什么是范数【向量范数、矩阵范数】
文章目录
一、定义
范数,在线性代数、泛函分析及相关的数学领域,是一个函数,其为向量空间内的所有向量赋予非零的正长度或大小。范数事实上就是线性空间上定义的一类函数,这类函数需要满足三条性质,具体定义如下:
设 X \mathcal{X} X是给定的线性空间,向量范数 ∥ ? ∥ \|\cdot\| ∥?∥ 是定义在 X \mathcal{X} X上的实值函数, 对 X \mathcal{X} X中的任意向量 x ? \vec{x} x 和 y ? \vec{y} y?, 满足:
- ∥ x ? ∥ ≥ 0 \|\vec{x}\| \geq 0 ∥x∥≥0 ,当且仅当 x ? = 0 \vec{x}=0 x=0 时, ∥ x ? ∥ = 0 \|\vec{x}\|=0 ∥x∥=0 (正定性)
- ∥ k x ? ∥ = ∣ k ∥ x ? ∥ , k \|k \vec{x}\|=\mid k\|\vec{x}\|, k ∥kx∥=∣k∥x∥,k 是任一实数 (齐次性)
- ∥ x ? + y ? ∥ ≤ ∥ x ? ∥ + ∥ y ? ∥ \|\vec{x}+\vec{y}\| \leq\|\vec{x}\|+\|\vec{y}\| ∥x+y?∥≤∥x∥+∥y?∥ (三角不等式)
二、向量范数
由向量范数的定义,我们可以给出向量
?
p
\ell_p
?p?-范数的定义:
定义(
?
p
\ell_p
?p?-范数)
若向量 x = [ x 1 , x 2 , ? ? , x n ] T \mathrm{x}=[x_1,x_2,\cdots,x_n]^T x=[x1?,x2?,?,xn?]T,则其 ? p \ell_p ?p?-范数为:
∥ x ∥ p = ( ∑ i = 1 n x i p ) 1 p \begin{equation} \Vert \mathrm{x} \Vert_p=(\sum\limits_{i=1}^{n}{x_i^p})^{\frac{1}{p}} \end{equation} ∥x∥p?=(i=1∑n?xip?)p1???
(1)L0范数
根据p的取值的变化,可以得到不同的范数, 当
p
=
0
p=0
p=0, 我们就有了
l
0
l_0
l0?-范数, 即:
∥
x
∥
0
=
∑
i
x
i
0
0
\begin{equation} \|\boldsymbol{x}\|_0=\sqrt[0]{\sum_i x_i^0} \end{equation}
∥x∥0?=0i∑?xi0????
表示向量
x
\boldsymbol{x}
x 中非0元素的个数 。在诸多机器学习模型中,比如多任务学习中的行稀疏问题 , 我们很多时候希望最小化向量的
?
0
\ell_0
?0?-范数。然而, 由于
?
0
\ell_0
?0?-范数仅仅表示向量中非0元素的个数, , 这个优化模型在数学上被认为是一个 NP-hard问题,即直接求解它很复杂。正是由于该类优化问题难以求解, 因此,很多时候是将
?
0
\ell_0
?0?-范数最小化问题,转换成
?
1
\ell_1
?1?-范数最小化问题。
(2)L1范数
当p=1时,可以得到常见的
?
1
\ell_1
?1?-范数,
?
1
\ell_1
?1?-范数有很多的名字, 例如我们熟悉的曼哈顿距离、最小绝对误差等。它的定义如下:
∥
x
∥
1
=
∑
i
=
1
n
∣
x
i
∣
\begin{equation} \|\mathbf{x}\|_1=\sum_{i=1}^n\left|x_i\right| \end{equation}
∥x∥1?=i=1∑n?∣xi?∣??
?
1
\ell_1
?1?-范数表示向量x中非零元素的绝对值之和。对于
?
1
\ell_1
?1?-范数, 它的优化问题为:
?
min
?
∥
x
∥
1
=
Σ
i
=
1
n
∣
x
i
∣
\ \min \|\mathbf{x}\|_1 =\Sigma_{i=1}^n|x_i|
?min∥x∥1?=Σi=1n?∣xi?∣由于
?
1
\ell_1
?1?-范数的性质, 对其优化的解是一个稀疏解, 因此
?
1
\ell_1
?1?-范数也被叫做稀疏规则算子。
- 在经典的线性回归问题中运用 ? 1 \ell_1 ?1?-范数,也被称为Lasso回归。Lasso回归通过 ? 1 \ell_1 ?1?-范数可以实现特征的稀疏或者说特征选择, ? 1 \ell_1 ?1?-范数会将一些特征的权重压缩到 0,从而实现自动的特征筛选和降维的效果。
- 通过 ? 1 \ell_1 ?1?-范数的特征选择还可以避免模型的过拟合问题,原因在于它能够减少模型的复杂度,并去除那些对目标变量没有贡献或贡献较小的特征,这样做可以提高模型的泛化能力,从而降低过拟合的风险。
(3)L2范数
当p=2时,可以得到
?
2
\ell_2
?2?-范数,
?
2
\ell_2
?2?-范数是我们最常见最常用的范数了, 我们用的最多的度量距离欧氏距离就是一种
?
2
\ell_2
?2?-范数, 它的定义如下:
∥
x
∥
2
=
∑
i
=
1
n
x
i
2
\begin{equation} \|\mathbf{x}\|_2=\sqrt{\sum_{i=1}^n x_i^2} \end{equation}
∥x∥2?=i=1∑n?xi2????
表示向量元素的平方和再开平方。
- 同 ? 1 \ell_1 ?1?-范数一样, ? 2 \ell_2 ?2?-范数也常会被用来做优化目标函数的正则化项, ? 2 \ell_2 ?2?-范数正则化会对模型参数的平方和进行惩罚,使得模型的权重趋向于分布在较小的范围内,这样做可以有效避免过于复杂的模型,从而提升模型的泛化能力。
- 在经典的线性回归问题中,加入 ? 2 \ell_2 ?2?-范数的约束,被称为岭回归,可参考文章。
(4)等价范数
这里总结一下常用的向量范数:
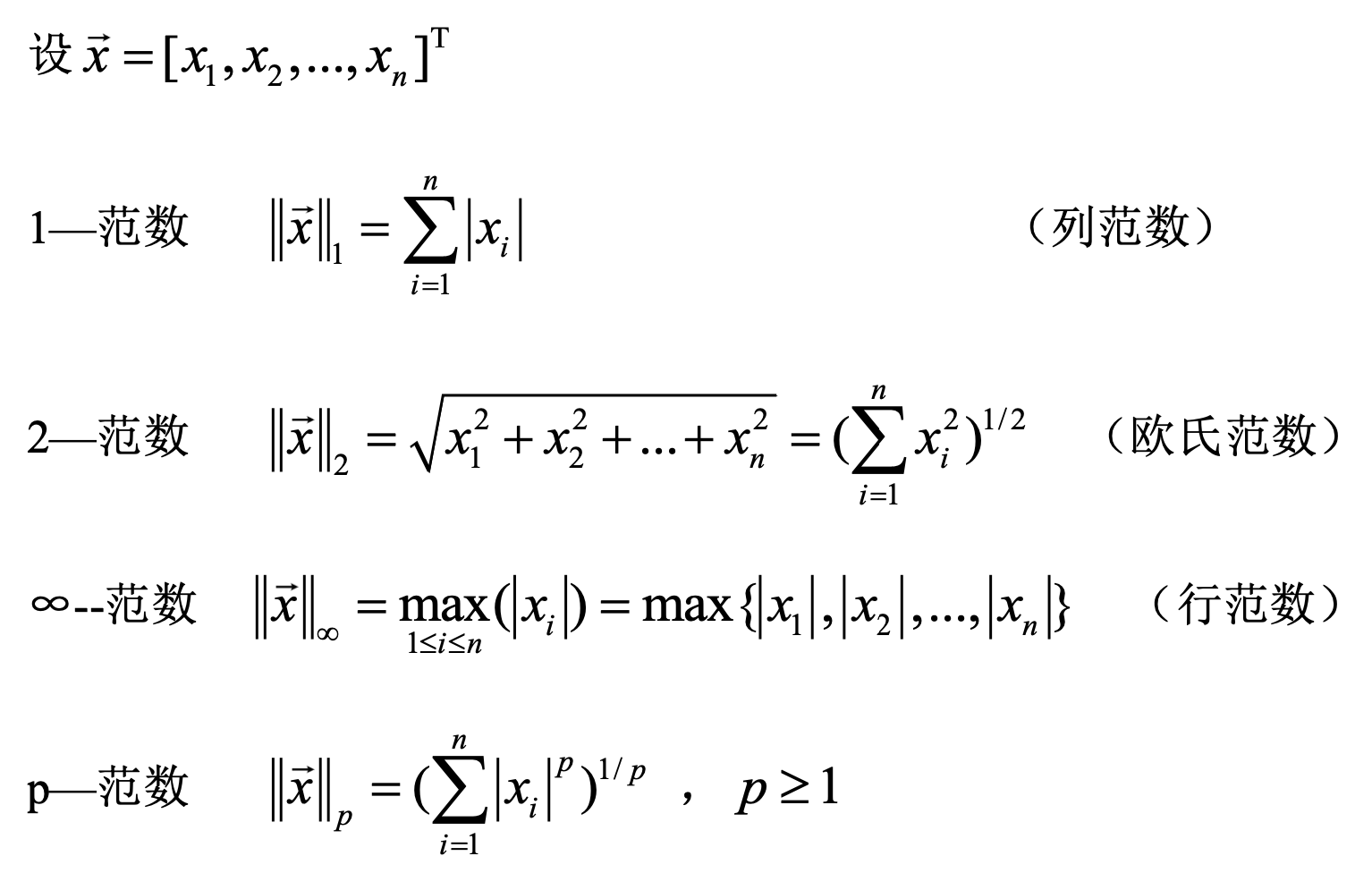
事实上, 线性空间 X \mathcal{X} X 中任意两种范数都是等价的
如果 X \mathcal{X} X 中有两个范数 ∥ ? ∥ \|\cdot\| ∥?∥ 和 ∥ ? ∥ ′ \|\cdot\| \prime ∥?∥′, 存在实数 m , M > 0 m, M>0 m,M>0, 使得对任意 n n n 维向量 x \boldsymbol{x} x, 都有 :
m ∥ x ∥ ? ∥ x ∥ ′ ? M ∥ x ∥ m\|x\| \leqslant\|x\|^{\prime} \leqslant M\|x\| m∥x∥?∥x∥′?M∥x∥
则称这两种范数是等价的。
- 对于两种等价的范数,同一向量序列有相同的极限.
下面以无穷范数和二范数为例,证明它们的等价性:
由无穷范数的定义可得: ∥ x ∥ ∞ = max ? 1 ? i ? n { ∣ ∣ x i ∣ ∣ } ? x 1 2 + x 2 2 + ? + x n 2 = ∥ x ∥ 2 \|\boldsymbol{x}\|_{\infty}=\max _{1 \leqslant i \leqslant n} \left\{|| x_i ||\right\} \leqslant \sqrt{x_1^2+x_2^2+\cdots+x_n^2}=\|\boldsymbol{x}\|_2 ∥x∥∞?=1?i?nmax?{∣∣xi?∣∣}?x12?+x22?+?+xn2??=∥x∥2?
设 ∥ x ∥ ∞ = ∣ x j ∣ = max ? 1 ≤ i ≤ n { ∣ x i ∣ } \|\boldsymbol{x}\|_{\infty}=\left|x_j\right|=\max\limits_{1\leq i\leq n}\left\{\left|x_i\right|\right\} ∥x∥∞?=∣xj?∣=1≤i≤nmax?{∣xi?∣}, 则:
∥ x ∥ ∞ = ∣ x j ∣ ? x 1 2 + x 2 2 + ? + x n 2 n = ∥ x ∥ 2 n \|\boldsymbol{x}\|_{\infty}=\left|x_j\right| \geqslant \sqrt{\frac{x_1^2+x_2^2+\cdots+x_n^2}{n}}=\frac{\|\boldsymbol{x}\|_2}{\sqrt{n}} ∥x∥∞?=∣xj?∣?nx12?+x22?+?+xn2???=n?∥x∥2??
所以, 2- 范数与 ∞ ? \infty- ∞? 范数是等价的
二、矩阵范数
矩阵范数有较多的定义,这里介绍几种常见的矩阵范数定义。
(1)Element-wise Norm
类似向量 l p l_p lp?范数的定义,Element-wise矩阵范数定义如下:
对 A ∈ R n × m A \in \mathbb{R}^{n \times m} A∈Rn×m,其 l p l_p lp?范数为:
∥ A ∥ p = ( ∑ i = 1 n ∑ i = 1 m ∣ a i j ∣ p ) 1 p \quad\|A\|_p=\left(\sum_{i=1}^n \sum_{i=1}^m\left|a_{i j}\right|^p\right)^{\frac{1}{p}} ∥A∥p?=(i=1∑n?i=1∑m?∣aij?∣p)p1?
事实上,这个也可以看作向量范数的一种,我们将矩阵向量化:
Vec
?
(
A
)
=
[
A
1
A
2
?
A
m
]
m
n
?
∥
A
∥
p
=
∥
vec
?
(
A
)
∥
p
\operatorname{Vec}(A)=\left[\begin{array}{c} A_1 \\ A_2 \\ \vdots \\ A_m \end{array}\right]_{m n} \Rightarrow \|A\|_p=\|\operatorname{vec}(A)\| p \\
Vec(A)=
?A1?A2??Am??
?mn??∥A∥p?=∥vec(A)∥p
一个常用的矩阵范数是
p
=
2
p=2
p=2时,也就是Frobenius范数:
∥
A
∥
2
=
(
∑
i
=
1
m
∑
i
=
1
n
∣
a
i
j
∣
2
)
1
2
\|A\|_2=\left(\sum_{i=1}^m \sum_{i=1}^n\left|a_{i j}\right|^2\right)^{\frac{1}{2}}
∥A∥2?=(i=1∑m?i=1∑n?∣aij?∣2)21?
也常记为
∥
?
∥
F
\|\cdot\|_F
∥?∥F?:
∥
A
∥
F
=
tr
?
(
A
T
A
)
=
∑
σ
i
2
(
A
)
\|A\|_F=\sqrt{\operatorname{tr}\left(A^T A\right)} =\sqrt{\sum \sigma_i^2(A)}
∥A∥F?=tr(ATA)?=∑σi2?(A)?
第一个等号由迹运算定义可以得到,第二个等号证明如下:
证明:
设矩阵 A A A奇异值分解为 A = U Σ V T A=U\Sigma V^T A=UΣVT,结合 ∥ ? ∥ F \|\cdot\|_F ∥?∥F?是酉不变范数(见第五小节的介绍)可得:
∥ A ∥ F = ∥ U Σ V T ∥ F = ∥ Σ ∥ F = ∑ i = 1 n σ i 2 . \|A\|_F=\|U\Sigma V^T\|_F=\|\Sigma\|_F=\sqrt{\sum_{i=1}^n\sigma_i^2}. ∥A∥F?=∥UΣVT∥F?=∥Σ∥F?=i=1∑n?σi2??.
(2)Induced Norm
矩阵 A ∈ R n × m A\in\mathbb{R}^{n\times m} A∈Rn×m的诱导范数也被称为算子范数(operator norm),定义如下:
对任意 A ∈ R n × m A\in\mathbb{R}^{n\times m} A∈Rn×m,其诱导p范数为:
∥ A ∥ p = sup ? x ∈ R m , x ≠ 0 ∥ A x ∥ p ∥ x ∥ p = sup ? x ∈ R m ∥ x ∥ p = 1 ∥ A x ∥ p . \|A\|_p=\sup _{x \in \mathbb{R}^m,x\neq 0} \frac{\|A x\| p}{\|x\|_p}\\ =\sup _{\substack{x \in \mathbb{R}^m \\ \|x\|_p=1}}\|A x\|_p . ∥A∥p?=x∈Rm,x=0sup?∥x∥p?∥Ax∥p?=x∈Rm∥x∥p?=1?sup?∥Ax∥p?.
常见的诱导矩阵范数如下:
∥
A
∥
1
=
max
?
1
≤
j
≤
m
∑
i
=
1
n
∣
a
i
j
∣
(
最大列和
)
∥
A
∥
2
=
σ
1
(
A
)
(
?谱范数?
)
.
∥
A
∥
∞
=
max
?
1
≤
i
≤
n
∑
j
=
1
m
∣
a
i
j
∣
(
最大行和
)
.
\begin{aligned} & \|A\|_1=\max _{1 \leq j \leq m} \sum_{i=1}^n\left|a_{i j}\right| (最大列和)\\ & \|A\|_2=\sigma_1(A)\qquad\quad(\text { 谱范数 }) . \\ & \|A\|_{\infty}=\max _{1 \leq i \leq n} \sum_{j=1}^m\left|a_{i j}\right| (最大行和). \end{aligned}
?∥A∥1?=1≤j≤mmax?i=1∑n?∣aij?∣(最大列和)∥A∥2?=σ1?(A)(?谱范数?).∥A∥∞?=1≤i≤nmax?j=1∑m?∣aij?∣(最大行和).?

(3)ky-Fan Norm
矩阵 A ∈ R n × m A\in\mathbb{R}^{n\times m} A∈Rn×m的ky-Fan范数定义如下:
对任意 A ∈ R n × m A\in\mathbb{R}^{n\times m} A∈Rn×m,其ky-Fan范数为:
∥ A ∥ ( k ) = ∑ i = 1 k σ i \|A\|_{(k)}=\sum_{i=1}^k \sigma_i ∥A∥(k)?=i=1∑k?σi?
其中 σ i \sigma_i σi?是 A A A的第 i i i大的奇异值( σ 1 ≥ σ 2 ≥ ? ≥ σ min ? { m , n } \sigma_1\geq\sigma_2\geq\cdots\geq \sigma_{\min\{m,n\}} σ1?≥σ2?≥?≥σmin{m,n}?).
如何证明这个定义确实是一个范数,第一二条的正定性和齐次性验证都比较简单,对于三角不等式的验证,可以利用优超不等式,具体查阅参考文献1.
k=1时,导出谱范数:
∥
A
∥
(
1
)
=
σ
1
(
A
)
\|A\|_{(1)}=\sigma_1(A)
∥A∥(1)?=σ1?(A)
另一个一个常用的是核范数,对
A
∈
R
n
×
m
A\in\mathbb{R}^{n\times m}
A∈Rn×m,若
n
?
m
n \geqslant m
n?m,其核范数为:
∥
A
∥
(
m
)
=
σ
1
+
?
+
σ
m
(
?核范数?
)
.
\begin{aligned} \quad\|A\|_{(m)}=\sigma_1+\cdots+\sigma_m \quad(\text { 核范数 }) . \end{aligned}
∥A∥(m)?=σ1?+?+σm?(?核范数?).?
(4)Schatten norms
对任意 A ∈ R n × m A\in\mathbb{R}^{n\times m} A∈Rn×m(设m<n),Schatten p-范数定义为:
∥ A ∥ p = [ ∑ j = 1 m ( σ j ( A ) ) p ] 1 / p , 1 ≤ p < ∞ , \|A\|_p=[\sum_{j=1}^m(\sigma_j(A))^p]^{1/p},\quad1\leq p<\infty, ∥A∥p?=[j=1∑m?(σj?(A))p]1/p,1≤p<∞,
常见的Schatten p-范数如下:
∥
A
∥
1
=
∑
i
=
1
m
σ
i
(
A
)
(
核范数
)
.
∥
A
∥
2
=
∑
i
=
1
m
δ
i
2
(
A
)
(
F
?
范数
)
.
∥
A
∥
∞
=
σ
1
(
A
)
,
(
谱范数
)
.
\begin{aligned} \|A\|_1&=\sum_{i=1}^m\sigma_i\left(A\right)\quad\left(\text{核范数}\right).\\ \|A\|_2&=\sqrt{\sum_{i=1}^m\delta_i^2\left(A\right)}\quad\left(F-\text{范数}\right).\\ \|A\|_{\infin}&=\sigma_1\left(A\right)\quad,\left(\text{谱范数}\right).\end{aligned}
∥A∥1?∥A∥2?∥A∥∞??=i=1∑m?σi?(A)(核范数).=i=1∑m?δi2?(A)?(F?范数).=σ1?(A),(谱范数).?
我们可以看到,由不同范数的定义,可以导出相同的范数。
(5)Unitarily invariant Norms
酉不变范数是指:
X \mathcal{X} X上的范数 ∥ ? ∥ \|\cdot\| ∥?∥如果满足,对任意的 A ∈ R m × n A\in\mathbb{R}^{m\times n} A∈Rm×n,以及任意的酉矩阵 U , V U,V U,V,都有:
∥ U A V T ∥ = ∥ A ∥ \|UAV^T\|=\|A\| ∥UAVT∥=∥A∥
则称 ∥ ? ∥ \|\cdot\| ∥?∥是酉不变范数.
满足这个条件的范数有很好的性质,上面介绍的ky-Fan Norm和Schatten norms都是酉不变范数,所以由这两个范数定义导出的各种范数也是酉不变的,比如F-范数.
参考资料
- Horn, Roger A., and Charles R. Johnson. Matrix analysis. Cambridge university press, 2012.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 面试每日三题
- REHL_用yum/dnf管理软件包
- 第10章-特殊函数-指数积分函数
- 17. C++ static、const 和 static const 类型成员变量声明以及初始化
- ELK简单介绍一
- 智能优化算法应用:基于海洋捕食者算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- 性能优化2.0,新增缓存后,程序的秒开率不升反降
- 使用Go语言采集1688网站数据对比商品价格
- Matplotlib笔记:安装Matplotlib+常用绘图
- 代码随想录算法训练营第六天 |242.有效的字母异位词,349.两个数组的交集,202.快乐数,1.两数只和