毕业设计:图书数据分析可视化系统 python爬虫 Flask框架 当当网 (源码)?
发布时间:2024年01月13日
大数据毕业设计:Python招聘数据采集分析可视化系统?
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业?。🍅
1、项目介绍
技术栈:
Python语言、Flask框架、网络爬虫技术、Echarts可视化、当当网数据、HTML
该系统是一个基于Python语言和Flask框架开发的图书数据爬取分析可视化系统。系统通过网络爬虫技术从当当网上爬取图书数据,并通过Echarts可视化库将数据以图表的形式展示出来。用户可以通过系统界面输入关键词进行图书搜索,系统将根据关键词从当当网上爬取相关的图书信息。
2、项目界面
(1)数据可视化大屏
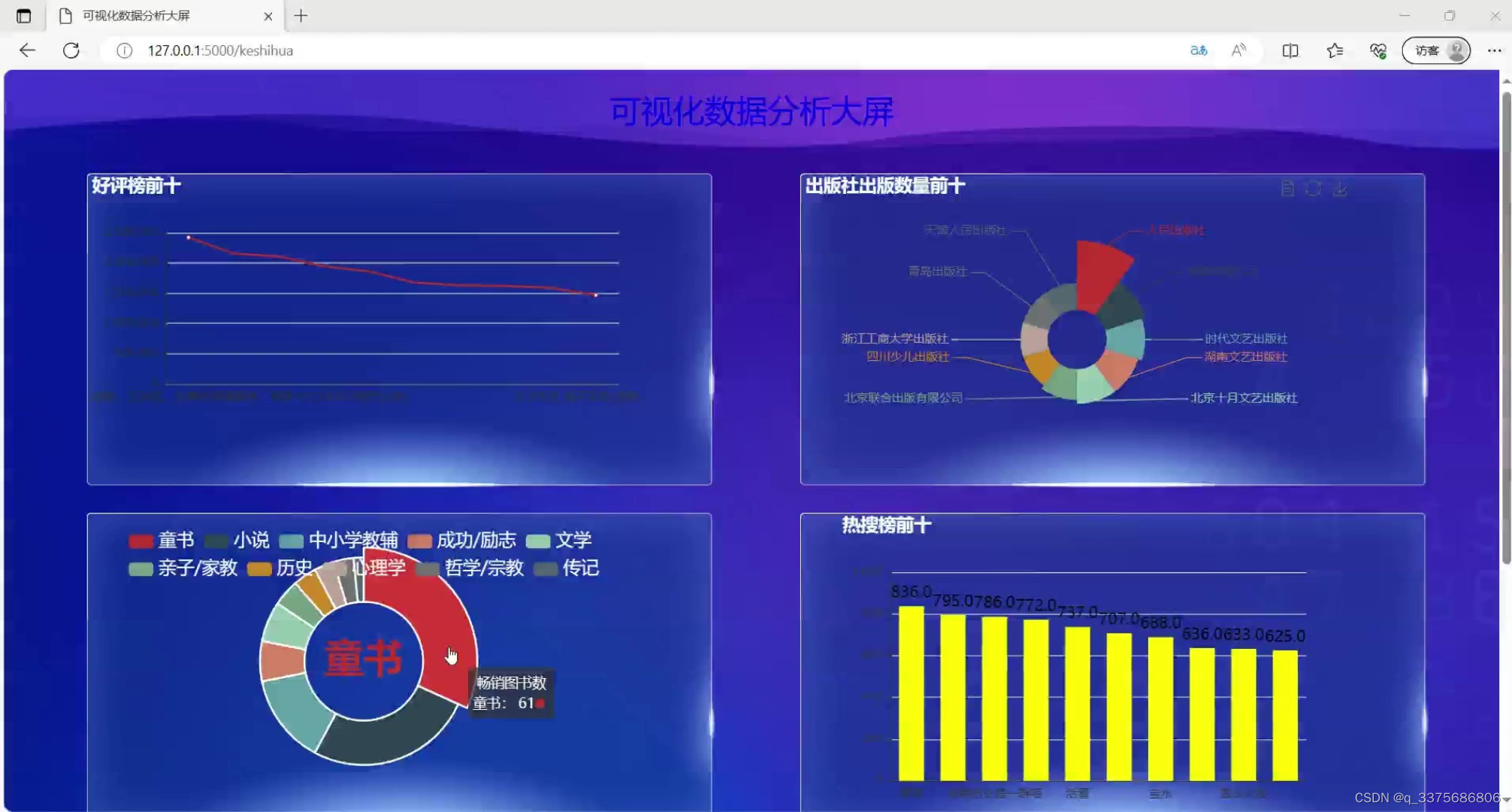
(2)图书小说作者前十
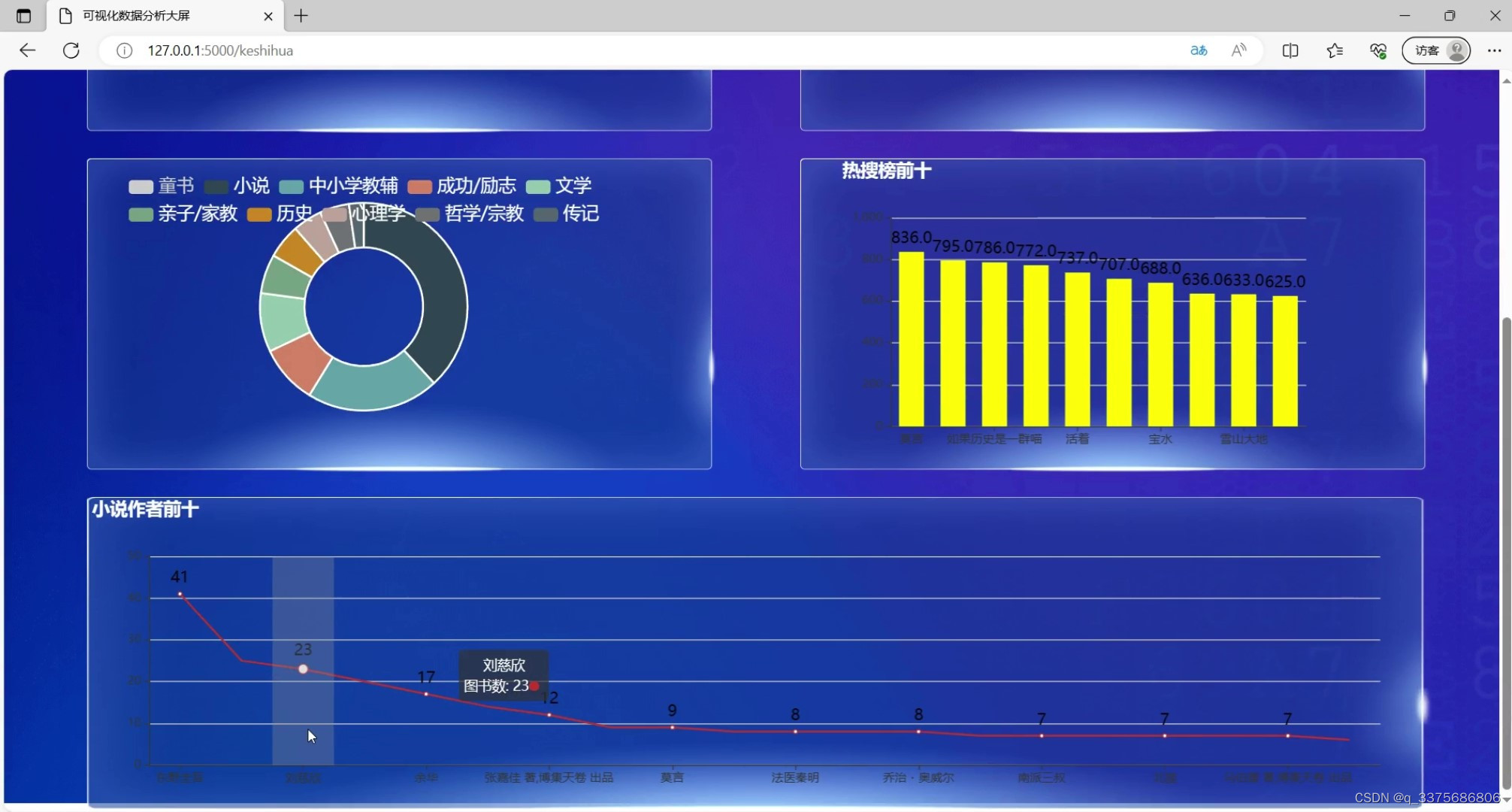
(3)图书数据浏览
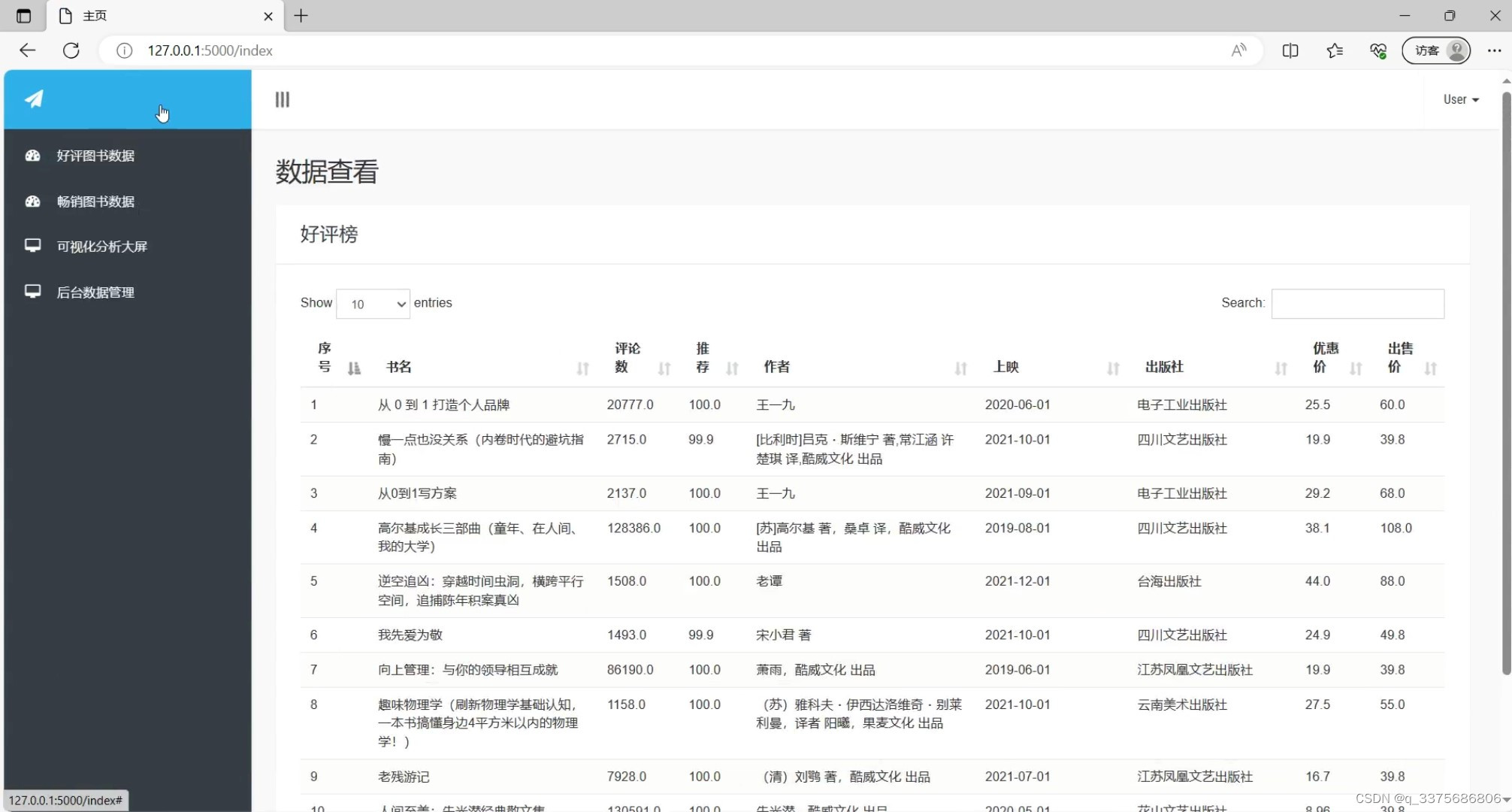
(4)图书畅销榜
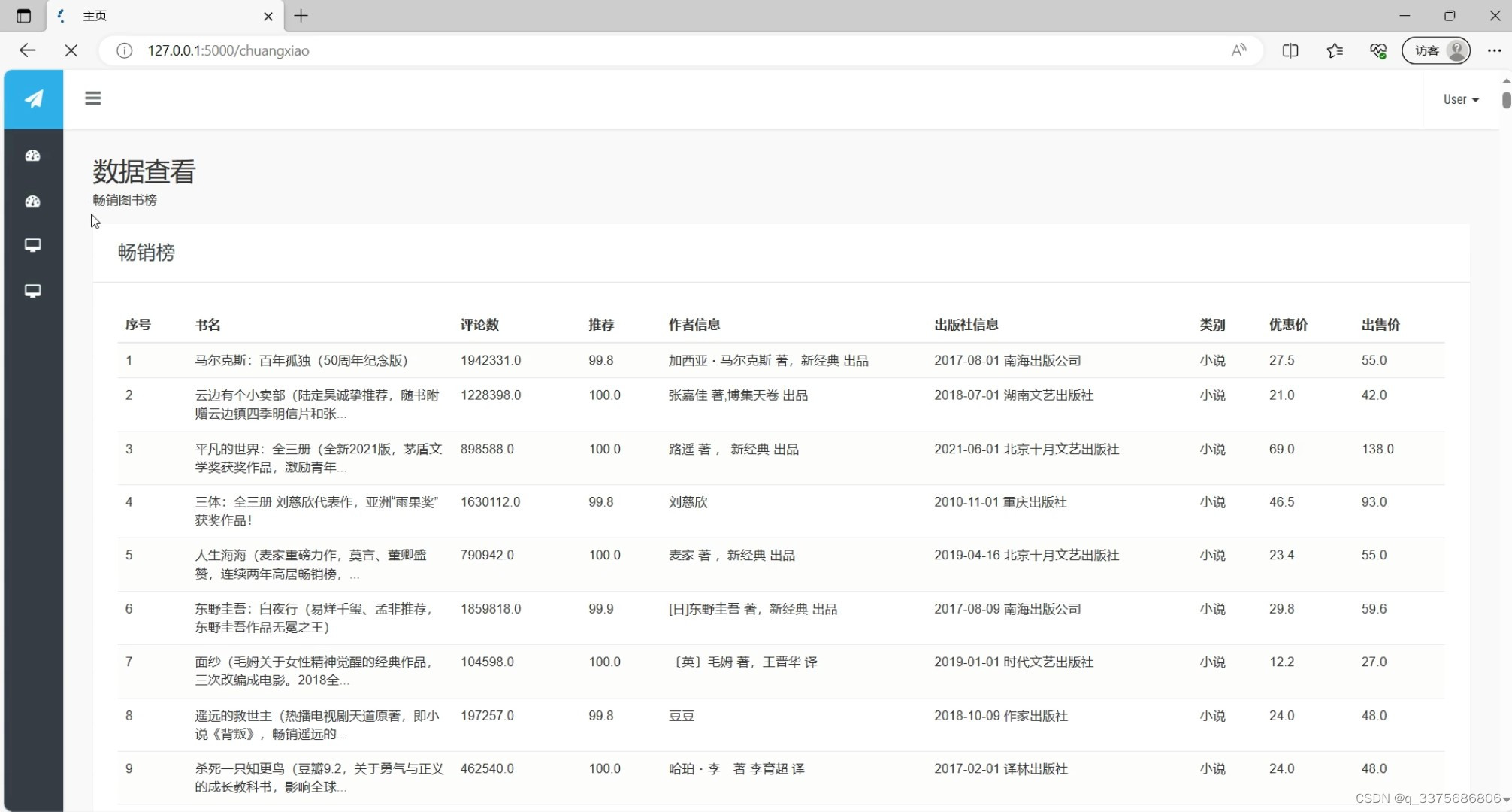
(5)注册登录界面
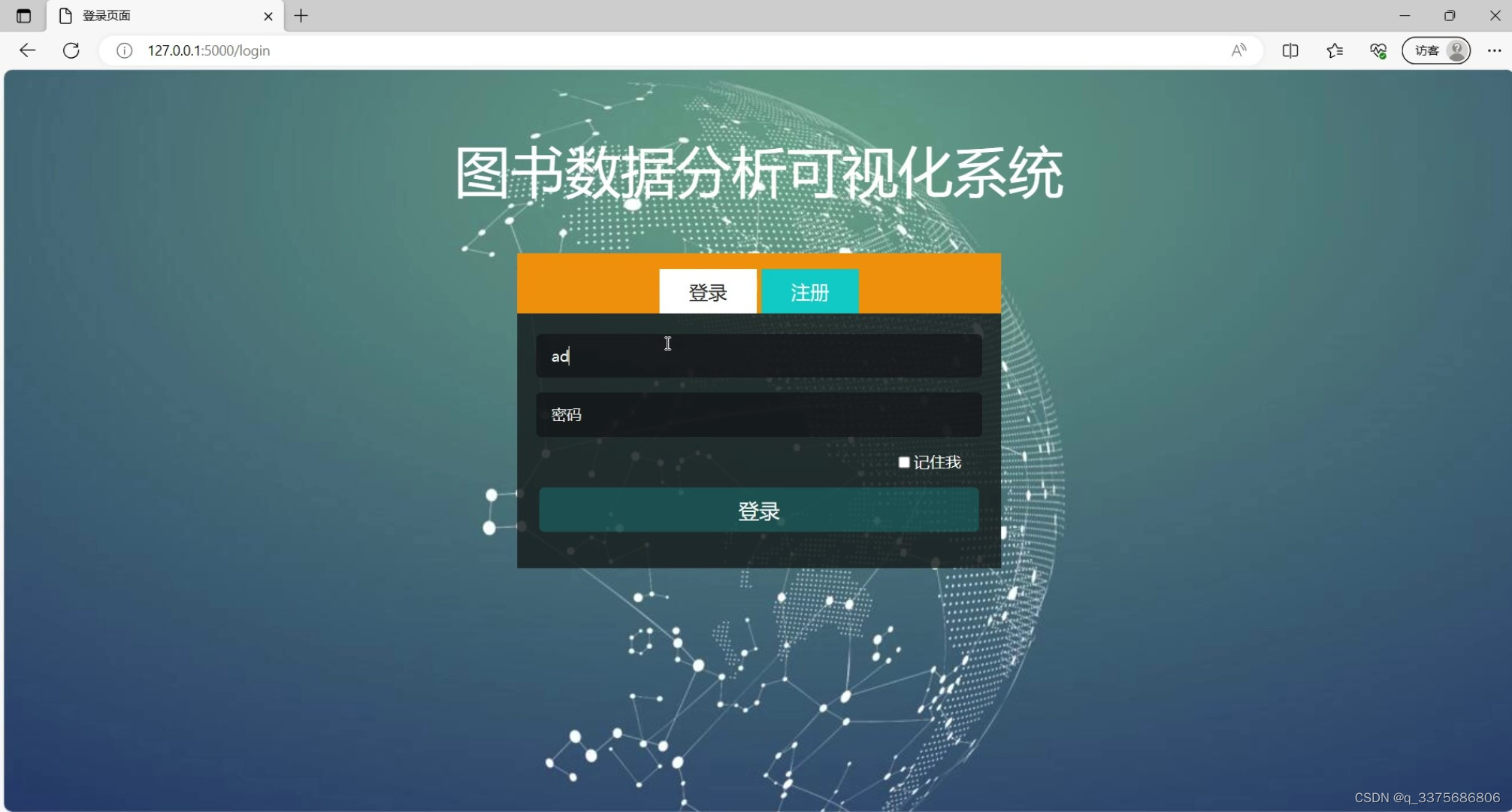
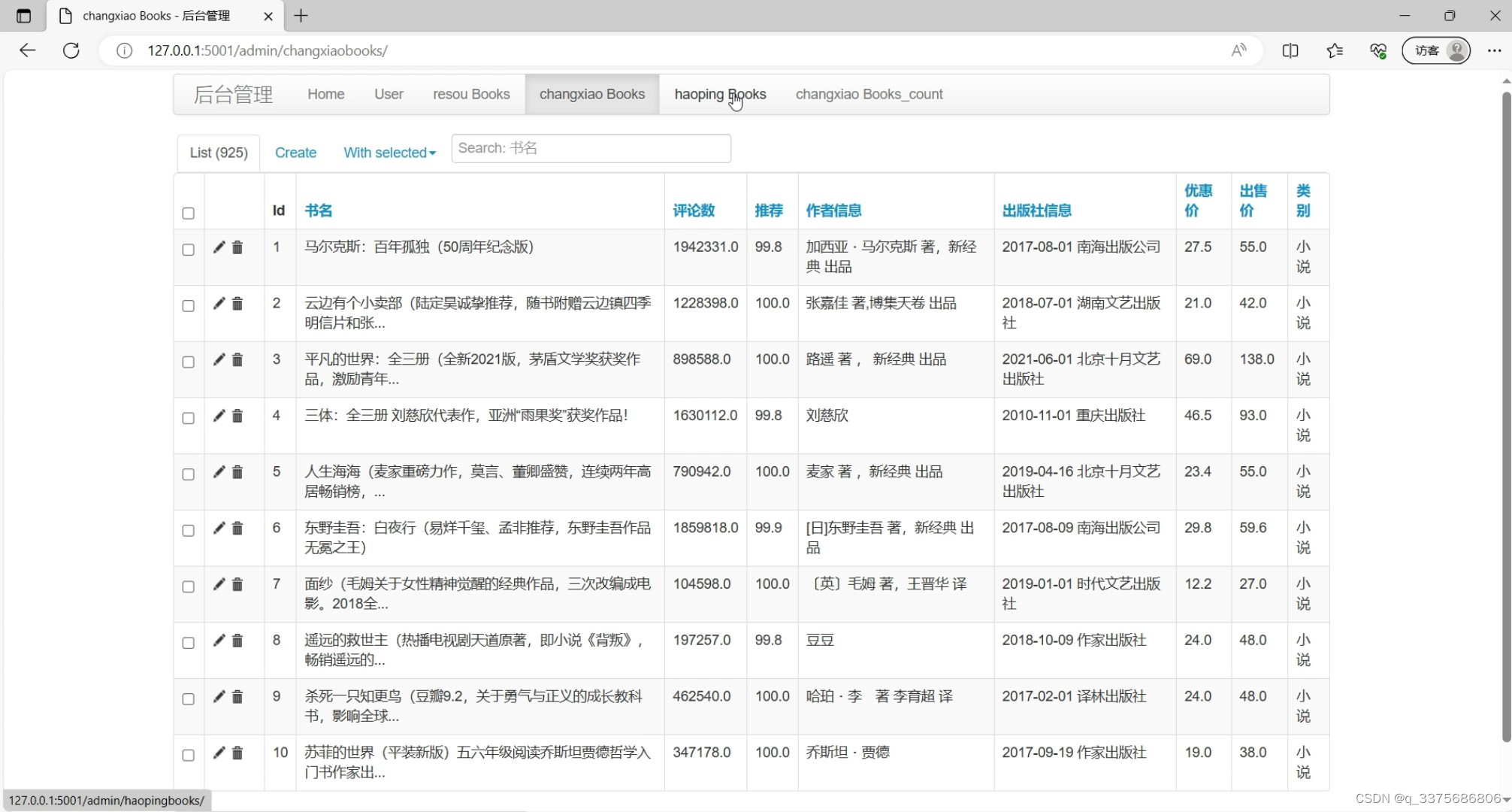
(6)后台数据管理
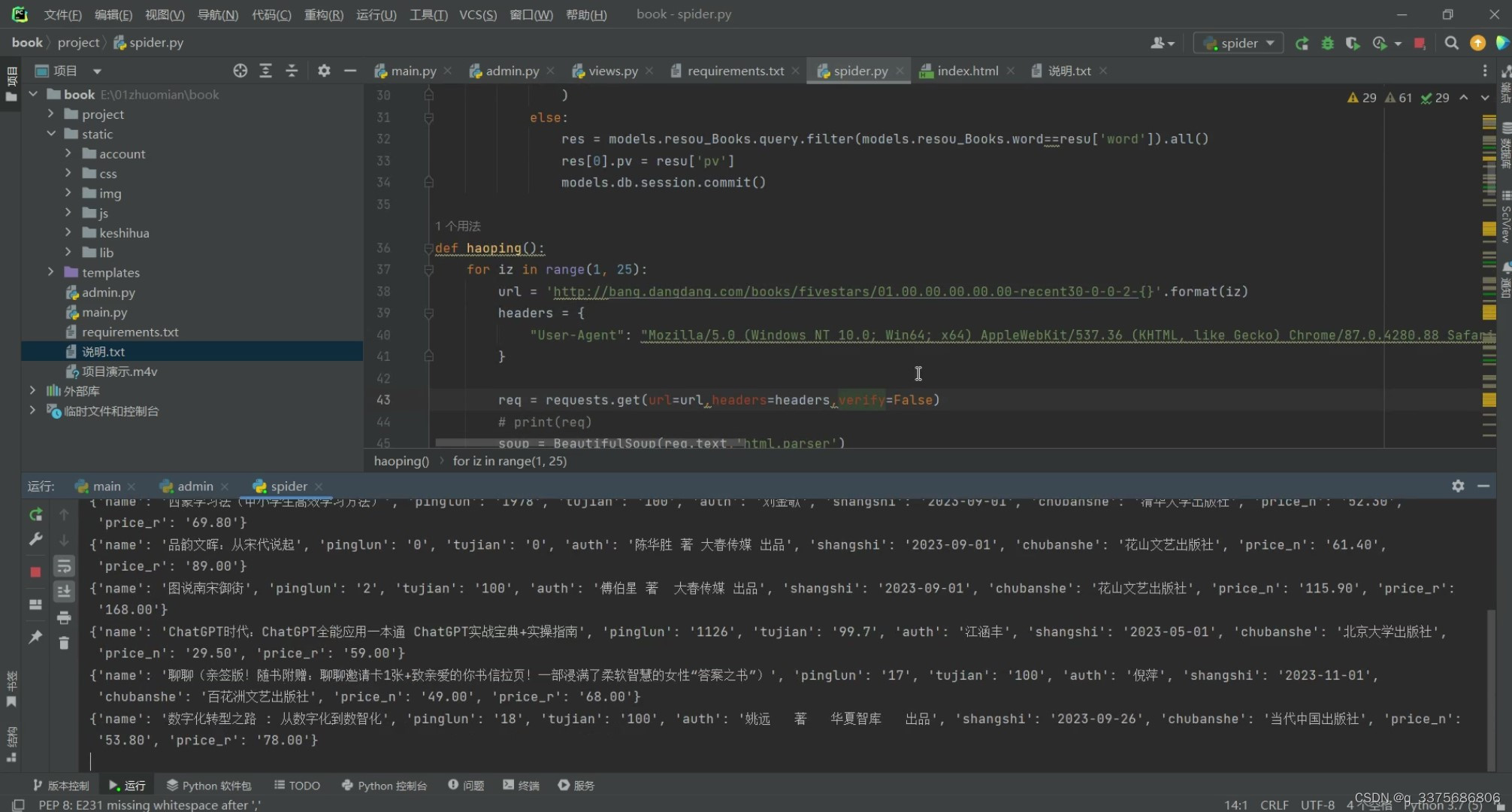
(7)数据爬虫
3、项目说明
该系统是一个基于Python语言和Flask框架开发的图书数据爬取分析可视化系统。系统通过网络爬虫技术从当当网上爬取图书数据,并通过Echarts可视化库将数据以图表的形式展示出来。用户可以通过系统界面输入关键词进行图书搜索,系统将根据关键词从当当网上爬取相关的图书信息。
系统主要包括以下功能:
- 图书搜索功能:用户可以在系统界面输入关键词进行图书搜索,系统将从当当网上爬取相关的图书信息并展示给用户。
- 图书数据分析功能:系统将从当当网上爬取的图书数据进行分析,如统计不同类型图书的数量、评分、价格等信息,并通过Echarts可视化库将分析结果以图表的形式展示出来,用户可以直观地了解图书数据的分布情况。
- 数据导出功能:用户可以将系统分析得到的图书数据导出为HTML文件,方便用户进行进一步的数据分析和处理。
该系统的开发使用了Python语言作为主要开发语言,Flask框架用于搭建系统的Web界面,网络爬虫技术用于从当当网上爬取图书数据,Echarts可视化库用于将数据以图表的形式展示出来,HTML用于实现系统的界面展示。系统具有图书搜索、数据分析和数据导出等功能,能够方便用户进行图书数据的分析和可视化展示。
4、核心代码
import requests
import ssl
from bs4 import BeautifulSoup
import json
import traceback
ssl._create_default_https_context = ssl._create_unverified_context
from project import models
import time
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def resou():
for i in range(1,6):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
h = requests.get(url=url,headers=headers,verify=False)
print(h)
for resu in h.json()['data']:
if not models.resou_Books.query.filter(models.resou_Books.word==resu['word']).all():
models.db.session.add(
models.resou_Books(
word=resu['word'],
pv=resu['pv']
)
)
else:
res = models.resou_Books.query.filter(models.resou_Books.word==resu['word']).all()
res[0].pv = resu['pv']
models.db.session.commit()
def haoping():
for iz in range(1, 25):
url = 'http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-2-{}'.format(iz)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
req = requests.get(url=url,headers=headers,verify=False)
# print(req)
soup = BeautifulSoup(req.text,'html.parser')
lis = soup.select('ul.bang_list > li')
for li in lis:
time.sleep(0.5)
try:
dicts = {}
dicts['name'] = li.select('div.name')[0].text.strip()
dicts['pinglun'] = str(li.select('div.star > a')[0].text).strip().replace('条评论', '')
dicts['tujian'] = li.select('div.star > span')[1].text.replace('%推荐','')
dicts['auth'] = li.select('div.publisher_info')[0].text.split('/')[0].strip()
dicts['shangshi'] = li.select('div.publisher_info')[0].text.split('/')[1].strip()
dicts['chubanshe'] = li.select('div.publisher_info')[0].text.split('/')[2].strip()
dicts['price_n'] = li.select('span.price_n')[0].text.replace('¥', '')
dicts['price_r'] = li.select('span.price_r')[0].text.replace('¥', '')
print(dicts)
if not models.haoping_Books.query.filter(models.haoping_Books.name == dicts['name']).all():
models.db.session.add(
models.haoping_Books(
name=dicts['name'],
pinglun=dicts['pinglun'],
tujian=dicts['tujian'],
auth=dicts['auth'],
shangshi=dicts['shangshi'],
chubanshe=dicts['chubanshe'],
price_n=dicts['price_n'],
price_r=dicts['price_r'],
)
)
models.db.session.commit()
except :
print(traceback.format_exc())
pass
if __name__ == '__main__':
resou()
haoping()
# tushuchangxiao()
# tushuchangxiao_count()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
文章来源:https://blog.csdn.net/q_3375686806/article/details/135561921
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Docker部署Mysql5.7x和Myslq8.x
- 产品经理之如何编写可行性分析(医疗HIS项目详细案例模板)
- #HarmonyOS:@ohos.promptAction (弹窗)---onProgressChange
- PTA 7-1 最大子列和问题
- 美易平台:美联储转向的真正原因?美国财政赤字飙升50%,单季财政赤字超5000亿美元!
- (2023版)斯坦福CS231n学习笔记:DL与CV教程 (14) | 强化学习(Robot Learning)
- pip 使用国内镜像源
- L1-010 比较大小(Java)
- 【WPF.NET开发】远程调查打印机的状态
- 计算机网络——网络模型的组织、看法以及标准化流程