多核编程(erlang 学习笔记)(二)
3.映射-归并算法和磁盘索引程序
现在我们要从理论转向实践。首先,我们要来看看高阶函数mapreduce,然后我们会在一个简单的索引引擎中使用这种技术。在这里,我们的目标并不是要做一个世上最快最好的索引引擎,而是要通过这一技术来解决相关应用场景下真实面对的设计问题。
1.映射-并归算法?
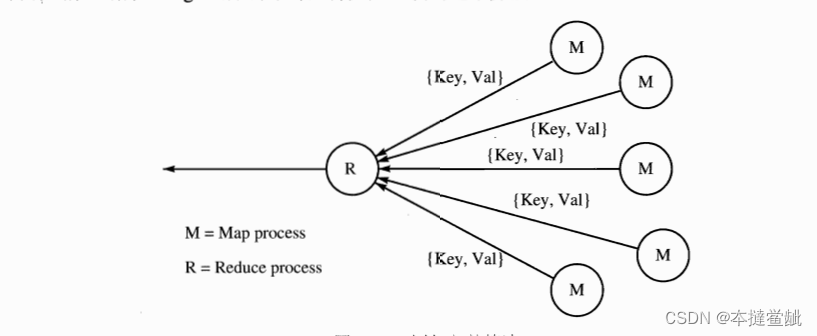
?在图中,向我们展示了映射-归并(map-reduce)算法的基本思想。开启一定数量的映射
进程,让它们负责产生一系列的{Key,Value}这样的键-值对。映射进程把这些键-值对发送给
一个归并进程,它负责合并这些键一值对,合并的方式就是把有相同键的值组合起来。
mapreduce(映射-归并算法)是由Google公司的Jeffrey Dean和Sanjay Ghemawat提出的高阶并行函数,据说Google的集群中每天都要大量使用这个算法。?
我们可以用多种不同的方式来实现多种不同语意的映射-归并算法。这个算法与其说是特定的算法,还不如说是一个算法族。
mapreduce是这么定义的:
@spec mapreduce(F1, F2, Acc0, L) -> Acc
F1 = fun(Pid, X)-> void,
F2 = fun(Key, [Value], Acc0) -> Acc
L=[X]
Acc = X = term()?F1(Pid,X)是映射函数。F1的任务是发送一组{Key,Value}数据给Pid,然后退出。mapreduce每次会给列表中的每个X创建一个新的进程。
F2(Key, [Value],Acc0)?->Acc是归并函数。当所有的映射函数都退出的时候,归并函数要负责针对每个键,将它对应的所有的值合并到一起。此时,它会对每一个它收集到的[Key,[Value]]调用F2(Key,[Value],Acc)函数。Acc是一个累加器,它的初始值是Acc0。F2会返回 个新的累加器(另外 种描述方式是这样,F2在所有它收集到的[Key,[Value]]对上执行 个折叠操作。
Acc0是累加器的初始值,当调用F2时会被使用。
L是一个X的列表。F1(Pid,X)会对列表L中的每一个X进行运算,Pid是由mapreduce创建的归并进程的进程标识符。
mapreduce定义在phofs(parallel higher-order function的缩写)模块中:
phofs.erl
-module(phofs).
-export([mapreduce/4]).
-import(lists,[foreach/2]).
mapreduce(F1,F2,Acc0,L)->
S = self(),
Pid = spawn(fun() -> reduce(S,F1,F2,Acc0,L) end),
receive
{Pid,Result} ->
Result
end.
reduce(S,F1,F2,Acc0,L) ->
process_flag(trap_exit,true),
ReducePid = self(),
foreach(fun(X) ->
spawn_link(fun() -> do_jop(ReducePid,F1,X)end)
end,L),
N = length(L),
Dict0 = Dict:new(),
Dict1 = collect_replies(N,Dict0),
Acc = dict:fold(F2,Acc0,Dict1),
Parent ! {self(),Acc}.
collect_replies(0,Dict)->
Dict;
collect_replies(N,Dict)->
receive
{Key,Val} ->
case dict:is_key(Key,Dict) of
true ->
Dict1 = dict:append(Key,Var,Dict),
false ->
Dict1 = dict:store(Key,[Var],Dict),
collect_replies(N,Dict1)
end;
{'EXIT',_,Why} ->
collect_replies(N,Dict1)
end.
do_jop(ReducePid,F,X) ->
F(ReducePid,X)再写一个小程序
test_mapreduce.erl
-module(test_mapreduce).
-compile(export_all).
-import(lists, [reverse/1,sort/1])
test() ->
wc_dir(".").
wc_dir(Dir)->
F1 = fun generate_words/2,
F2 = fun count_words/3,
Files = lib_find:files(Dir, "*.erl'" false),
L1 = phofs:mapreduce(F1,F2, [],Files),
reverse(sort(L1)).
generate_words(Pid, File)
F = fun(Word) -> Pid ! {Word, 1} end,
lib_misc:foreachWordInFile(File,F).
count_words(Key, Vals, A)->
[{length(Vals), Key}|A]运行的时候,代码目录里有102个Erlang模块,因此mapreduce也就创建了102个并发进程,它们每一个都向归并进程发送由键值对组成的数据流。这在100个核心处理上应该运行得很好(如果硬盘跟得上的话)。
现在我们已经明白mapreduce是怎么回事了,可以回到索引引擎了。?
?2.全文搜索
建立索引时,一件必须要做的事情就是找出一个文件中出现的所有单词。我们在“映射-归并”算法的“映射”阶段会用到这一点。
在此之前,我们先来看看在全文检索当中会用到的数据结构。
?1.反向索引
我们的全文检索通过反向索引来实现,在本小节中,我们需要回顾反向索引的概念,并了解它是如何存储在文件系统当中的。
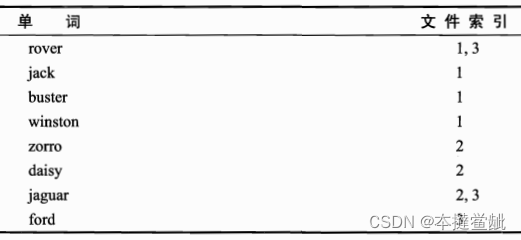
为了向你展现这个进化过程,我们先从一个简单的例子开始。假设文件系统中有3个文件,每个文件都包含一些单词。
我们的文件及其内容如表所示。
?
为了建立反向索引,我们对这些文件编号

然后建立一个词表,将单词与出现的文件索引进行对照
2.反向索引的查询?
一旦建立了反向索引,查询就是一件相当简单的事情了。比如,我们想找buster这个词,它出现在编号为1的文件中,名为/home/dogs,而查询rover AND jaguar,我们可以先查出rover (结果为文件1和文件3),再查出jaguar(结果为文件2和文件3),然后对这两个结果取交集(结果是文件3),也就是/home/cars这个文件。
3.反向索引的数据结构
我们需要两个持久的数据结构。
1. 文件名一索引对应表。在反向索引中,文件名是用整数来表示的。比如说,一个常见的词可能会在成千上万的文件中出现,使用整数来表示文件名,简化了表示形式,能大大节约空间。我们会用一个DETS表来存储这些信息。
2.?单词-文件索引表。对于每一个出现在文件之中的单词,都需要记录这个文件的索引号。这里使用文件系统来实现这个数据结构。在我们的例子中,可以创建名为rover、buster等这样的文件。索引器程序把这些单词保存在某个索引目录中。例如,如果索引目录是/user/index,我们可以在这个索引目录下找到名为buster的文件,这个索引目录包含这些文件的索引。
?3.索引器的操作
通过调用index:start()开始所有的操作
start() ->
indexer_server:start(output_dir()),
spawn_link(fun() -> worker() end).?它做了两件事,其一,它启动一个名为indexer_server的服务器进程(这是一个用gen_server写成的服务器进程),其二,它启动了一个worker进程来执行索引动作。
worker()->
possibly_stop()
case indexer_server:next_dir() of
{ok,Dir} ->
Files = indexer_misc:files_in_dir(Dir),
index_these_files(Files),
indexer_server:checkpoint(),
possibly_stop(),
sleep(10000),
worker();
done ->
true
end.woker进程做了下面这些事情。
(1)调用indexer_server:next_dir(),它会返回下一个需要索引的目录。
(2)调用index_misc:fires_in_dir来查找目录下需要进行索引的文件。
(3)调用index_these_files(Files)来对这些文件进行索引。
(4)调用indexer_server:checkpoint(),这与异常恢复有关。每次索引完成一个新的目录,程序都会告诉服务器进程我们已经做完了对于这个目录的索引。如果这个程序异常退出或被停止重启,下一次调用indexer_server:next_dir()时会从上次调用的目录处恢复,继续进行。
每一个索引的周期结束,worker都会调用possibly_stop()以检查是否需要停止。如若没有,它会休眠一段时间,然后进入下一个周期。
实际的索引操作在index_these_files之中,这里就是我们要使用“映射一归并”算法来实现并行的地方。?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一文带你掌握ThinkPHP6中的数据验证技巧,提升开发效率!
- 《计算机网络管理》第四章 管理信息库思维导图
- Vue 3 hooks的基本使用及疑问
- 校园跑腿系统(JSP+java+springmvc+mysql+MyBatis)
- CloudBeaver Enterprise安装说明
- 几种常见的CSS三栏布局?介绍下粘性布局(sticky)?自适应布局?左边宽度固定,右边自适应?两种以上方式实现已知或者未知宽度的垂直水平居中?
- ------- 计算机网络基础
- 分层自动化测试的实战思考!
- LeetCode 2125. 银行中的激光束数量【数组,遍历】1280
- WorkPlus企业内部即时通信新选择,打造高效协作新格局