显示文件前后内容 (来get小命令 tr 、 cut……)
一、 命令? ?tr -------基本功能转换
tr:对文件字符进行处理
格式
tr [选项]... SET1 [SET2]
SET 是一组字符串,一般都可按照字面含义理解
-d ?删除
-s ?压缩
-c 用字符串1中字符集的补集替换此字符集,要求字符集为ASCII。
tr? ?1? ?a? ?出现1转为a

tr 123? ?adc? ? ?只要出现123 就转换成adc

把文件里的小写转为大写

tr? ? ?abcd? ? 123
将abcd转为123,对应匹配不够时,默认转为后一个,也就是,c和d都转为3

? tr? ? -d删除

? tr? ? -s 压缩


随机生成密码
cat ?/dev/random ? | ?tr ? -dc ?[a-zA-Z0-9] ?| ?head -c ?12

二、seq

seq? -s+? ?10? ? ?中间加上加号

seq? -s+? 100|bc

seq? ?1? ?2? ?10? ? 打印奇数
seq? ?0? ?2? ? 10? ?打印偶数?

 三、cut??提取文本文件数据的指定列
三、cut??提取文本文件数据的指定列
格式? cut [选项]... [文件]...
-d? ?指明分隔符,默认tab
-f? ? 想要获取的字段
? ? ?#: 第#个字段,例如 3
?????#,#[,#]:离散的多个字段,例如 1,3,6
?????#-#:连续的多个字段, 例如 1-6
?????混合使用:1-3,7
-c ? 取字符

cut? ?-d:? ?-f1,3? /etc/passwd? ? ?以:为分隔符,切出第一列和第三列

cut? ?-d:? ?-f1-3? /etc/passwd? ? ?以:为分隔符,切出第一列到第三列

综合实验下哈: 提取/dev/sda1这一行的4




也可以这样哦?

综合实验下哈:提取文件名


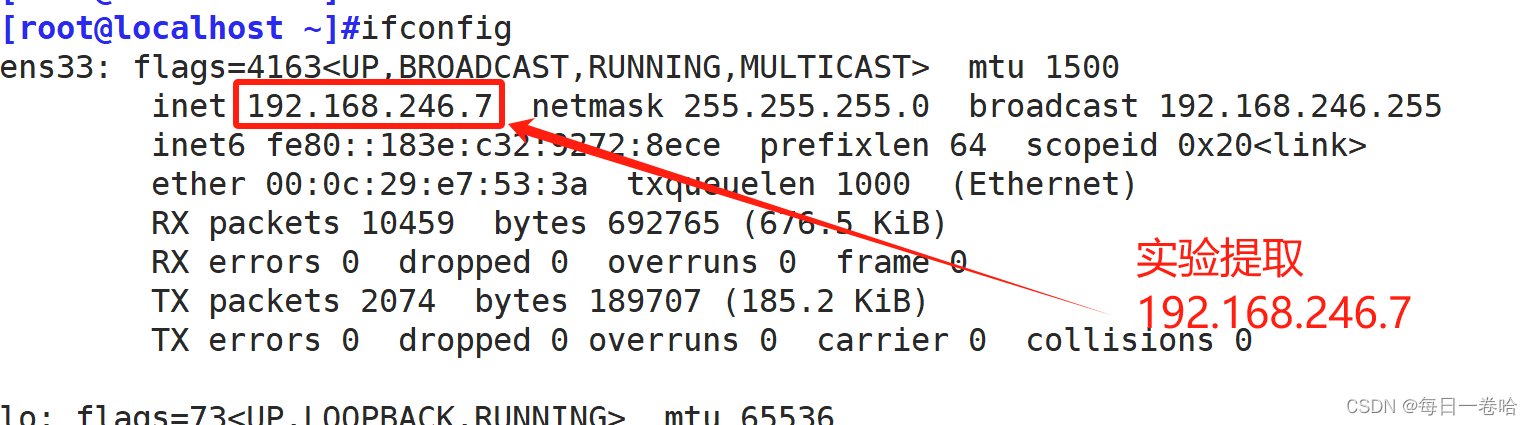
综合实验下哈:提取192.168.246.7

四、sort? ?排序
把整理过的文本显示在屏幕上,不改变原始文件
-r 执行反方向(由上至下)整理
-R 随机排序
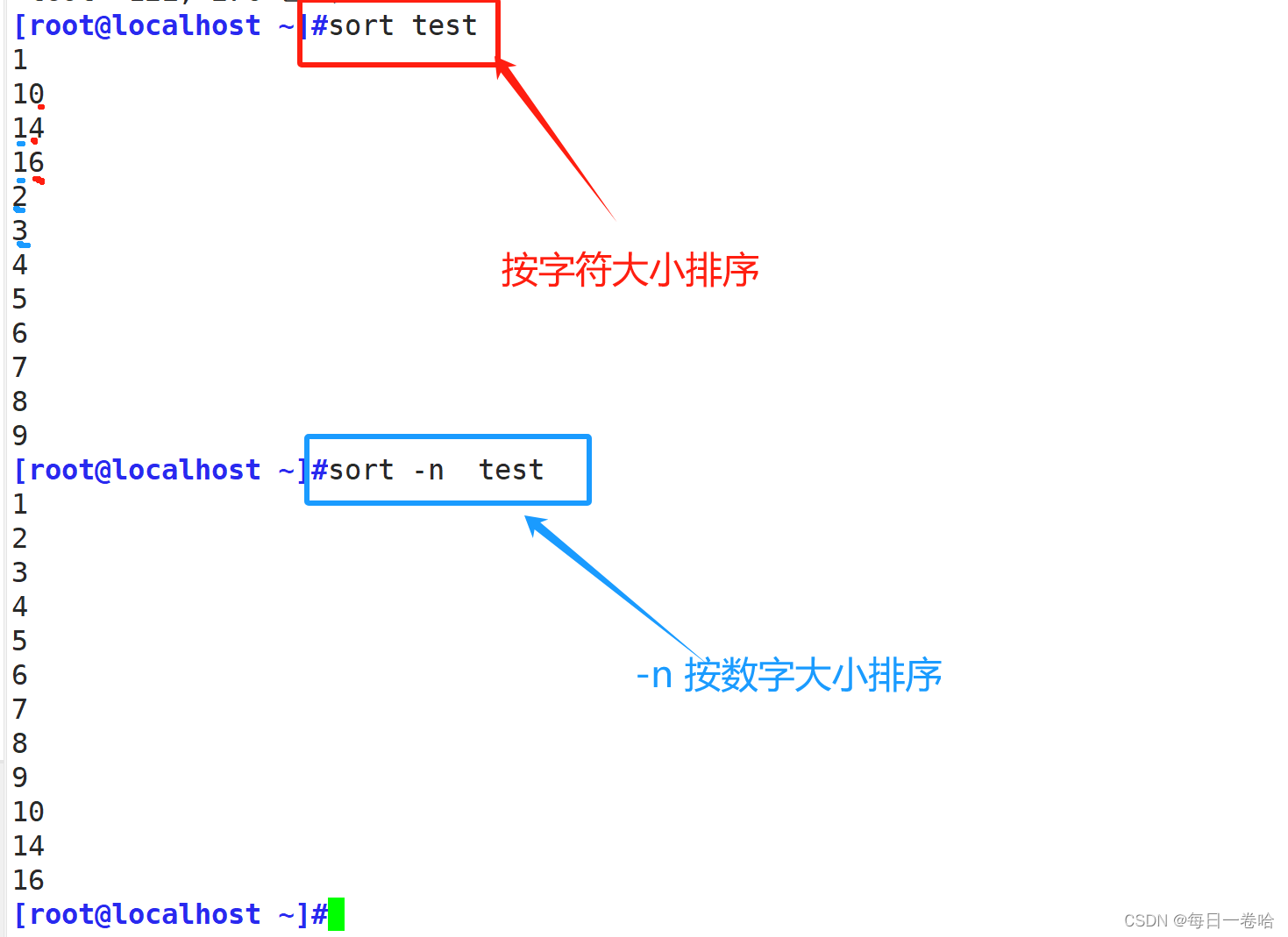
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G?
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique),合并重复项,即去重
-t 指定分隔符
-k 指定列
把整理过的文本显示在屏幕上,不改变原始文件



?sort? ?-n? 执行按数字大小整理


把access_log 直接拖到xhell里面
重点哦,别忘记哈

五、uniq??去重
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
首先编辑一个test

?uniq? ?-d? 仅显示重复过的行

uniq? -u? ?仅显示不曾重复的行

?uniq? -c???显示每行重复出现的次数

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!