【Datawhale 大模型基础】第八章 分布式训练
第八章 分布式训练
As the sizes of models and data increase, efficiently training large language models under limited computational resources has become challenging. In particular, two primary technical issues need to be addressed: increasing training throughput and loading larger models into GPU memory. This blog is based on datawhale files and a nice survey.
8.1 Data parallelism
It is a fundamental method for increasing training throughput. It involves replicating the model parameters and optimizer states across multiple GPUs and then distributing the entire training corpus among these GPUs. Each GPU processes its assigned data, performing forward and backward propagation to obtain gradients. The computed gradients from different GPUs are aggregated to obtain the gradients of the entire batch for updating the models in all GPUs. This mechanism is highly scalable, allowing for an increase in the number of GPUs to improve training throughput. Additionally, it is simple to implement, and most popular deep learning libraries, such as TensorFlow and PyTorch, have already implemented data parallelism.
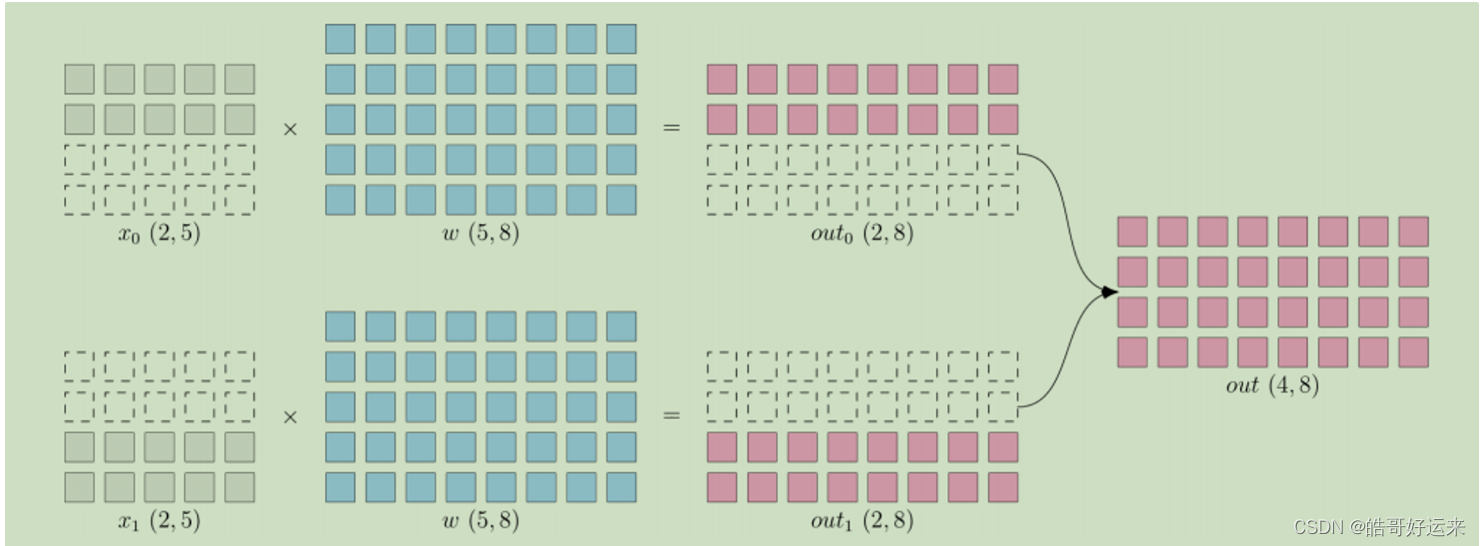
8.2 Pipeline parallelism
It aims to distribute the different layers of a LLM across multiple GPUs. For instance, in the case of a Transformer model, consecutive layers are loaded onto the same GPU to reduce the cost of transmitting computed hidden states or gradients between GPUs. However, a naive implementation of pipeline parallelism may result in a lower GPU utilization rate, as each GPU has to wait for the previous one to complete the computation, leading to unnecessary bubbles overhead.
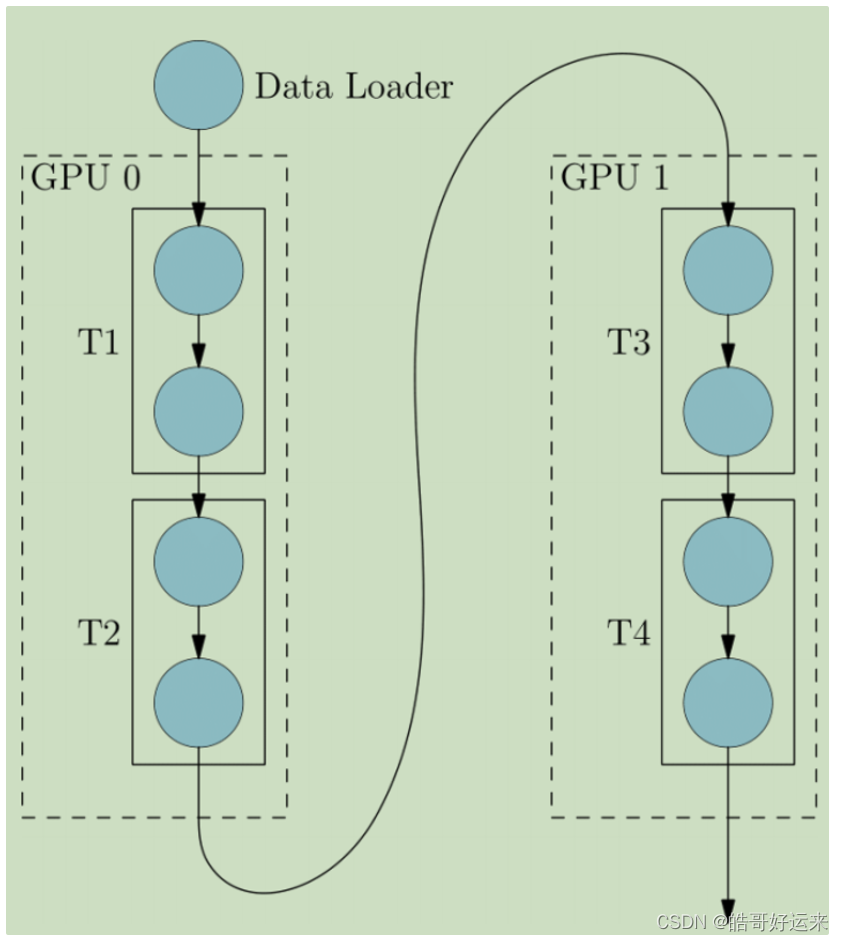
8.3 Tensor parallelism
Unlike pipeline parallelism, tensor parallelism focuses on decomposing the tensors (the parameter matrices) of LLMs. For a matrix multiplication operation Y = X A Y = XA Y=XA in the LLM, the parameter matrix A A A can be split into two submatrices, A 1 A_1 A1? and A 2 A_2 A2?, by column, resulting in Y = [ X A 1 , X A 2 ] Y = [XA_1, XA_2] Y=[XA1?,XA2?]. By placing matrices A 1 A_1 A1? and A 2 A_2 A2? on different GPUs, the matrix multiplication operation can be executed in parallel on two GPUs, and the final result can be obtained by combining the outputs from the two GPUs through inter-GPU communication.
Currently, tensor parallelism has been supported in several open-source libraries, such as Megatron-LM [75], and can be extended to higher-dimensional tensors. Additionally, Colossal-AI has implemented tensor parallelism for higher-dimensional tensors [335–337] and proposed sequence parallelism [338], especially for sequence data, which can further decompose the attention operation of the Transformer model.
8.4 ZeRO
It addresses the issue of memory redundancy in data parallelism. In data parallelism, each GPU needs to store the same copy of a LLM, including model parameters, model gradients, and optimizer parameters. However, not all of this data needs to be retained on each GPU, leading to a memory redundancy problem. To solve this, the ZeRO technique aims to retain only a fraction of the data on each GPU, while the remaining data can be retrieved from other GPUs when needed. ZeRO provides three solutions: optimizer state partitioning, gradient partitioning, and parameter partitioning, depending on how the three parts of the data are stored. Empirical results show that the first two solutions do not increase communication overhead, while the third solution increases communication overhead by about 50% but saves memory proportional to the number of GPUs. PyTorch has implemented a similar technique called FSDP.
8.5 Mixed Precision Training
It involves using 16-bit floating-point numbers (FP16) instead of the traditional 32-bit floating-point numbers (FP32) for pre-training LLMs. This reduces memory usage and communication overhead. Additionally, popular NVIDIA GPUs, such as the A100, have twice the amount of FP16 computation units as FP32, improving the computational efficiency of FP16. However, existing work has found that FP16 may lead to a loss of computational accuracy, which can affect the final model performance. To address this, an alternative called Brain Floating Point (BF16) has been used for training, allocating more exponent bits and fewer significant bits than FP16. For pre-training, BF16 generally performs better than FP16 in terms of representation accuracy.
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 网络编程 day3
- 生骨肉冻干推荐测评|希喂、VE、百利、PR等多款热门生骨肉冻干测评
- 认识 JDBC
- 【小程序】如何获取特定页面的小程序码
- OpenCV 环境变量参考
- Vuex的基础使用
- android studio导入module
- Zookeeper无法启动,报“Unable to load database on disk”
- 好书推荐丨人工智能B2B落地实战:基于云和Python的商用解决方案(清华社)
- CSIT883系统分析与项目管理——Lecture10重点概念