数据结构之哈希——学习笔记
今天看网课学习了哈希的数据结构,写下这一篇博客记录自己的学习过程。
1.哈希简介:

?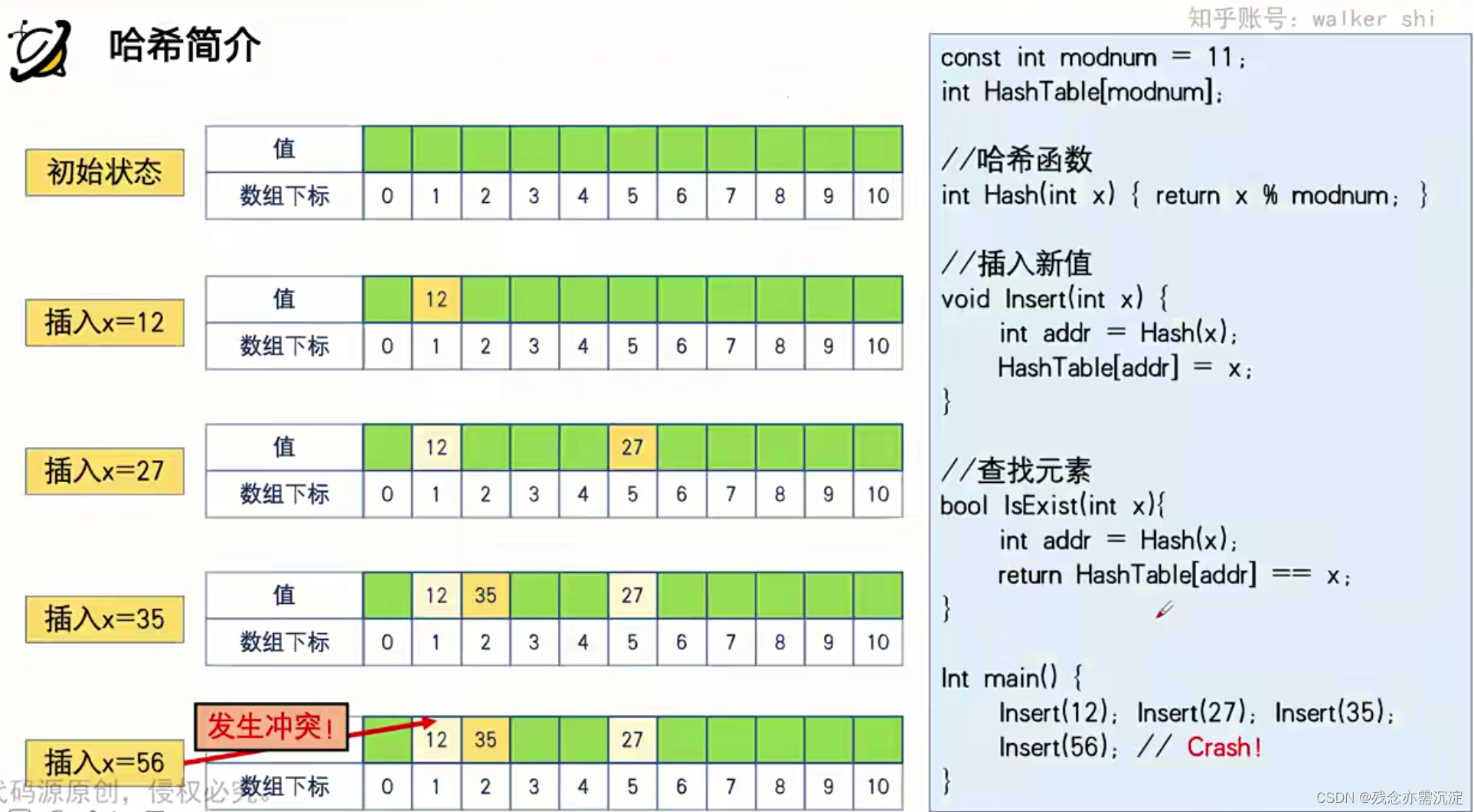
我们发现某些时候映射到小集合的时候会同时有多个值映射到一个下标里面,所以接下来是这种情况的解决方案1:?

?我们考虑当两个数字映射之后的结果是在同一个下标的时候,那么不妨可以将第二个映射到这个下标的数字往后移动到第一个空白的下标里面。
实际上上面这一种解决问题的方式存在较大的问题,当冲突之后后移的话会导致对应下标里面的值不再是本身应该映射到这个下标里面的值了。
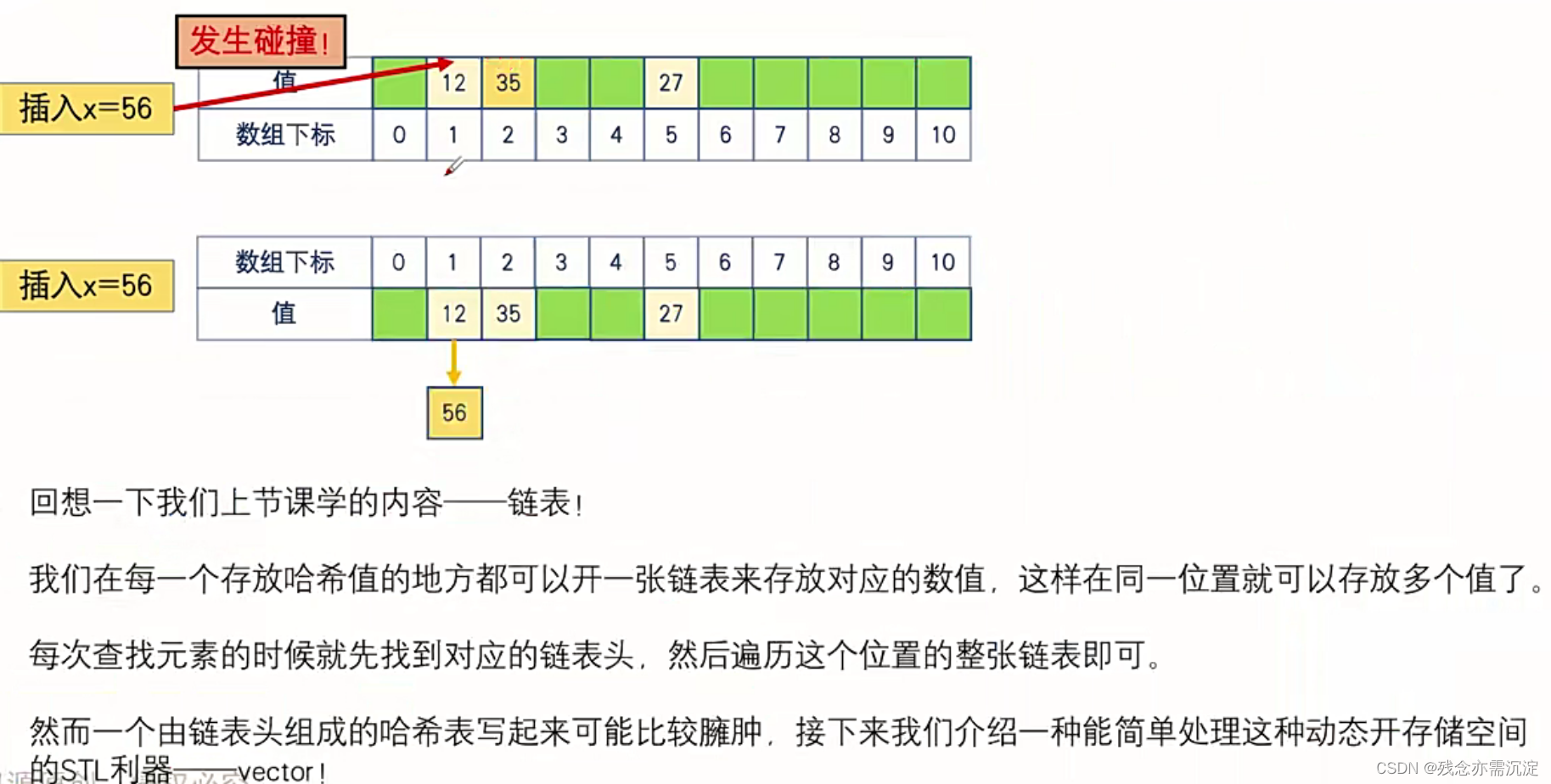
所以考虑到第一种值冲突解决问题在有些情况的不适用,那么接下来介绍第二种值冲突的解决方案:
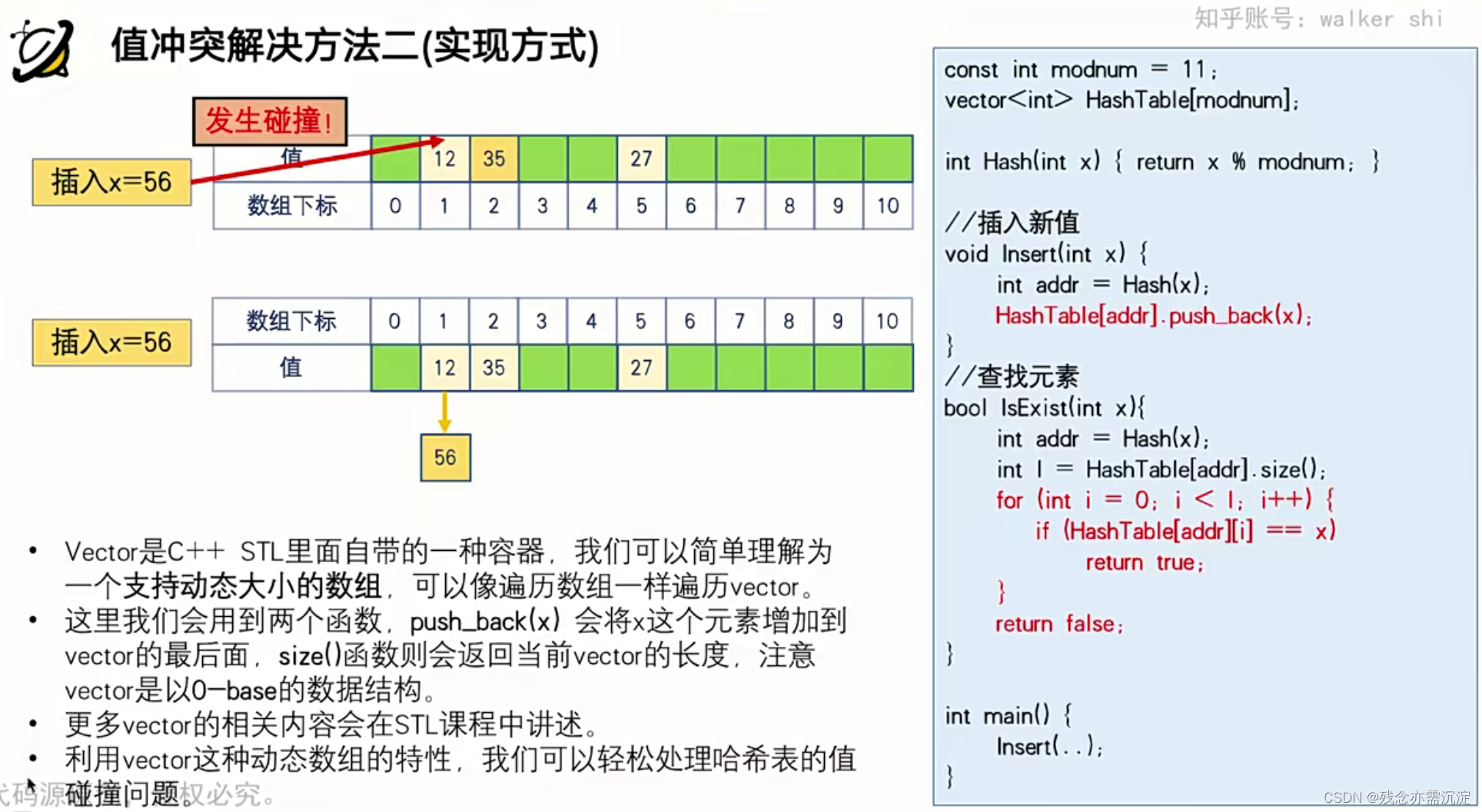
接下来详细介绍vector(可以理解为动态数组):?
这样的方法可以理解为开设了多个链表,每个下标都相当于是一条链表,实际上虽然这种方法已经解决了绝大多数的问题但是当遇见特殊的样例,也就是样例映射之后全部都在一个下标的时候,一样是存在问题的。
接下来看一下哈希函数的设计:
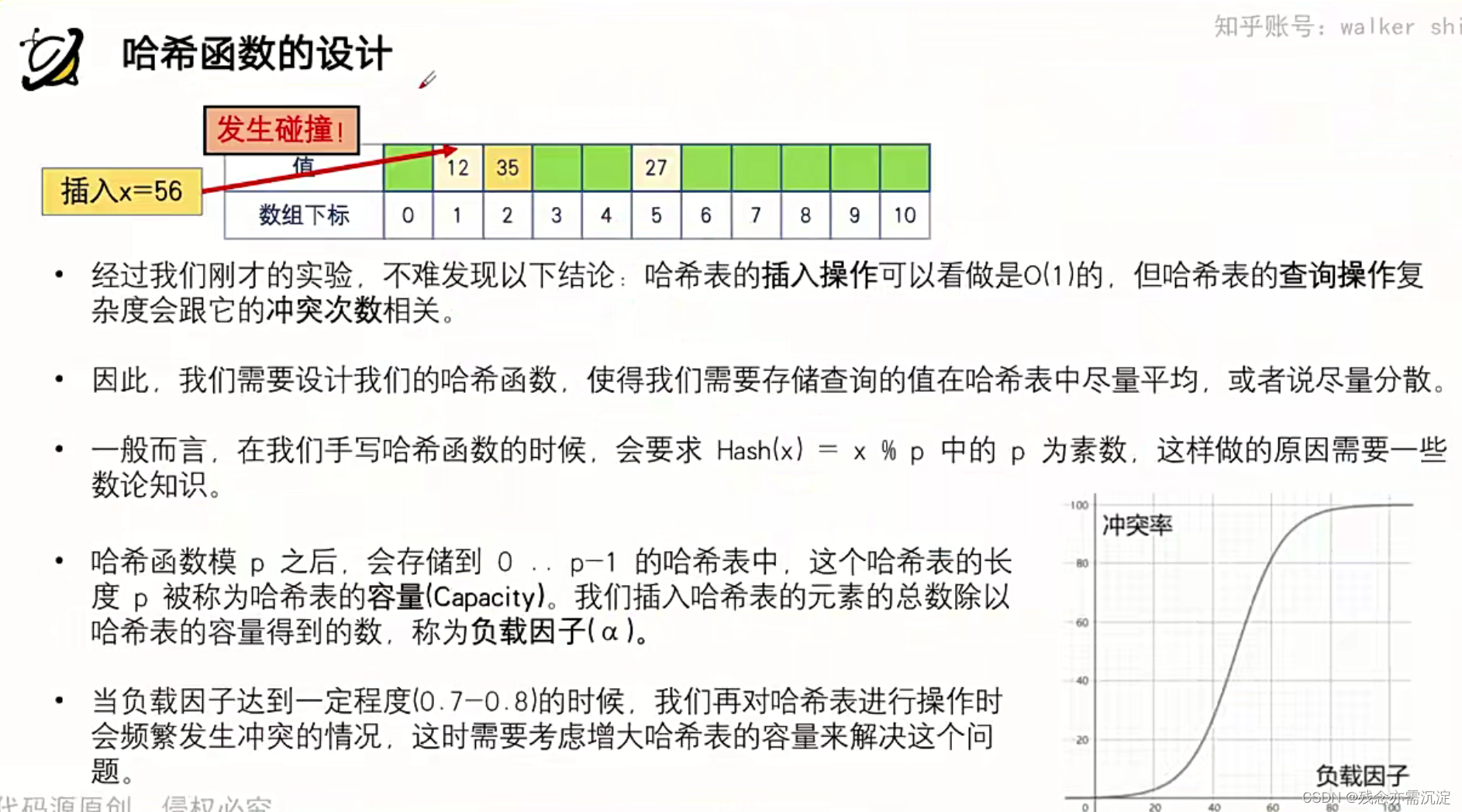
?接下来看一下字符串如何进行哈希操作:

另外请思考: ?
?
令base为11会导致值冲突加剧,另外发生值冲突我们考虑双哈希甚至三哈希等多次哈希操作来解决,也就是设置多个base以及p的值,这样的话只有当多组的base和p计算出来的值都相同的时候我们才会认为两个字符串相同。
 ?接下来看一下c++中自带的hash:
?接下来看一下c++中自带的hash:
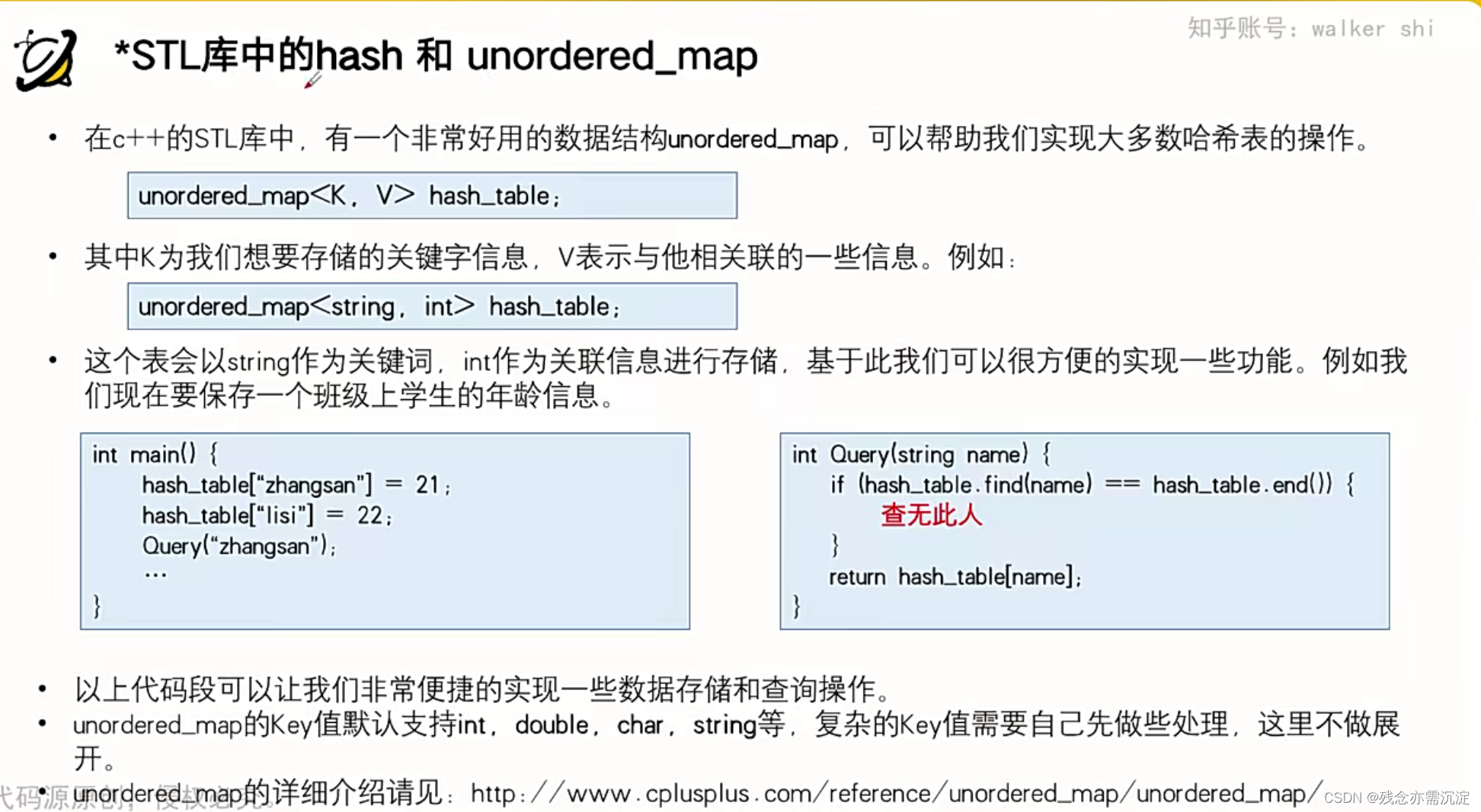
接下来来看一些例题:

?代码如下:
#include<bits/stdc++.h>
using namespace std;
int n,m;
const int P=9999971;//要模的素数
int a[200001],b[200001];
vector<int>c[P];
int main(){
cin>>n>>m;//存下两篇论文的长度
for(int i=0;i<P;i++)//将所有的链表数组清空
c[i].clear();
for(int i=1;i<=n;i++){
cin>>a[i];
c[a[i]%P].push_back(a[i]);//存下第一篇论文中所有的数字
}
int x=0;
for(int i=1;i<=m;i++){
cin>>b[i];
bool ok=false;//假设这个数字不是抄袭的
int v=b[i]%P;
int l=c[v].size();
//判断假设是否成立
for(int j=0;j<l && !ok;j++)
if(c[v][j]==b[i]) ok=true;
if(ok) ++x;//如果成立 抄袭的部分加一
}
//判断被标记的抄袭的论文部分是否大于了一半
if(2*x>=m) cout<<"Yes"<<endl;
else cout<<"No"<<endl;
return 0;
}
这里还有一种使用map的方法:
#include<bits/stdc++.h>
using namespace std;
int n,m;
const int P=9999973;
int a[200001],b[200001];
unordered_map<int,int>c;
int main(){
cin>>n>>m;
c.clear();
for(int i=1;i<=n;i++){
cin>>a[i];
c[a[i]]=1;
}
int x;
for(int i=1;i<=m;i++){
cin>>b[i];
if(c.find(b[i]) != c.end()) ++x;
}
if(x*2>=m) cout<<"Yes"<<endl;
else cout<<"No"<<endl;
return 0;
}接下来再看第二个题:

?很明显这里是使用map,这是我的代码:
#include<bits/stdc++.h>
using namespace std;
int n,m;
unordered_map<string,int>a;
unordered_map<string,int>b;
unordered_map<string,int>c;
int main(){
cin>>n>>m;
a.clear();
b.clear();
c.clear();
for(int i=1;i<=n;i++){
string s;
cin>>s;
int x,y,z;
cin>>x>>y>>z;
a[s]=x;
b[s]=y;
c[s]=z;
}
for(int i=1;i<=m;i++){
string s;
cin>>s;
if(a.find(s)==a.end()) cout<<"-1"<<' '<<"-1"<<" "<<"-1"<<endl;
else cout<<a[s]<<' '<<b[s]<<' '<<c[s];
}
return 0;
}但是会发现上面的代码使用了三个map来分别存身高年龄专业编码,实际上这三个都可以通过一个结构体来存储:
#include<bits/stdc++.h>
using namespace std;
int n,m;
struct Info{
int x,y,z;
};
unordered_map<string,Info>a;
int main(){
cin>>n>>m;
a.clear();
for(int i=1;i<=n;i++){
string s;
cin>>s;
Info temp;
cin>>temp.x>>temp.y>>temp.z;
a[s]=temp;
}
for(int i=1;i<=m;i++){
string s;
cin>>s;
if(a.find(s) != a.end()) cout<<a[s].x<<' '<<a[s].y<<' '<<a[s].z<<endl;
else cout<<"-1"<<' '<<"-1"<<' '<<"-1"<<endl;
}
return 0;
}ok,接下来看下一道题目:

#include<bits/stdc++.h>
using namespace std;
int n;
unordered_map<int,int>c;
int a[200001];
int main(){
scanf("%d",&n);
c.clear();
for(int i=1;i<=n;i++){
int x;
cin>>x;
++c[x];
}
int x=0,l=0;
for(auto temp : c){
if(temp.second>x){
x=temp.second;
l=0;
}
if(temp.second==x) a[++l]=temp.first;
}
sort(a+1,a+l+1);
for(int i=1;i<=l;i++)
cout<<a[i]<<' ';
return 0;
}?这道题目看似很简单实则还是有一定难度的。正常人思路肯定一开始都是利用数组来存储每个数字出现的次数然后最后遍历数组容量,更新出现次数最多的数字,如果遇上多个相同大的,那就利用一个数组和一个判断长度l的变量来进行不断更新和便于之后的输出。
接下来看第四题:
?代码如下:
#include<bits/stdc++.h>
using namespace std;
int n;
unordered_map<int,int>c;
int main(){
cin>>n;
c.clear();
for(int i=1;i<=n;i++){
int x;
cin>>x;
++c[x];
}
int x=0;
bool add=false;
for(auto temp : c){
if(temp.second & 1) add=true;
x+=temp.second/2*2;
}
if(add) ++x;
cout<<x<<endl;
return 0;
}最后一个题目了:

?代码如下:
#include<bits/stdc++.h>
using namespace std;
int n,m;
const int p=9999973,base=101;
int ha[200010],hb[200010],c[200010];
char a[200010],b[200010];
int main(){
scanf("%d%d",&n,&m);
scanf("%s%s",a+1,b+1);
c[0]=1;
for(int i=1;i<=200000;i++)
c[i]=c[i-1]*base%p;
for(int i=1;i<=n;i++)
ha[i]=(ha[i-1]*base+(a[i]-'a'))%p;
for(int i=1;i<=m;i++)
hb[i]=(hb[i-1]*base+(b[i]-'a'))%p;
int ans=0;
for(int i=1;i+m-1<=n;i++)
if((ha[i+m-1]-1LL*ha[i-1]*c[m]%p+p)%p==hb[m])
++ans;
printf("%d\n",ans);
return 0;
}以上是一个单哈希的写法,c数组代表了base的i次方的值,而ha和hb分别包含了长度为i子串的哈希值最后一个for循环进行遍历计算有b子串在a子串出现了多少次。然后输出答案,接下来介绍一个双哈希的写法:
#include<bits/stdc++.h>
using namespace std;
int n,m;
const int p=9999973,base=101;
const int p2=9999973,base2=137;
int ha[200010],hb[200010],c[200010],c2[200011],ha2[200011],hb2[200011];
char a[200010],b[200010];
int main(){
scanf("%d%d",&n,&m);
scanf("%s%s",a+1,b+1);
c[0]=1;c2[0]=1;
for(int i=1;i<=200000;i++){
c[i]=c[i-1]*base%p;
c2[i]=c2[i-1]*base2%p2;
}
for(int i=1;i<=n;i++){
ha[i]=(ha[i-1]*base+(a[i]-'a'))%p;
ha2[i]=(ha2[i-1]*base2+(a[i]-'a'))%p2;
}
for(int i=1;i<=m;i++){
hb[i]=(hb[i-1]*base+(b[i]-'a'))%p;
hb2[i]=(hb2[i-1]*base2+(b[i]-'a'))%p2;
}
int ans=0;
for(int i=1;i+m-1<=n;i++)
if((ha[i+m-1]-1LL*ha[i-1]*c[m]%p+p)%p==hb[m] && (ha2[i+m-1]-1LL*ha2[i-1]*c2[m]%p2+p2)%p2==hb2[m])
++ans;
printf("%d\n",ans);
return 0;
}希望今天的学习记录笔记同样对读者有所帮助。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- XDOJ175.窗口模拟
- 爬虫之牛刀小试(二):爬古诗文网的数据
- springboot集成elasticsearch8.X(8.11) 最新版的Java API Client 接口
- 新能源汽车的三电指的是什么,作用有什么区别。
- 咖啡+茶更续命!川大华西最新:每天饮用3杯茶,抗衰效果最好!同饮咖啡死亡风险下降22%
- C语言实现:判断回文数
- 什么是非电离辐射与电离辐射?
- 分布式架构理论:从头梳理分布式架构的重难点
- class_8:函数重载和运算符重载
- [USACO 1.1.3]黑色星期五