VMLoc模型解读和原理分析
目录
一. 概述
论文名称:VMLoc: Variational Fusion For Learning-Based Multimodal Camera Localization
论文地址:http://arxiv.org/pdf/2003.07289v4.pdf![]() http://arxiv.org/pdf/2003.07289v4.pdf论文摘要:?
http://arxiv.org/pdf/2003.07289v4.pdf论文摘要:?
????????以前的深度融合方法并不比使用单一模态的模型表现得更好。我们推测这是由于通过求和或连接进行特征空间融合的幼稚方法,没有考虑到每个模态的不同强度。为了解决这个问题,我们提出了一个端到端框架,称为VMLoc,通过变化的Product- of-Experts (PoE)和基于注意力的融合,将不同的传感器输入融合到一个共同的潜在空间。不同于以往的多模态变分工作直接适应vanilla变分自动编码器的目标函数,我们展示了如何通过一个基于重要性加权的无偏目标函数准确估计摄像机的定位。我们的模型在RGB- D数据集上进行了广泛的评价,结果证明了我们的模型的有效性。
二.?模型解读和原理分析
1. 特征编码器
? ? ? ? 该模型通过ResNet34+可适应平均池化+FC提取不同模态的潜在特征空间信息。通过获取特征信息的均值和方差来构建潜在特征空间。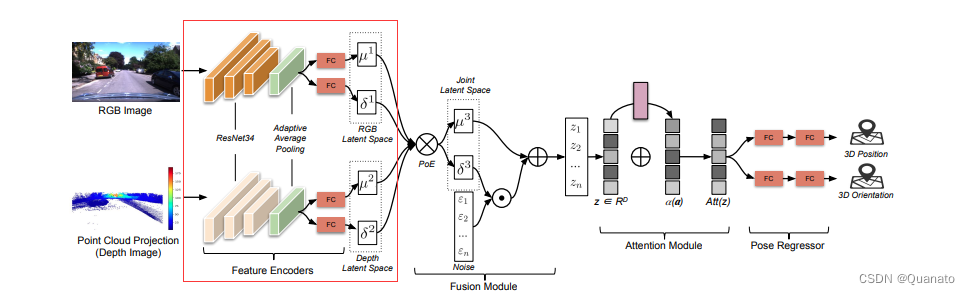
原理 : 变分推理ELMO。通过编码器获得近似的隐变量的后验概率密度分布, 其实就是经过encoder提取的均值和方差构建近似的隐变量(特征)的概率密度分布。均值和方差基本等同于特征空间的分布。
可见笔者之前的文章
2. 多模态融合?
? ? ? ? 该模型通过POE来融合多模态的概率密度分布来获取融合后特征空间分布。在得到的均值上增添(0,1)高斯噪音,通过概率分布生成融合后的特征样本z =?
?+
。这里采用了重参数化技巧?the reparameterization trick (Kingma and Welling 2013)。
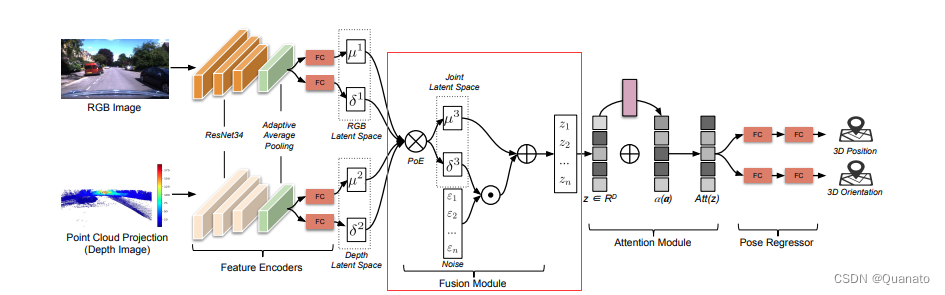
原理:POE(Product Of Expert, 译为专家点积)
可见笔者之前的文章
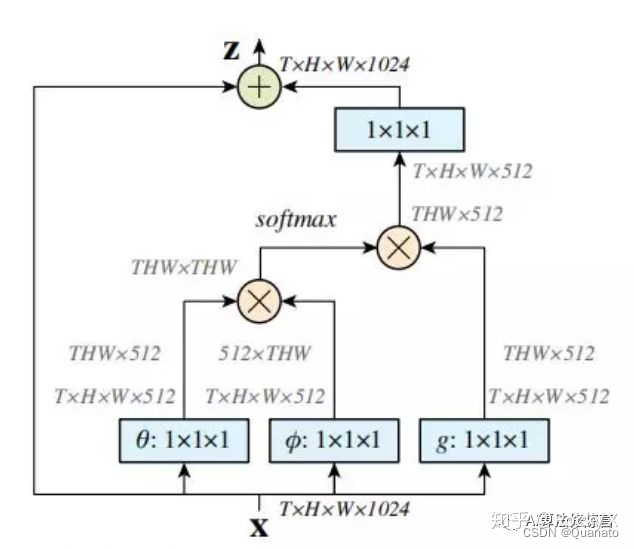
3. 特征解码器
? ? ? ? 这里的解码器是非局部信息统计的注意力机制the non-local style self-attention (Wang et al. 2018)进行多模态交互,再通过FC层对应下游任务的输出进行训练。
非局部信息统计的注意力机制
4. 数据增强

三. 总结
????????由于各种传感器模态之间的特性不同,有效利用多模态数据进行定位是一个具有挑战性的问题。本文提出了一种基于多模态变分学习的新型多模态定位框架(VMLoc)。特别是,我们采用基于重要性加权的无偏目标函数设计了一种新的PoE融合模块,旨在从不同模态中学习公共潜在空间。我们的实验表明,与现有的单图像或多模态学习算法相比,这种方法在良性条件下或输入数据损坏时都能产生更准确的定位。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言实现大数的加法
- 二叉树的层序遍历,力扣
- 【Spring源码分析】从源码角度去熟悉依赖注入(一)
- Java thumbnailator 图片处理,指定大小缩放、旋转、裁剪、格式转换
- MIT_线性代数笔记:第 23 讲 微分方程和 exp(At)
- 数据结构入门到入土——链表(1)
- 【Docker篇】从0到1搭建自己的镜像仓库并且推送镜像到自己的仓库中
- 网络工程师:新兴科技基础知识面试题(十四)
- Oracle修改用户密码
- 算法通关村第十二关-字符串基础题目