线程的面试八股
?
Callable接口
Callable是一个interface,相当于给线程封装了一个返回值,方便程序猿借助多线程的方式计算结果.
创建一个匿名内部类, 实现 Callable 接口. Callable 带有泛型参数. 泛型参数表示返回值的类型.
重写 Callable 的 call 方法, 完成累加的过程. 直接通过返回值返回计算结果.
把 callable 实例使用 FutureTask 包装一下.
创建线程, 线程的构造方法传入 FutureTask . 此时新线程就会执行 FutureTask 内部的 Callable 的 call 方法, 完成计算. 计算结果就放到了 FutureTask 对象中.
代码示例: 使用 Callable 版本,创建线程计算 1 + 2 + 3 + … + 1000,
??????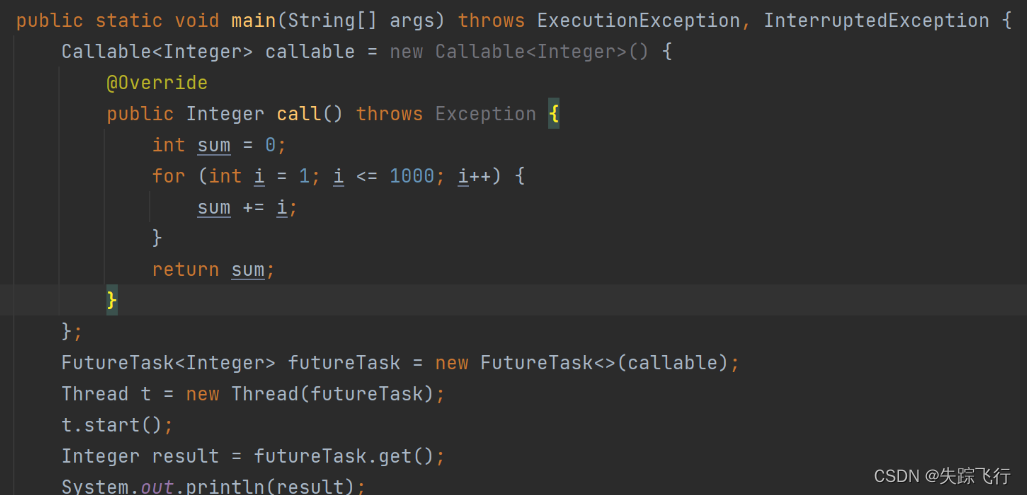
在上面代码中,get()方法会抛出异常.
理解Callable
- Callable 和 Runnable 相对, 都是描述一个 “任务”. Callable 描述的是带有返回值的任务, Runnable描述的是不带返回值的任务.
- Callable 通常需要搭配 FutureTask 来使用. FutureTask 用来保存Callable 的返回结果. 因为Callable 往往是在另一个线程中执行的, 啥时候执行完并不确定.
- FutureTask就可以负责这个等待结果出来的工作.
ReentrantLock类
可重入互斥锁. 和 synchronized 定位类似, 都是用来实现互斥效果, 保证线程安全.
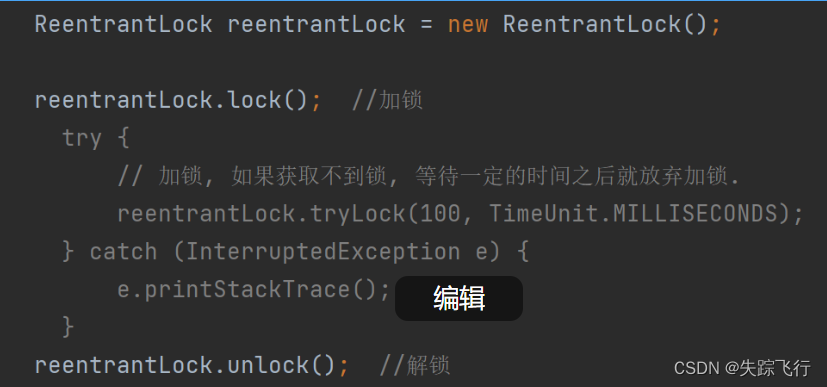
ReentrantLock的用法
????
ReentrantLock和Synchronized的区别
Synchronized是非公平锁,ReentrantLock默认是非公平锁,但可以通过一个构造方法传入true开启公平锁模式
Synchronized不需要手动释放锁,而ReentrantLock需要手动释放锁.
Synchronized提供的加锁操作就是 死等.只要获取不到锁,就会一直阻塞等待.而ReentrantLock提供了更灵活的等待方式.
ReentrantLock提供了更强大,更方便的的等待通知机制.
Synchronized搭配的是wait notify,notify的时候是随机唤醒一个等待线程,而ReentrantLock搭配的是Condition类,进行唤醒的时候可以唤醒指定线程.ReentrantLock t通常搭配 try catch 使用.


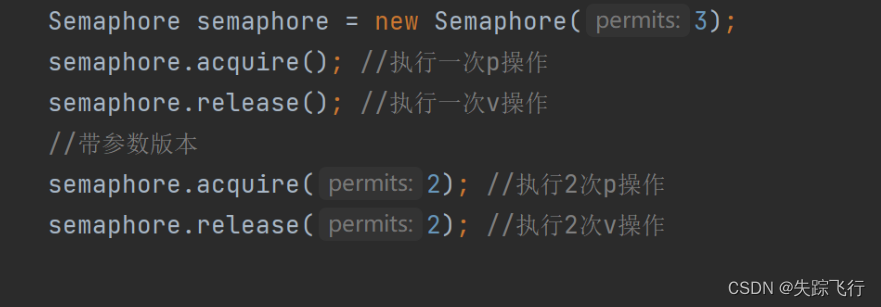
信号量 Semaphore
信号量, 用来表示 “可用资源的个数”. 本质上就是一个计数器.
理解信号量
可以把信号量想象成是停车场的展示牌: 当前有车位 100 个. 表示有 100 个可用资源.
P操作: 当有车开进去的时候, 就相当于申请一个可用资源, 可用车位就 -1 (这个称为信号量的 P 操作)
V操作: 作当有车开出来的时候, 就相当于释放一个可用资源, 可用车位就 +1 (这个称为信号量的 V 操作)
释放资源: 如果计数器的值已经为 0 了, 还尝试申请资源, 就会阻塞等待, 直到有其他线程释放资源.
Semaphore 的 PV 操作中的加减计数器操作都是原子的, 可以在多线程环境下直接使用.
CountDownLatch
CountDownLatch的主要任务是等待N个任务执行结束
- 构造CountDownLatch实例,初始化10代表有10个任务要完成.
???????
- 每执行完一个任务,都会调用 count.countDown()方法,每调用一次, CountDownLatch内部的计数器就会减1.
- 当主线程中使用 latch.await(); 阻塞等待所有任务执行完毕. 相当于计数器为 0 了.

多线程使用哈希表
在之前数据结构学习了哈希表,其中HashMap是线程不安全的,HashTable是线程安全的,
而这里主要讲的是ConcurrentHashMap,是一种更优化的线程安全哈希表.
???????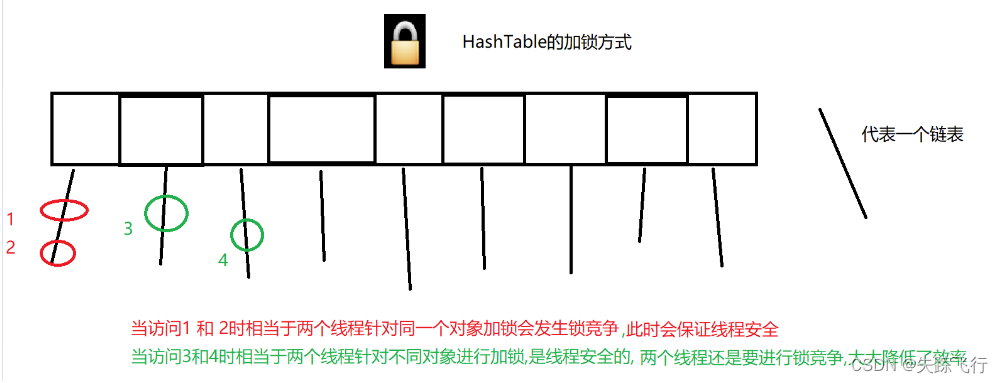
Synchronized加锁是多个线程针对同一个对象加锁,就会产生锁竞争,一个HashTable只有一把锁,此时两个线程在访问哈希表中的任意元素的时候都会发生锁竞争.
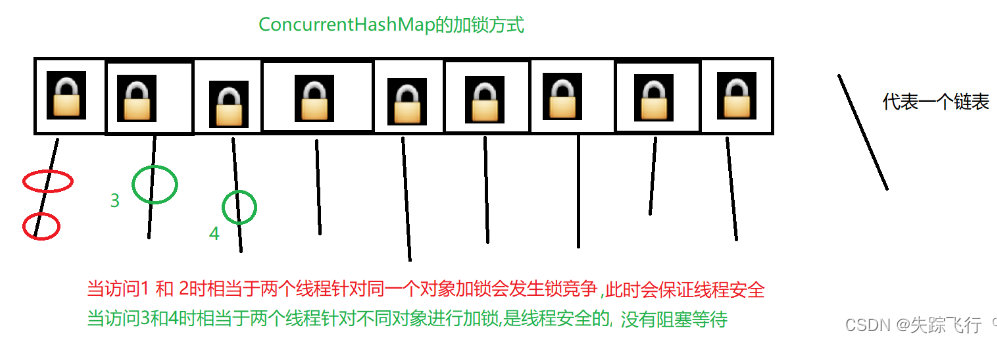
ConcurrentHashMap任然是用synchronized进行加锁,但不是整个锁对象,而是链表的头节点作为所对象,大大降低了锁冲突的概率
ConcurrentHashMap针对读操作不加锁,但使用volatile保证从内存读取元素时原子的,而只针对写操作进行加锁.
ConcurrentHashMap内部充分利用了CAS,进一步削减加锁操作的数目.
针对扩容采取了化整为零的方式.
- HashTable/HashMap扩容:创建一个更大的数组,把旧的数组上的链表上的每个元素都搬入到新的数组,相当于删除原来数组在重新插入到新的数组上.这个扩容会在某次put时进行出发,当数据太多,就会导致这种扩容会比较耗时
- ConcurrentHashMap中,扩容的方式是每次搬运一小部分元素,创建新的数组,旧的数组保留,每次put操作,都忘新数组上添加,同时进行一部分搬运,每次get的时候,旧的数组和新的数组都查询,每次remove只要找到元素删除即可.经过一定时间,所有的元素都搬运完了,最终在释放旧数组.
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!