论文精读:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Status: Reading
Author: Chunrui Han, Haoran Wei, Jianjian Sun, Jinrong Yang, Jinyue Chen, Liang Zhao, Lingyu Kong, Xiangyu Zhang, Zheng Ge
Institution: 中国科学院大学, 华中科技大学, 旷视科技(MEGVII Technology)
Publisher: arXiv
Publishing/Release Date: December 11, 2023
Score /5: ??????
Type: Paper
Link: https://arxiv.org/abs/2312.06109
论文精读
摘要
大规模视觉-语言模型(Large Vision-Language Models,LVLMs)基本上使用得都是同一个视觉词表——CLIP,它也适用于大部分的视觉任务。但是,对于一些特殊的任务往往需要更密集和更细致的感知,比如文档OCR和图标理解,特别是对于非英语场景,CLIP的词表在分词时往往比较低效,并且还可能会遇到无法分词的问题。基于此问题,作者提出了Vary(Vision vocabulary),一种有效扩展LVLMs视觉词表的方法。该方法主要包括两步,首先是生成新的视觉词表,作者通过解码器 Transformer 设计了一个词表网络,通过自回归的方式生成词表。然后将新的词表合并到原本的视觉词表(CLIP)中,以此来快速增强LVLMs的特征表示能力。
引言
类似于GPT-4的LVLMs,比如BLIP-2、MiniGPT4、LLaVA和Qwen-VL等,在各个方面都有很出色的性能,它们一般都具有两部分:LLMs和视觉编码器。为了将图像编码与文本编码对齐,BLIP-2和MiniGPT-4引入了高质量的图像-文本对进行有监督微调,LLaVA则是利用线性层将视觉编码映射到文本编码,Qwen-VL则是利用了交叉注意力层。
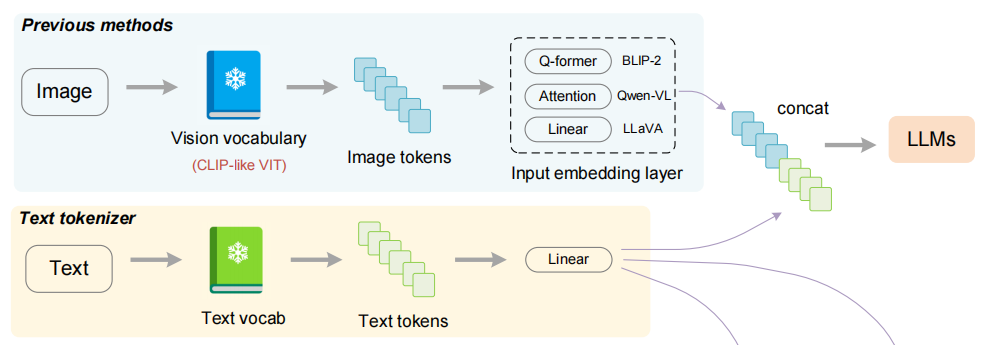
然而,上述的LVLMs的视觉编码器部分基本上都是CLIP,这有可能会成为一个瓶颈。我们可以将CLIP视为一个巨大的通用视觉词表,但是在一些特殊的领域(例如中文OCR),CLIP可能无法非常有效的将所有的视觉信息编码进一个固定长度的tokens中。尽管mPlug-Owl和Qwen-VL通过解冻并继续训练视觉编码器的方式来缓解上述问题,但是作者认为这种方法会有3个问题:① 可能会覆盖原始词表的知识;② 在较大的LLM上的训练效率较低;③ LLM具有较强的记忆能力,因此不能一张图片看多次,也就是说epoch不能太大。
作者提出的Vary启发于LLMs中的文本词表扩充,主要分为两步:① 生成新的词表;② 合并新旧词表。如下图所示,首先第一步,构造了一个小的pipeline,包含一个词表网络和一个小的解码器Transformer,然后通过自回归的方式来训练词表网络。作者认为,基于自回归的训练方式可能比CLIP基于对比学习的方式更加适合密集感知型任务。(这一块以OCR为例,那这个pipeline的输入就是图片,输出就是文本)一方面,自回归的next-token可以让视觉词表压缩更长的文本,另一方面,这种方式可以使用的数据格式更加多样。然后第二步,将新的视觉词表添加到LVLMs,这一步为了避免知识覆盖,将新旧词表网络都冻结了。
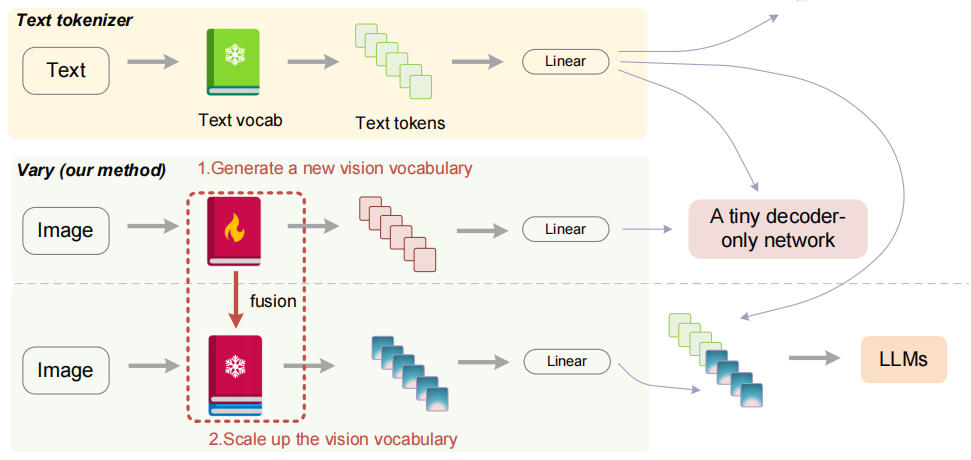
Vary通过增加视觉词表,可以有效地增强LVLMs在下游视觉任务的适配能力。
方法
架构
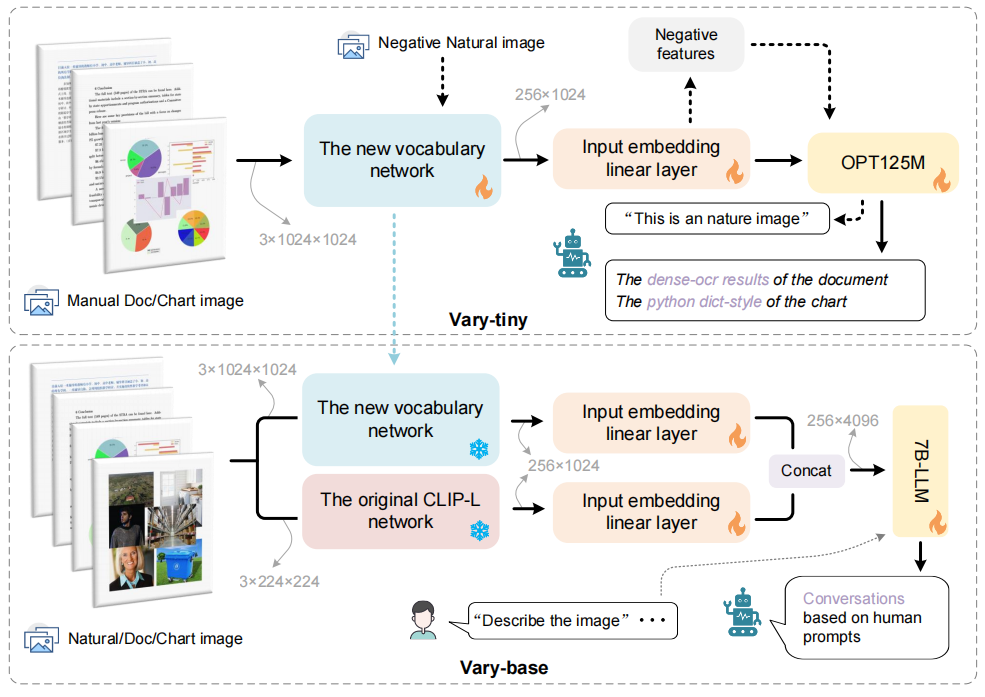
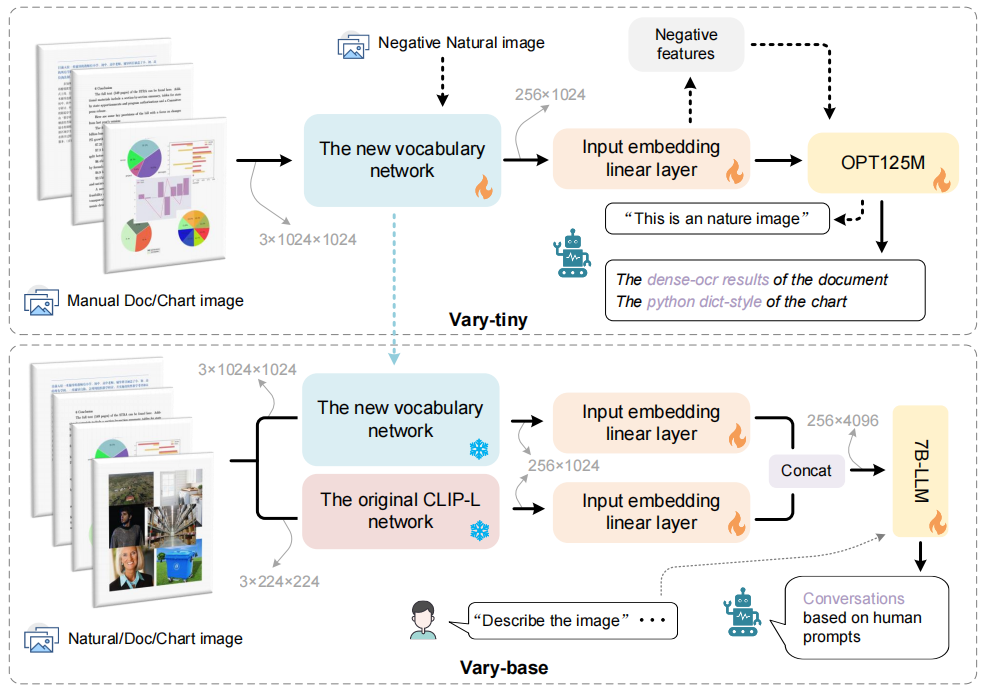
Vary在架构上分为两个模块:Vary-tiny和Vary-base,Vary-tiny负责生成新的视觉词表,Vary-base则是使用新的词表。
Vary-tiny由一个词表网络和一个OPT-125M组成,为了集中于细粒度的感知任务,这个模块中并没有文本输入。作者希望新的视觉词表网络可以更好的处理人工图片,例如文档和图表,以此来弥补CLIP的不足。因此在训练Vary-tiny时,数据集中,文档和图表数据是正例,而自然图像是负例。
在Vary-base中,两个词表之间通过一个线性层来对齐,两个词表网络冻结后,各自独立进行分词,在进入LLM之前再concat在一起。
生成新的视觉词表
- 新词表
使用SAM预训练的ViTDet图像编码器作为新的词汇表网络的主要部分,但是由于它的输入图片分辨率是1024×1024,最后一层输出的特征图尺寸是64×64×256,跟CLIP-L的输出尺寸对不上,因此又加了两个卷积层进行转换。
- 数据集
文档数据:主要是高分辨率的图像-文本对作数据集的正例,尤其是OCR可以训练模型的细粒度图像感知能力。这块的数据集是作者自建的,收集了arXiv上的PDF文章然后用PyMuPDF提取文本信息以及将每一页转换为图片。构建了1M的中文和1M的英文文档图像-文本对。
图表数据:现有的LVLMs的图表理解能力很差,因此这也是新词表需要重点掌握的知识。作者从网上找了一些语料,分别通过matplotlib和pyecharts绘制图表(中英文各750k),并将文本真实值转换为Python的字典形式。
负例的自然图像:对于自然图像数据CLIP处理的非常好,因此需要确保新的词表不会对其造成干扰。因此,作者又从COCO数据集中采样了120k张图片作为负例的图像-文本对,以此来保证新的词表网络能够正确的编码这些自然图像。
- 输入格式
图像编码以前缀的形式跟文本编码打包在一起,用和来表示图像编码的开始和结束。
扩充视觉词表
- Vary-base的结构
新的视觉词表和原本的CLIP是并行的,各自有独立的输入嵌入层,也就是一个线性层,最后将输出concat在一起。
- 数据集
LATEX文档:从arXiv上收集了一些.tex文档,然后提取其中的表格、数学公式和纯文本,通过pdflatex进行重新渲染,得到了50w的英文页面和40w的中文页面。
语义关联图表渲染:利用GPT-4根据相关语料库生成了200k的高质量图表数据用于训练Vary-base。
通用数据:先用从LAION-COCO中采样的4 million样本进行预训练,然后用LLaVA-80k或LLaVA-CC665k以及DocVQA和ChartVQA作为SFT数据集。
- 对话格式
<|im_start|>user: “” “texts input”<|im_end|> <|im_start|>assistant: “texts output” <|im_end|>
实验
数据集与评价指标
作者在做个数据集对模型进行了评估,主要包括:
- 做着自己创建的OCR测试集,用以测试模型的细节感知能力;
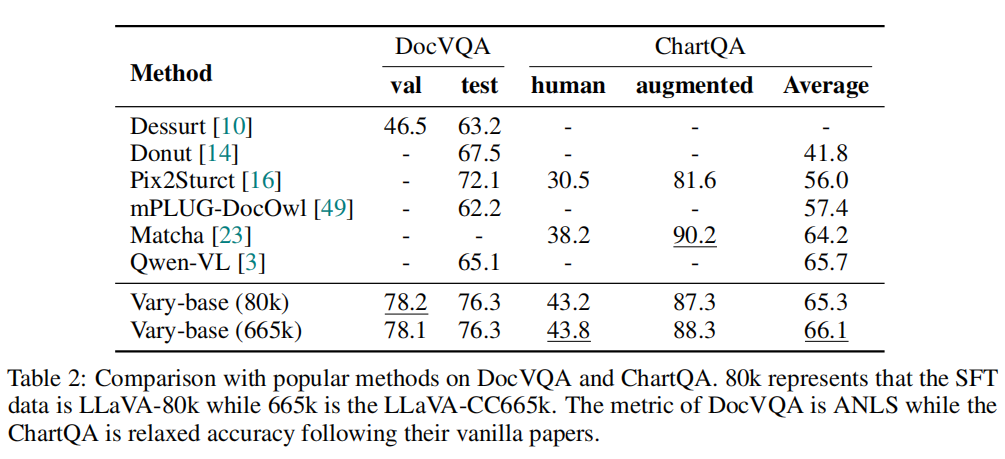
- DocVQA和ChartQA,测试模型对下游任务的提升;
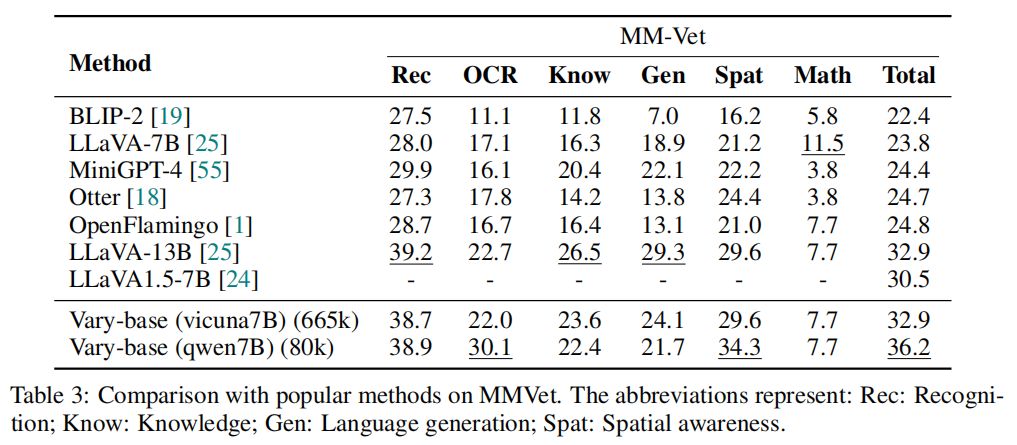
- MMVet,测试模型的通用性能。
实现细节
在Vary-tiny训练阶段,对所有参数进行了优化,批量大小为512,训练周期为3,使用AdamW优化器和余弦退火调度器,学习率设定为5e-5。
对于Vary-base的训练,冻结了视觉词汇网络的权重,专注于优化输入嵌入层和LLM的参数,其中预训练的学习率为5e-5,SFT阶段为1e-5,批量大小为256,训练周期为1。其他设置与Vary-tiny保持一致。
细节感知能力

下游任务能力
通用能力
Vary的训练策略不会伤害模型的通用能力。
结论
这篇文章主要强调了扩充LVLMs的视觉编码词表的重要性,实验结果证明成绩还可以。
作者认为这个方向还有改进空间,因为现在的文本词表扩展方法相对来说更加简单易用。
Notion持续更新:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C#学习教程一
- 基于ssm网上茶叶销售平台设计与开发论文
- C++学习-2023/12/13-C++类型转换
- Python基础-07(for循环、range()函数)
- 【K12】练习使用Python数学函数解物理中的电功率变化的问题
- 【R语言】完美解决devtools安装GitHub包失败的问题(以gwasglue为例)
- 腾讯云服务器租用价格表_2024新版报价
- python高级练习题库实验2(B)部分
- 零基础学C语言——预编译
- 贝蒂详解<string.h>哦~(用法与实现)