 文章解读与仿真程序复现思路——电力自动化设备EI\CSCD\北大核心《面向平稳氢气需求的综合制氢系统鲁棒优化配置方法》
- 19.Tomcat搭建
- wav2lip中文语音驱动人脸训练
- 电影《泰勒·斯威夫特:时代巡回演唱会》观后感
- 大学专业课—材料科学基础知识点整理
- 预约上门按摩系统开发会涉及哪些关键技术
- ACL和NAT