如何写好大模型提示词?来自大赛冠军的经验分享(进阶篇)
编者按:近期,如何通过 Prompt Engineering 最大程度发挥大模型的潜力已成为一个热点话题。人们越来越关注如何通过 Prompt Engineering 技术低成本地用好大模型。
今天我们推荐的这篇文章,作者认为 Prompt Engineering 需要结合艺术与科学,需要在理解技术背景的同时,发挥创造力和战略思维。
本系列文章详细介绍了作者在新加坡首届 GPT-4 Prompt Engineering 大赛中使用的策略技巧,包括:使用 CO-STAR 框架构建提示语、使用分隔符明确语义单元、利用system prompts 添加行为约束、仅依靠GPT-4对数据集进行分析等。这些技巧都得到了实例验证,证明了Prompt Engineering 的重要作用。
本文属于该系列文章的第二部分,详细介绍适合进阶使用的 Prompt Engineering 高级策略。
作者 |?Sheila Teo
编译?|?岳扬
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
上个月,我有幸获得新加坡首届 GPT-4 提示工程(Prompt Engineering)大赛相关奖项,该比赛由新加坡政府科技署(GovTech)组织,汇聚了超过 400?位优秀的参与者。
提示工程(Prompt Engineering)是一门融合了艺术和科学的学科——这门学科不仅需要理解技术,还需要一定的创造力和战略思维。 以下是我在学习过程中学到的提示工程(Prompt Engineering)策略汇编,这些策略可以驱动任何大语言模型(LLM)精准执行需求,甚至超常发挥!
作者注:
在撰写本文时,我力图摒弃已在网上广泛讨论和记录的传统提示工程(Prompt Engineering)技术。相反,撰写本文的目的是给大家介绍我在实验中学到的新见解,以及对某些技术的不同理解。希望你会喜欢阅读这篇文章!
本系列文章包括以下内容,其中🔵指的是适合初学者的提示语(prompt)技巧(见基础篇),而🔴指的是高级策略(本文的重点):
1.[🔵] 使用?CO-STAR?框架构建提示语
2.[🔵]?使用分隔符(delimiters)将提示语分段
3.[🔴]?使用?LLM guardrails?创建?system prompts(译者注:“guardrails”?指的是一种保护机制或限制,用于确保大语言模型生成的内容符合特定标准或要求,防止产生不准确、不合适或有害的信息。)
4.[🔴]?仅使用?LLM(无需插件或代码)分析数据集——将介绍一个使用?GPT-4?分析真实?Kaggle?数据集的实践示例
01 [🔴]?使用?LLM guardrails?创建?system prompts
在进入正题之前,需要注意的是本节只适用于具有 System Prompt 功能的 LLM,而不像基础篇和本文的其他章节那样适用于任何 LLM。最著名的 LLM 当然是?ChatGPT ,因此在本节中我们将以 ChatGPT 作为示例。
1.1 围绕?System Prompt?的术语
首先,让我们来理清术语,特别是关于 ChatGPT 的三种术语的使用:这三种术语在 ChatGPT 几乎可以互换使用:?“System Prompts”、"System Messages "和?“Custom Instructions”。这让很多人(包括我在内!)感到困惑,以至于?OpenAI?特意发布了一篇文章来解释这些术语。以下是其摘要:
- "System Prompts"和"System Messages"是通过 Chat Completions API 以编程方式与 ChatGPT 进行交互时使用的术语。
- 另一方面,"Custom Instructions"是通过 https://chat.openai.com/? 用户界面与 ChatGPT 交互时使用的术语。
Image from Enterprise DNA Blog
不过总的来说,这三个术语指的是同一件事,所以不要被这些术语混淆了!后续部分,本文将使用?"System Prompts"一词。现在,让我们进入正题!
1.2 什么是 System Prompts ?
System Prompts 是一种额外的提示语(prompt),我们可以在其中提供有关 LLM 行为方式的instructions。它被认为是额外的提示语(prompt),因为它不属于您给 LLM 的?“正常”?提示语(即 User Prompts)。
在聊天中,每当您给 LLM 发送新的提示语(prompt)时,System Prompts 都会像过滤器一样,LLM 会在回答您的新提示语(prompt)之前自动应用这些提示语(prompt)。这意味着 System Prompts 在 LLM 做出回答时都会被考虑进去。
1.3 何时使用 System Prompt ?
您心中可能会想到的第一个问题是:为什么我应该在 System Prompts 中提供 instruction,而不是在我向与 LLM 的新对话的第一个提示语(prompt)中提供 instruction,然后再与 LLM 进行更多的对话呢?
答案是,因为 LLM 的对话记忆是有限的。在后一种情况下,随着对话的继续,LLM 很可能会"忘记"您在聊天中提供的第一条提示语(prompt),从而使这些 instruction (指令)过时。
另一方面,如果在 System Prompts 中提供了 instruction (指令),那么这些 System Prompts ?会与聊天中提供的每个新提示语一起发送。这可以确保 LLM 在聊天过程中继续接收这些 instruction,无论聊天过程变得多长。
总结:
在整个聊天过程中,使用 System Prompts 提供您希望 LLM 在回答时记住的 instruction 。
1.4 System Prompt 应包括哪些内容?
System Prompt 通常应包括以下类别的 instruction :
- 目标任务的定义(Task definition) ,这样 LLM 在整个对话过程中都会记住它必须做什么。
- 输出格式(Output format) ,这样 LLM 在整个对话过程中都会记住它应该如何做出回答。
- 防范措施(Guardrails) ,这样 LLM 在整个对话过程中都会记住它不应该如何做出回答。Guardrails 是 LLM governance 中的新兴领域,指的是 LLM 被允许操作的行为边界。
例如,System Prompt 可能是这样的:
You will answer questions using this text:?[insert text].
You will respond with a JSON object in this format:?{“Question”:?“Answer”}.
If the text does not contain sufficient information to answer the question,?do not make up information and give the answer as?“NA”.
You are only allowed to answer questions related to?[insert scope].?Never answer any questions related to demographic information such as age,?gender,?and religion.
各部分内容涉及的类别如下:

Breaking down a System Prompt?—?Image by author
1.5 但是,"正常"的聊天提示语又是什么呢?
现在你可能会想:听起来 System Prompt 中已经提供了很多信息。那我应该在聊天的"正常"提示语(即User Prompts)中写些什么呢?
System Prompt概述了当前的一般任务。在上面的 System Prompt 示例中,任务已被定义为只使用一段特定的文本来回答问题,并且 LLM 被指示以{“Question”:?“Answer”}的格式进行回答。
You will answer questions using this text:?[insert text].
You will respond with a JSON object in this format:?{“Question”:?“Answer”}.
在这种情况下,聊天过程中的每个 User Prompt 都将简化为你希望 LLM 用文本回答的问题。例如,某个用户的提问可能是“这段文本是关于什么的?(What is the text about?)”然后 LLM 会回答说?{“这段文本是关于什么的?(What is the text about?)”:?“这段文本是关于……(The text is about…)”}。
但是,让我们进一步概括这个任务示例。在这种情况下,我们可以将上述 System Prompt ?的第一行从:
You will answer questions using this text:?[insert text].
编辑为:
You will answer questions using the provided text.
现在,每个用户在聊天时的提示语(prompt)将包括进行问题回答的文本和要回答的问题,例如:
<text>
[insert text]
</text>
<question>
[insert question]
</question>
在这里,还将使用 XML 标签作为分隔符,以便以结构化的方式向 LLM 提供所需的两个信息片段。XML 标签中使用的名词“text”和“question”与 System Prompt 中使用的名词相对应,这样 LLM 就能理解标签与 System Prompt instructions之间的关系。
总之, System Prompt 应给出总体任务 instructions,而每个 User Prompt 应提供任务执行的具体细节。例如,在本例中,这些具体的细节是 text 和 question。
1.6 LLM guardrails?动态化
上面通过 System Prompt 中的几句话添加了 guardrails 。这些 guardrails 会被固定下来,在整个聊天过程中都不会改变。但是如果您希望在对话的不同阶段设置不同的 guardrails ,该怎么办?
对于使用 ChatGPT Web 界面的用户来说,目前还没有直接的方法来做到这一点。不过,如果您正在通过编程方式与 ChatGPT 进行交互,那你就走运了!随着人们对构建有效的 LLM guardrail 的关注度越来越高,一些开源软件包也应运而生,它们可以让你以编程方式设置更详细、更动态的guardrail。
其中值得注意的是英伟达团队开发的?NeMo Guardrails[1],它允许您配置用户和 LLM 之间预期的对话流程,从而在聊天的不同时间点设置不同的 guardrail ,实现随着聊天进展而不断演变的动态 guardrails 。我强烈推荐您去了解一下!
02 [🔴]?仅使用?LLM(无需插件或代码)分析数据集
您可能已经听说过 OpenAI 在 ChatGPT 的 GPT-4 中推出的高级数据分析插件,该插件仅高级(付费)账户可以使用。它允许用户将数据集上传到 ChatGPT,并直接在数据集上运行代码,从而进行精确的数据分析。
但你知道吗,使用 LLM 分析数据集并不一定需要这样的插件?让我们先来了解一下单纯使用 LLMs 分析数据集的优势和局限性。
2.1 大语言模型不擅长的数据集分析类型
正如您可能已经知道的那样,LLM 在进行精确数学计算方面的能力有限,因此它们不适合完成需要对数据集进行精确定量分析的任务,比如:
- 描述性统计(Descriptive Statistics) :通过诸如均值或方差的测量来定量总结数值列。
- 相关性分析(Correlation Analysis) :获取列之间精确的相关系数。
- 统计分析(Statistical Analysis) :比如假设检验(hypothesis testing),以确定各组数据点之间是否存在统计意义上的显著差异。
- 机器学习(Machine Learning) :在数据集上执行预测建模,比如使用线性回归(linear regressions)、梯度提升树(gradient boosted trees)或神经网络(neural networks)。
方便在数据集上执行这些定量任务正是 OpenAI 推出高级数据分析插件的原因,这样编程语言就可以在数据集上运行代码来执行此类任务。
那么,为什么有人只想使用 LLM 而不使用此类插件来分析数据集呢?
2.2 大语言模型擅长的数据集分析类型
LLM 非常擅长识别模式和趋势(patterns and trends)。这种能力源自它们在多样化和海量数据上的广泛训练,使它们能够识别那些可能无法立即察觉的复杂模式。
这使它们非常适合执行基于数据集进行模式识别的任务,例如:
- 异常检测(Anomaly detection) :基于一列或多列的数值,识别偏离常规的异常数据点。
- 聚类(Clustering) :将具有相似特征的数据点分组。
- 跨列关系(Cross-Column Relationships) :通过分析不同列之间的关系,可以揭示数据中的复杂模式和趋势。
- 文本分析(Textual Analysis)(针对基于文本的列) :基于主题或情感进行分类。
- 趋势分析(Trend Analysis)(针对具有时间特征的数据集) :识别列中跨时间的模式、季节性变化或趋势。
对于这类基于模式的任务,单独使用 LLM 可能会比使用代码在更短的时间内获得更好的结果!让我们用一个例子来充分说明这一点。
2.3 仅使用?LLM?分析?Kaggle?数据集
我们将使用一个广受欢迎的真实?Kaggle?数据集[2],该数据集专为进行客户人格分析而准备,其中一家公司试图对其客户群体进行细分,以便更好地了解其客户。
为了便于之后验证 LLM 的分析结果,我们取该数据集的 50?行为一个子集,并只保留最相关的列。之后,用于分析的数据集将如下所示,其中每一行代表一位客户,每一列描述客户信息:

First 3 rows of dataset?—?Image by author
假设你在公司的营销团队工作。你的任务是利用这些客户信息数据集来指导营销工作。这是一项分两步走的任务:首先,利用数据集划分多个具有实际意义的客户细分群体。接下来,提出如何最好地针对每个客户群体进行创意营销。现在,这是一个实际的商业问题,LLM 的模式发现(pattern-finding,对于步骤 1 )能力在这个问题上确实可以大显身手。
让我们按照以下方式为这个任务制定提示语(prompt),将使用?4?种?prompt engineering?技术(后续会详细介绍[3]):
1. 将复杂的任务分解为简单的步骤
2. 参考每个步骤的中间输出
3. 格式化LLM的回答
4. 将?instructions?与数据集分开
System Prompt:
I want you to act as a data scientist to analyze datasets.?Do not make up information that is not in the dataset.?For each analysis I ask for,?provide me with the exact and definitive answer and do not provide me with code or instructions to do the analysis on other platforms.
Prompt:
#?CONTEXT?#
I sell wine.?I have a dataset of information on my customers:?[year of birth,?marital status,?income,?number of children,?days since last purchase,?amount spent].
#############
#?OBJECTIVE?#
I want you use the dataset to cluster my customers into groups and then give me ideas on how to target my marketing efforts towards each group.?Use this step-by-step process and do not use code:
1.?CLUSTERS:?Use the columns of the dataset to cluster the rows of the dataset,?such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values.?Ensure that each row only belongs to 1 cluster.
For each cluster found,
2.?CLUSTER_INFORMATION:?Describe the cluster in terms of the dataset columns.
3.?CLUSTER_NAME:?Interpret?[CLUSTER_INFORMATION]?to obtain a short name for the customer group in this cluster.
4.?MARKETING_IDEAS:?Generate ideas to market my product to this customer group.
5.?RATIONALE:?Explain why?[MARKETING_IDEAS]?is relevant and effective for this customer group.
#############
#?STYLE?#
Business analytics report
#############
#?TONE?#
Professional,?technical
#############
#?AUDIENCE?#
My business partners.?Convince them that your marketing strategy is well thought-out and fully backed by data.
#############
#?RESPONSE:?MARKDOWN REPORT?#
<For each cluster in?[CLUSTERS]>
—?Customer Group:?[CLUSTER_NAME]
—?Profile:?[CLUSTER_INFORMATION]
—?Marketing Ideas:?[MARKETING_IDEAS]
—?Rationale:?[RATIONALE]
<Annex>
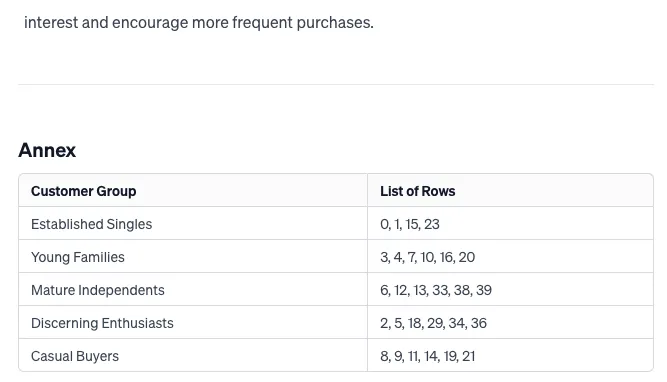
Give a table of the list of row numbers belonging to each cluster,?in order to back up your analysis.?Use these table headers:?[[CLUSTER_NAME],?List of Rows].
#############
#?START ANALYSIS?#
If you understand,?ask me for my dataset.
GPT-4的回答如下,接下来我们将数据集以CSV字符串的形式传递给它。

GPT-4’s response?—?Image by author
随后,GPT-4 将按照我们要求的 markdown 格式回复分析结果:

GPT-4’s response?—?Image by author

GPT-4’s response?—?Image by author
GPT-4’s response?—?Image by author
2.4 验证?LLM?的分析结果
为了简洁起见,我们将挑选 LLM 生成的 2 个客户群体进行验证,比如 Young Families 和Discerning Enthusiasts。
2.4.1 Young Families
- LLM 总结的该人群特征:1980年后出生,已婚或同居,收入中等偏低,有孩子,经常进行小额购买。
- LLM 将数据集中的这些行聚类到了 Young Families 这个群体中:3、4、7、10、16、20
深入数据集,这些行的完整数据如下:

Full data for Young Families?—?Image by author
LLM 识别出的这部分客户资料,确实对应于所识别的客户群体。甚至能够在我们事先未经过预处理的情况下对具有空值的资料进行聚类!
2.4.2 Discerning Enthusiasts
- LLM 总结的该人群特征:年龄跨度广,可能是任何婚姻状况,高收入,子女状况各异,购买支出高。
- LLM 认为该人群对应的数据行:2、5、18、29、34、36
深入数据集,这些行的完整数据如下:

Full data for Discerning Enthusiasts?—?Image by author
再次与 LLM 识别出的人群资料非常吻合!
这个例子展示了 LLM 在发现模式、解释和提炼多维数据集,并将其提炼为有意义的见解方面的能力,同时确保其分析深深扎根于数据集的事实。
2.5 如果我们使用ChatGPT的高级数据分析插件会怎样呢?
为了保证分析的完整性,我尝试使用相同的提示语(prompt),并请求 ChatGPT 使用代码执行相同的分析,这就激活了它的高级数据分析插件。这个想法是让插件直接在数据集上运行 K-Means 等聚类算法的代码,以获得各个用户群体的特征,然后综合每个群体的数据来提供营销策略。
然而,尽管数据集只有 50?行,进行了多次尝试都导致出现以下错误信息而没有任何输出:

Error and no output from Attempt 1?—?Image by author

Error and no output from Attempt 2?—?Image by author
现在使用高级数据分析插件,在数据集上执行较简单的任务(如计算描述性统计数据或创建图表)似乎很容易实现,但需要某些计算算法的较高级任务有时可能会由于计算限制或其他原因导致错误或无输出。
2.6 那么…何时使用 LLM 分析数据集?
答案是取决于分析的数据类型。
对于需要精确数学计算或复杂的、基于规则处理的任务,传统的编程方法仍然更胜一筹。
对于基于模式识别(pattern-recognition)的任务,使用传统的编程或算法方式可能比较具有挑战性或更耗时。然而,LLM 擅长此类任务,甚至可以提供额外的内容输出,比如用来支持其分析的附件和 Markdown 格式的完整分析报告。
归根结底,是否使用 LLM 取决于手头任务的性质,要在 LLM 在模式识别方面的优势与传统编程技术提供的精确性和特异性之间取得平衡。
2.7 现在回到提示工程(prompt engineering)!
在本节结束之前,让我们回顾一下用于生成此数据集分析的提示语(prompt),并分解所使用的 prompt engineering 关键技术。
Prompt:
#?CONTEXT?#
I sell wine.?I have a dataset of information on my customers:?[year of birth,?marital status,?income,?number of children,?days since last purchase,?amount spent].
#############
#?OBJECTIVE?#
I want you use the dataset to cluster my customers into groups and then give me ideas on how to target my marketing efforts towards each group.?Use this step-by-step process and do not use code:
1.?CLUSTERS:?Use the columns of the dataset to cluster the rows of the dataset,?such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values.?Ensure that each row only belongs to 1 cluster.
For each cluster found,
2.?CLUSTER_INFORMATION:?Describe the cluster in terms of the dataset columns.
3.?CLUSTER_NAME:?Interpret?[CLUSTER_INFORMATION]?to obtain a short name for the customer group in this cluster.
4.?MARKETING_IDEAS:?Generate ideas to market my product to this customer group.
5.?RATIONALE:?Explain why?[MARKETING_IDEAS]?is relevant and effective for this customer group.
#############
#?STYLE?#
Business analytics report
#############
#?TONE?#
Professional,?technical
#############
#?AUDIENCE?#
My business partners.?Convince them that your marketing strategy is well thought-out and fully backed by data.
#############
#?RESPONSE:?MARKDOWN REPORT?#
<For each cluster in?[CLUSTERS]>
—?Customer Group:?[CLUSTER_NAME]
—?Profile:?[CLUSTER_INFORMATION]
—?Marketing Ideas:?[MARKETING_IDEAS]
—?Rationale:?[RATIONALE]
<Annex>
Give a table of the list of row numbers belonging to each cluster,?in order to back up your analysis.?Use these table headers:?[[CLUSTER_NAME],?List of Rows].
#############
#?START ANALYSIS?#
If you understand,?ask me for my dataset.
技巧 1:将复杂任务分解为简单步骤
LLM 擅长执行简单任务,但在复杂任务上表现一般。因此,对于像这样的复杂任务,重要的是要把任务分解成简单的步骤说明,让 LLM 遵循。 这样做的目的是向 LLM 提供你自己执行任务时会采取的步骤。
在本例中,步骤如下:
Use this step-by-step process and do not use code:
1.?CLUSTERS:?Use the columns of the dataset to cluster the rows of the dataset,?such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values.?Ensure that each row only belongs to 1 cluster.
For each cluster found,
2.?CLUSTER_INFORMATION:?Describe the cluster in terms of the dataset columns.
3.?CLUSTER_NAME:?Interpret?[CLUSTER_INFORMATION]?to obtain a short name for the customer group in this cluster.
4.?MARKETING_IDEAS:?Generate ideas to market my product to this customer group.
5.?RATIONALE:?Explain why?[MARKETING_IDEAS]?is relevant and effective for this customer group.
与简单地将整体任务交给 LLM 相比,例如“将客户分组,然后提出针对每个群体的营销策略”。通过逐步说明,LLM 更有可能提供正确的结果。
技巧 2:引用每个步骤的中间输出
在向 LLM 提供逐步说明时,可将每个步骤的中间输出命名为大写的变量名,例如CLUSTERS、CLUSTER_INFORMATION、CLUSTER_NAME、MARKETING_IDEAS和RATIONALE。
使用大写字母是为了将这些变量名与给出的 instructions 内容区分开。稍后可以使用方括号引用这些中间输出,如[VARIABLE_NAME]。
技巧 3:规范大模型回答的格式
在这里,要求使用 Markdown 报告格式,以美化 LLM 的回答。在这里,中间输出中的变量名又派上了用场,可以决定报告的结构。
#?RESPONSE:?MARKDOWN REPORT?#
<For each cluster in?[CLUSTERS]>
—?Customer Group:?[CLUSTER_NAME]
—?Profile:?[CLUSTER_INFORMATION]
—?Marketing Ideas:?[MARKETING_IDEAS]
—?Rationale:?[RATIONALE]
<Annex>
Give a table of the list of row numbers belonging to each cluster,?in order to back up your analysis.?Use these table headers:?[[CLUSTER_NAME],?List of Rows].
事实上,您甚至可以随后要求 ChatGPT 将报告提供为可下载文件,这样您就可以根据其回答来撰写最终的报告文档。
Saving GPT-4’s response as a file?—?Image by author
技巧4:将任务说明与数据集分开
您会注意到我们在第一个提示语中并没有将数据集提供给LLM。相反,提示语只包含了数据集分析的任务说明,并在最后加上了以下内容:
#?START ANALYSIS?#
If you understand,?ask me for my dataset.
ChatGPT 随后回复说它理解了,我们将在下一个提示语中将数据集作为 CSV 字符串传递给它:

GPT-4’s response?—?Image by author
但为什么要将 instructions 与数据集分开呢?
简单明了的答案是,LLM 的上下文窗口存在限制,即在一句提示语中可以输入的tokens数量存在限制。同时包含 instructions 和数据的长提示语(long prompt)可能会超过这个限制,从而导致截断(truncation)和信息丢失(loss of information)。
更复杂的答案是,将 instructions 和数据集分开可以帮助 LLM 保持清晰的理解,降低遗漏信息的可能性。 你可能遇到过这样的情况,即 LLM “不小心忘记了”?你发送的较长提示语给出的某个 instruction ——例如,如果你要求给出 100?字的回答,而 LLM 却给了您一个较长的段落。通过先接收 instructions ,再接收 instructions 所针对的数据集,LLM 可以先消化它应该执行的任务,然后再对接下来提供的数据集执行 instructions 。
不过请注意,只有聊天型?LLM?才能实现?instruction?和数据集的分离,因为它们会保留对话记忆,而?completion LLM?则不会(译者注:completion LLM指的是一种能够根据给定的提示语来生成完整文本或完成特定任务的语言模型。这种模型通常不具备对话记忆,而是专注于根据提示语生成连贯的文本)。
Thanks for reading!
END
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
参考资料
[1]https://github.com/NVIDIA/NeMo-Guardrails
[2]https://www.kaggle.com/datasets/imakash3011/customer-personality-analysis
[3]https://towardsdatascience.com/how-i-won-singapores-gpt-4-prompt-engineering-competition-34c195a93d41#544b
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/how-i-won-singapores-gpt-4-prompt-engineering-competition-34c195a93d41
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大型软件编程实际应用实例:个体诊所电子处方系统,使用配方模板功能输入症状就可开出处方软件操作教程
- RT-Thread 之 PIN设备驱动调试
- 程序设计语言的基本成分
- java——数据类型与变量
- 如何在 24 小时内构建 WordPress 网站
- 图解集线器、中继器、交换机、网桥、路由器、光猫到底有啥区别?
- 会计报名照片怎么压缩?这几种方法一定要会
- metinfo_6.0.0 任意文件读取漏洞复现
- 实时阴影技术(Shadow Mapping)
- webstorm中直接运行ts(TypeScript)