实例分割模型Mask2Former解析
Masked2Former是在mask rcnn基础上改进的一个实例分割模型,参考了一些经典模型的思想,如DETR,实验表明效果很好。

论文:《Masked-attention Mask Transformer for Universal Image Segmentation》
https://arxiv.org/abs/2112.01527
代码地址:https://github.com/facebookresearch/Mask2Former
1.摘要
图像分割对具有不同语义的像素进行分组,例如,类别或实例隶属关系。每种语义选择都定义了一个任务。虽然每个任务只是语义不同,但目前的研究重点是为每个任务设计专门的体系结构。我们提出了maskedatattention Mask Transformer (Mask2Former),这是一种能够处理任何图像分割任务(全景、实例或语义)的新架构。它的关键组成部分包括屏蔽注意,它通过在预测的屏蔽区域内约束交叉注意来提取局部特征。
除了将研究工作量减少至少三倍之外,它在四个流行数据集上的性能明显优于最佳的专业架构。最值得注意的是,Mask2Former为全光分割(COCO上57.8 PQ),实例分割(COCO上50.1 AP)和语义分割(ADE20K上57.7 mIoU)设置了新的技术水平。
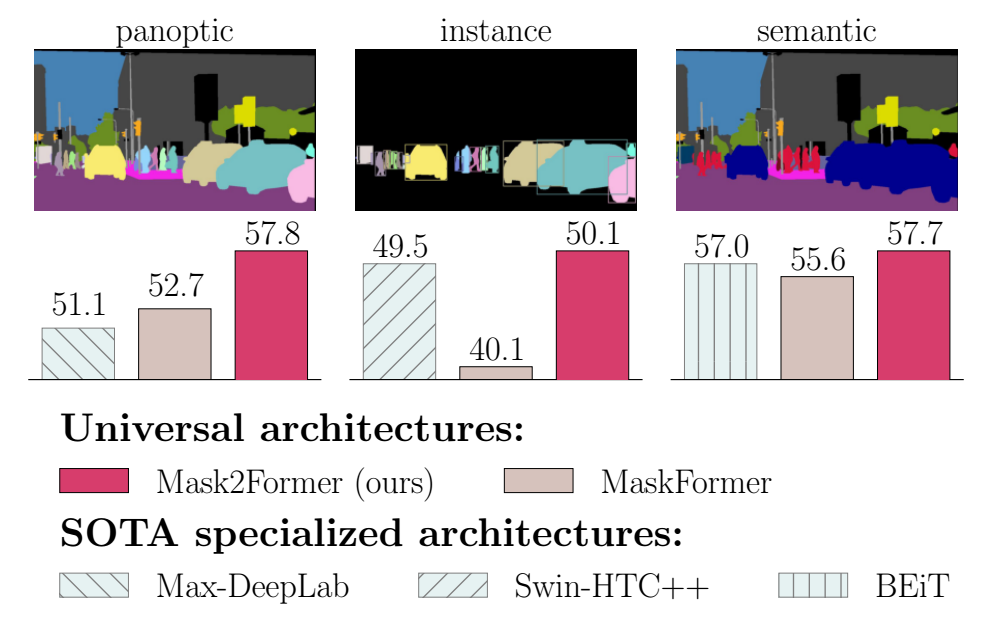
2.模型创新点
主要改进:
1.首先在Transformer解码器中使用屏蔽注意力(Masked attention),与传统的Transformer解码器中使用的交叉注意力相比,可以更快收敛并提高性能。
2.使用多尺度分辨率特征,帮助模型分割小物体/区域
3.提出了更换自注意力和交叉注意力的顺序、使查询特征可以学习、去除dropout等优化改进,所有这些可以不增加额外计算的同时提高性能。
3.模型结构
模型主要包括三个结构:主干特征提取器、像素解码器以及变压器解码器。
3.1 初步的掩码分类
收到DETR的启发,图像中的每个片段都可以作为C维特征向量,并且可以通过Transformer解码器处理,并使用一组预测目标进行训练。关于这种元架构更多的应该参考MaskFormer。
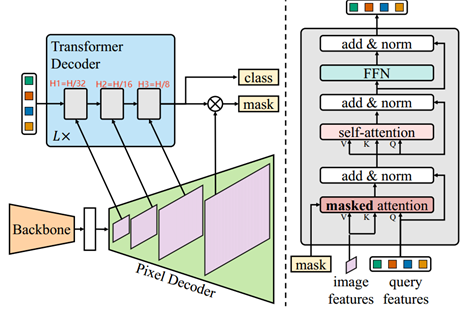
3.2 屏蔽注意力的Transformer解码器
3.2.1 Masked Attention
上下文特征已被证明对于图像分割很重要。然而,最近的研究表明,基于 Transformer 的模型收敛缓慢是由于交叉注意力层中的全局上下文造成的,因为交叉注意力需要许多训练周期才能学习关注局部对象区域。我们假设局部特征足以更新查询特征,并且可以通过自注意力收集上下文信息。
为此,我们提出了屏蔽注意力,这是交叉注意力的一种变体,仅参与每个查询的预测掩模的前景区域。
原始的交叉注意力的计算:
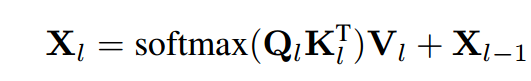
Masked attention的计算方式:
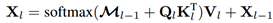
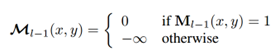
M_(l-1)是先前第(l-1)个transformer解码器层的经过调整大小的掩码预测的二值化输出,它被调整到与k_l相同的分辨率,M_0是从X_0得到的二进制掩码预测,即再查询特征馈送到Transformer解码器之前。
3.2.3 优化改进
标准 Transformer 解码器层 由三个模块组成,按以下顺序处理查询特征:自注意力模块、交叉注意力模块和前馈网络(FFN)。此外,查询特征(X0)在输入 Transformer 解码器之前被初始化为零,并与可学习的位置嵌入相关联。此外,dropout 应用于残差连接和注意力图。
为了优化 Transformer 解码器设计,我们做了以下三点改进。首先,我们切换自注意力和交叉注意力(我们新的“屏蔽注意力”)的顺序,以使计算更有效:第一个自注意力层的查询特征是与图像无关的,并且没有来自图像的信号,因此应用自注意力不太可能丰富信息。其次,我们使查询特征(X0)也可学习(我们仍然保留可学习的查询位置嵌入),并且可学习的查询特征在用于 Transformer 解码器中预测掩码(M0)之前直接受到监督。我们发现这些可学习的查询特征的功能类似于区域提议网络,并且能够生成掩模提议。最后,我们发现 dropout 是不必要的,而且通常会降低性能。因此,我们完全消除了解码器中的丢失。
3.3提高训练效率
在预测与其匹配的真实情况之间的最终损失中,我们使用重要性采样 对不同的预测和真实情况对的不同 K 点集进行采样。我们设置 K = 12544,即 112 ? 112 点。这种新的训练策略有效地将训练内存减少了 3x,从每张图像 18GB 减少到 6GB,使计算资源有限的用户更容易使用 Mask2Former。
5.结论
我们提出了用于通用图像分割的 Mask2Former。 Mask2Former 基于简单的元框架 [14] 和新的 Transformer 解码器,使用所提出的屏蔽注意力,在四个流行数据集的所有三个主要图像分割任务(全景、实例和语义)中获得了最佳结果,甚至超越了设计的最佳专业模型每个基准,同时保持易于训练。与为每个任务设计专用模型相比,Mask2Former 可以节省 3 倍的研究工作量,并且计算资源有限的用户也可以使用它。
我们希望引起人们对通用模型设计的兴趣
中间实验参数配置、实验结果和模块深度解析,有时间再来填坑!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第80讲:GTID全局事务标识符的基本概念以及在Binlog中应用GTID
- 微软好听的tts语音包下载,粤语,韩语,日语
- 细说JavaScript内置对象(JavaScript内置对象详解)
- AI产品经理-借力
- 利用Type类来获得字段名称(Unity C#中的反射)
- Iptables深度解析:四表五链与动作参数
- 通过 C++/WinRT 将值装箱到 IInspectable 和对其取消装箱
- BFS与队列以及DFS与BFS的区别
- 【长文阅读】MAMBA作者博士论文<MODELING SEQUENCES WITH STRUCTURED STATE SPACES>-Chapter1
- 最新版本Vue3的学习笔记-第四章