基于深度学习的面向工业场景的异常检测(一)
发布时间:2024年01月23日
简介
在工业场景中,正常样本往往是大量的,而且相对容易获取,比如符合质量要求的产品或零件。而缺陷数据通常较少,因为缺陷会导致产品被剔除或需要返工修复,从而增加生产成本和时间成本。此外,不同类型的缺陷样本也可能具有较强的特异性,涉及到领域专业知识和经验的积累,并且需要人工手动标注。
在这种情况下,缺乏缺陷样本会导致深度学习模型无法对缺陷进行准确区分,存在过拟合的风险。用检测行业的话来说就是容易“漏检”,在工业视觉检测中,漏检问题严重影响着企业的生产效率和质量保障。
1. 基于GAN合成缺陷样本
- 真实样本:
这些是PCB板上一些插座的插孔,这是我面对的场景的缺陷数据

- 用DCGAN合成的假数据:
训练50轮:

训练100轮:

上面的合成效果作为初学者可能会很激动,但是作为从业者来说就有点难过了,很明显合成的和真实的差别很大,从判别器99%+的准确率已经很明显的说明问题了。但是即使是效果不太好,至少证明走GAN合成缺陷的路似乎还是可行的。下面就是如何提高生成器的生成效果了。上面的效果用的是https://blog.csdn.net/qq_40622955/article/details/129914959这里面的生成器,比较小。
当减少训练样本的种类而只训练其中1-2种的时候,32张图片,训练1000轮效果稍微好了一点。

下面是整个训练过程中的采样输出:

输出的图还是不够高清。
2. 基于重建的异常检测
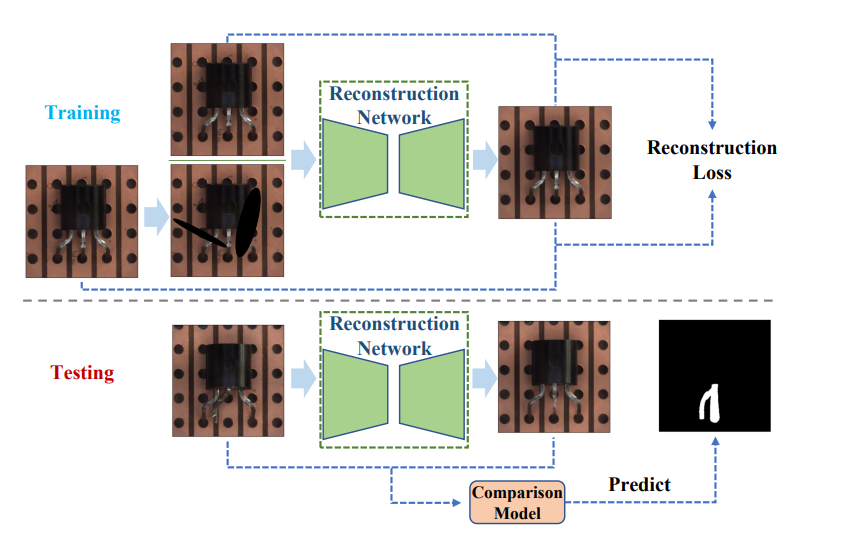
参考文献
[1] Deep Industrial Image Anomaly Detection: A Survey.arXiv:2301.11514v2 [cs.CV] 30 Jan 2023
文章来源:https://blog.csdn.net/qq_40622955/article/details/131076133
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- NonTransientDataAccessResourceException(非瞬时数据访问资源异常)可能的原因和解决方法
- 2024年AMC8历年真题练一练和答案详解(8),以及全真模拟题
- 2024年做为程序员的我们面临生成式人工智能所需要的新思维
- Ubuntu中查看IP地址的常用命令及使用方法
- (01)半导体前道的前世今生
- Qt连接数据库(内含完整安装包)
- 【VBScript】vbs 错误未结束的错误字符串常量
- C++模版类
- 23种设计模式Python版
- 如何在出厂重置后从 Android 恢复丢失的数据、照片、联系人