DeciLM-7B:突破极限,高效率、高精准度的70亿参数AI模型
引言
在人工智能领域,语言模型的发展速度令人瞩目。Deci团队最近推出了一款具有革命性意义的语言模型——DeciLM-7B。这款模型在速度和精确度上都实现了显著的突破,以其70亿参数的规模,在语言模型的竞争中脱颖而出。
-
Huggingface模型下载: https://huggingface.co/Deci
-
AI快站模型免费加速下载: https://aifasthub.com/models/Deci
DeciLM-7B的核心优势
-
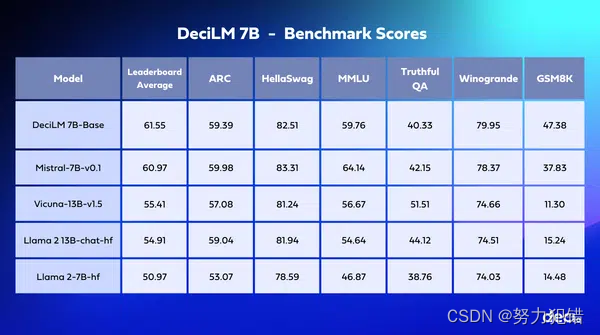
准确度: DeciLM-7B在Open LLM Leaderboard上的平均得分高达61.55分,超过了同等级别的竞争者,如Mistral 7B。这种准确性的提升使得DeciLM-7B在从客户服务机器人到复杂数据分析等各种应用中更加可靠和精确。
-
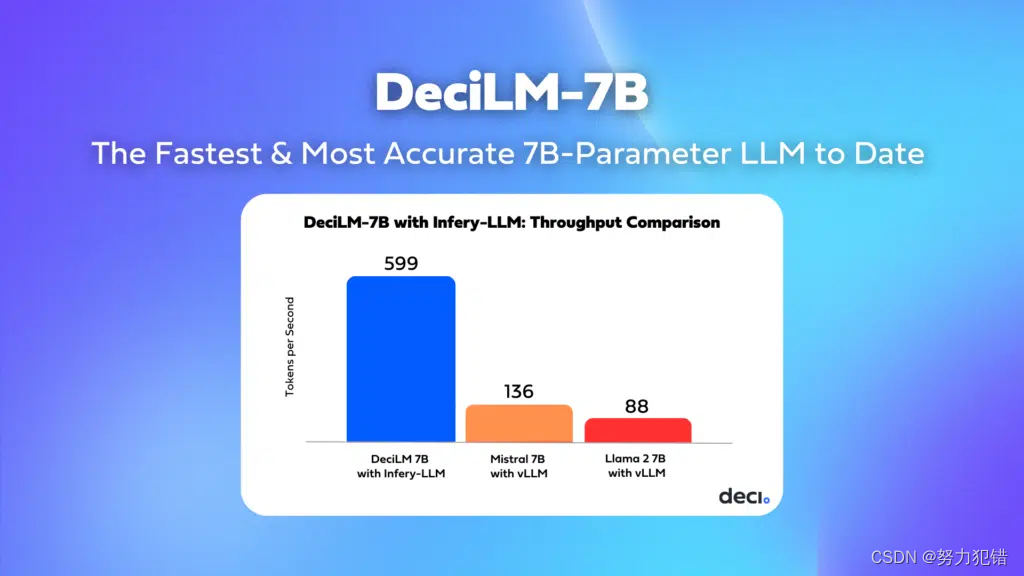
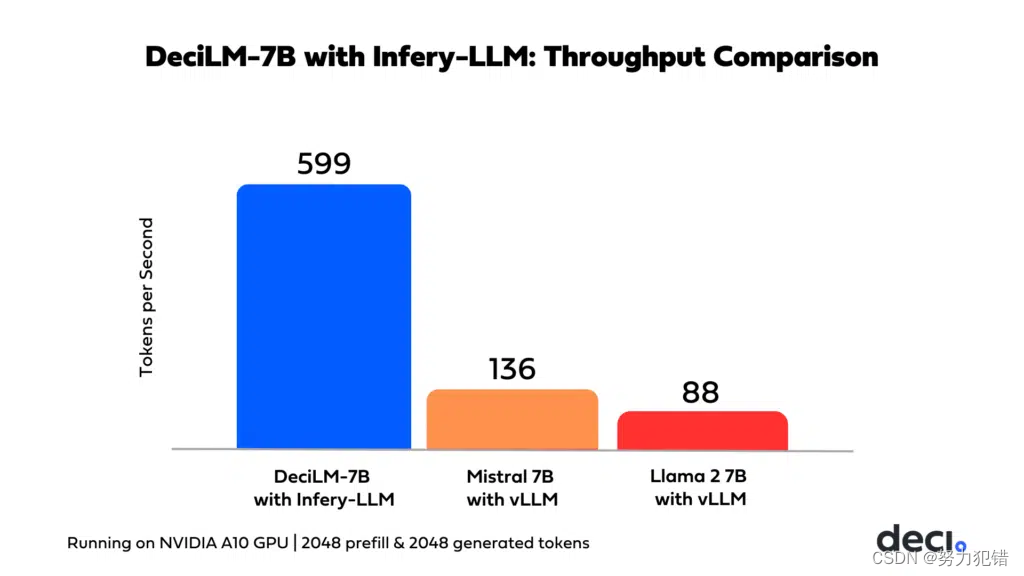
吞吐量性能: 在PyTorch基准测试中,DeciLM-7B展现了显著的性能优势,其吞吐量比Mistral 7B高出1.83倍,超过Llama 2 7B的2.39倍。

-
速度提升: 结合Deci的Infery-LLM推理SDK,DeciLM-7B的性能得到了进一步加速。这种强大的组合在吞吐量方面设定了新标准,速度比Mistral 7B快4.4倍。
-
创新架构: DeciLM-7B采用了变量群组查询关注(Variable Grouped Query Attention)技术,这是在准确度和速度之间达到最佳平衡的一大突破。
-
指令调优变种: DeciLM-7B采用了LoRA对SlimOrca数据集进行指令调优,生成的DeciLM-7B-instruct在Open LLM Leaderboard上的平均分数达到63.19分。
架构优势和技术创新
DeciLM-7B的卓越性能源于其战略性的实施变量群组查询关注(GQA)。传统的多查询关注(MQA)在减少内存使用和计算开销方面虽有优势,但有时会牺牲模型质量。GQA通过为每个群组提供独特的键值对,提供了更细致的注意力机制。DeciLM-7B通过在不同层中使用不同的GQA群组参数,实现了速度和准确性的最佳平衡。
此外,DeciLM-7B的架构是利用Deci的先进神经架构搜索(NAS)引擎AutoNAC开发的。AutoNAC通过更高效的计算方式自动化搜索过程,对于确定GQA群组参数在每个变压器层中的最佳配置至关重要。
成本效益和实际应用
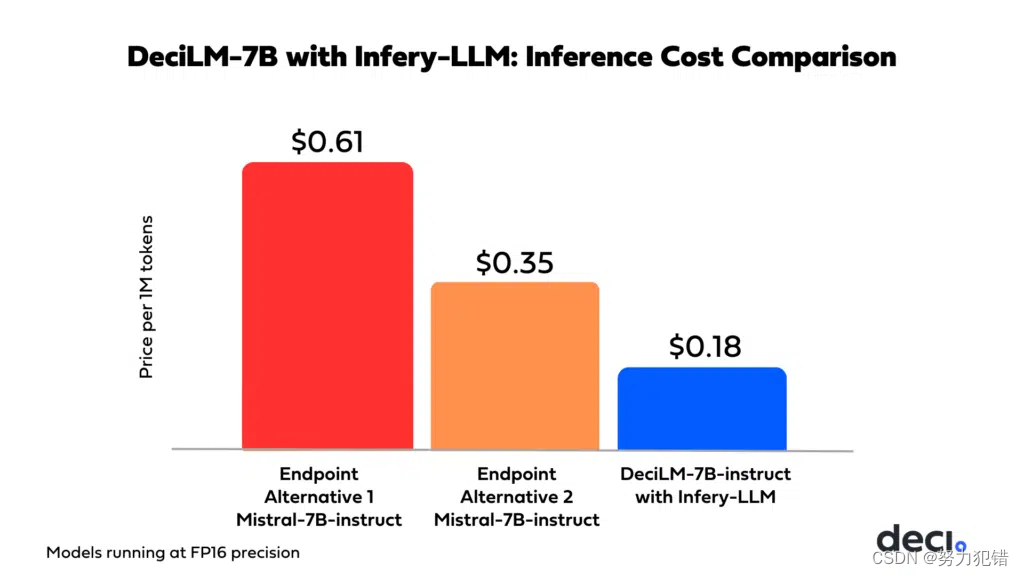
DeciLM-7B联合Infery-LLM不仅提升了模型能力,还大幅降低了与其他推理端点提供商相比的成本。这种经济效率使得DeciLM-7B和Infery-LLM成为企业构建、部署和扩展基于LLM的应用程序的理想选择,同时最小化计算成本。
DeciLM-7B和Infery-LLM的应用范围广泛,可以帮助各行各业革新操作方式,推动创新。在客户服务领域,这种组合可以支持高效理解并响应客户查询的复杂聊天机器人,提升用户体验。在医疗、法律、市场和金融等文本和研究密集型专业领域,DeciLM-7B和Infery-LLM的结合尤为有影响力,可执行文本总结、预测分析、文档分析、趋势预测和情感分析等任务。
开放源代码和未来展望
DeciLM-7B作为开源模型,采用Apache 2.0许可,可供商业使用。我们相信,DeciLM-7B的卓越性能,结合显著的成本节约和对开源原则的承诺,将在LLM基础应用程序的开发中带来重大进步。
模型下载
Huggingface模型下载
https://huggingface.co/Deci
AI快站模型免费加速下载
https://aifasthub.com/models/Deci
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 查看自己超算账号上剩余储存空间教程
- Linux安装Tomcat及配置
- Linux搭建NFS
- RDD算子——转换操作(Transformations )【map、flatMap、reduceByKey】
- 大学生如何当一个程序员
- 在CentOS中,有两种配置网络的方法,总有一种适合你
- pycharm通过ssh连接远程服务器的docker容器进行运行和调试代码
- spring-cloud-starter-openfeign的maven引入方式引发的故障,分析其原理
- AI量化策略 篇一:方向综述
- 【机器学习】调配师:咖啡的完美预测