什么是MongoDB
概念:
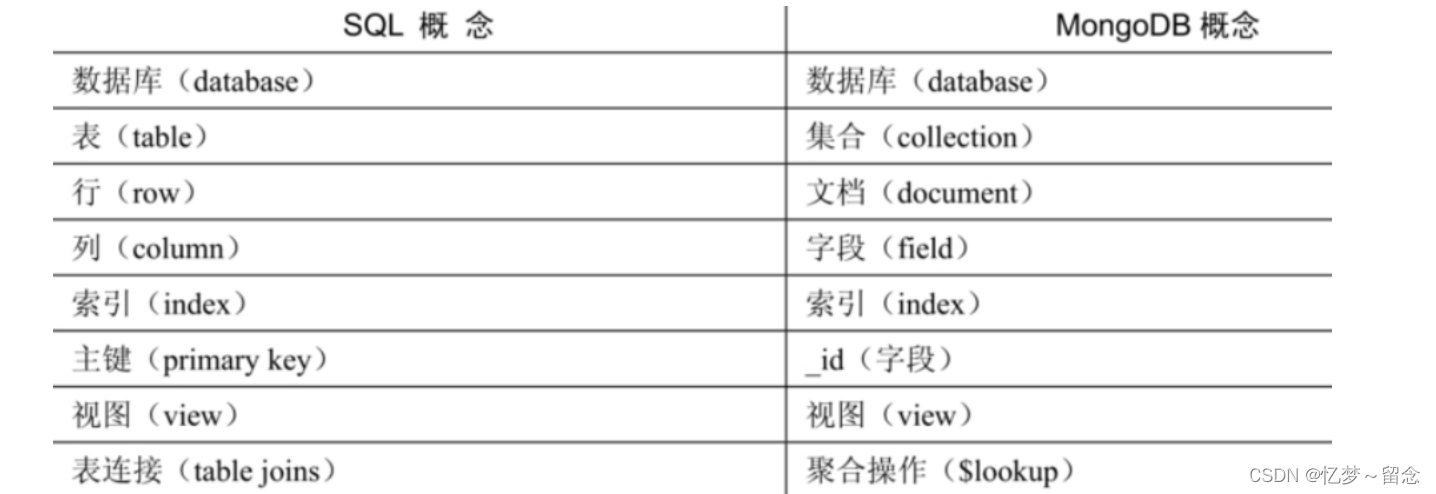
sql 与MongoDB 比较:

MongoDB特点:
优势:
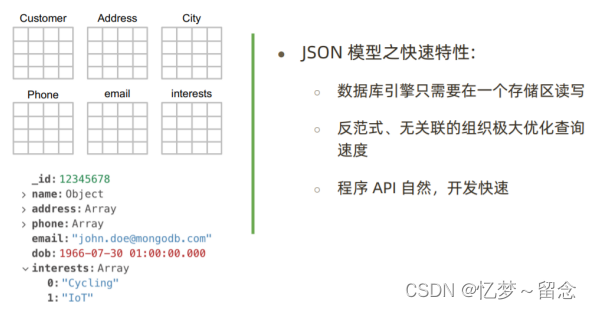
图文结合解释特点:

最简单快速的开发方式(快速)
快速响应业务变化(灵活) ?
?
原生的高可用(优势)
 ?横向扩展能力(优势)?
?横向扩展能力(优势)?
?MongoDB应用场景:
如何考虑是否选择MongoDB?

虚拟机使用
MongoDB下载
https://www.mongodb.com/try/download/community
下载压缩包

进行解压安装等操作?
 ?
?
配置
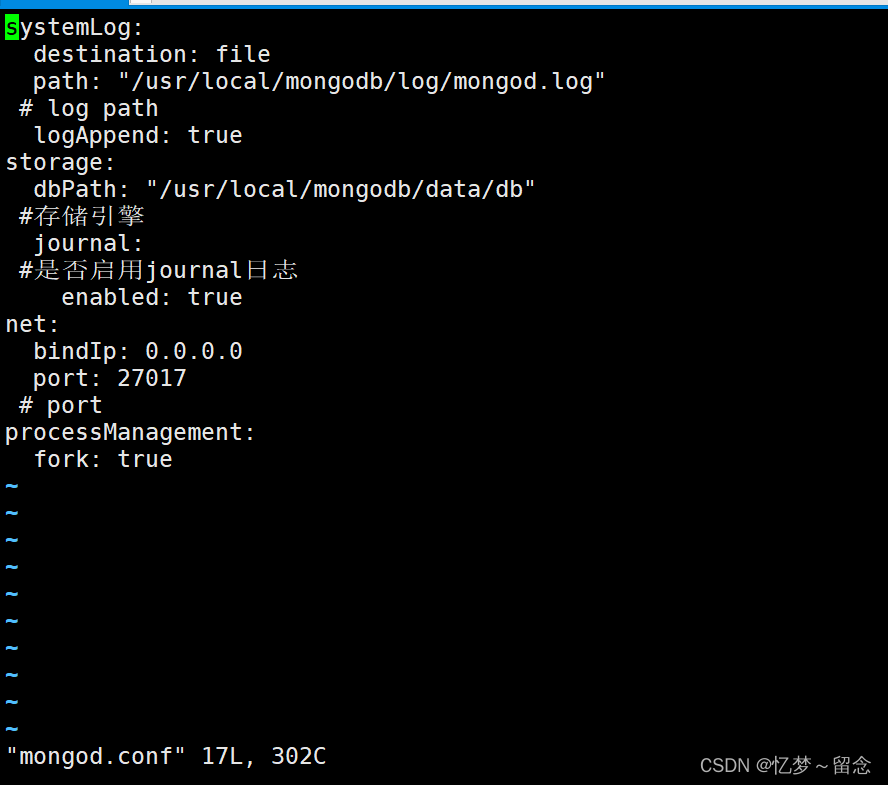
systemLog:
destination: file
path: "/usr/local/mongodb/log/mongod.log"
# log path
logAppend: true
storage:
dbPath: "/usr/local/mongodb/data/db"
#存储引擎
journal:
#是否启用journal日志
enabled: true
net:
bindIp: 0.0.0.0
port: 27017
# port
processManagement:
fork: true
启动
./bin/mongod -f ./mongod.conf成功
 查看日志是否使用
查看日志是否使用
cd log\
cat mongod.log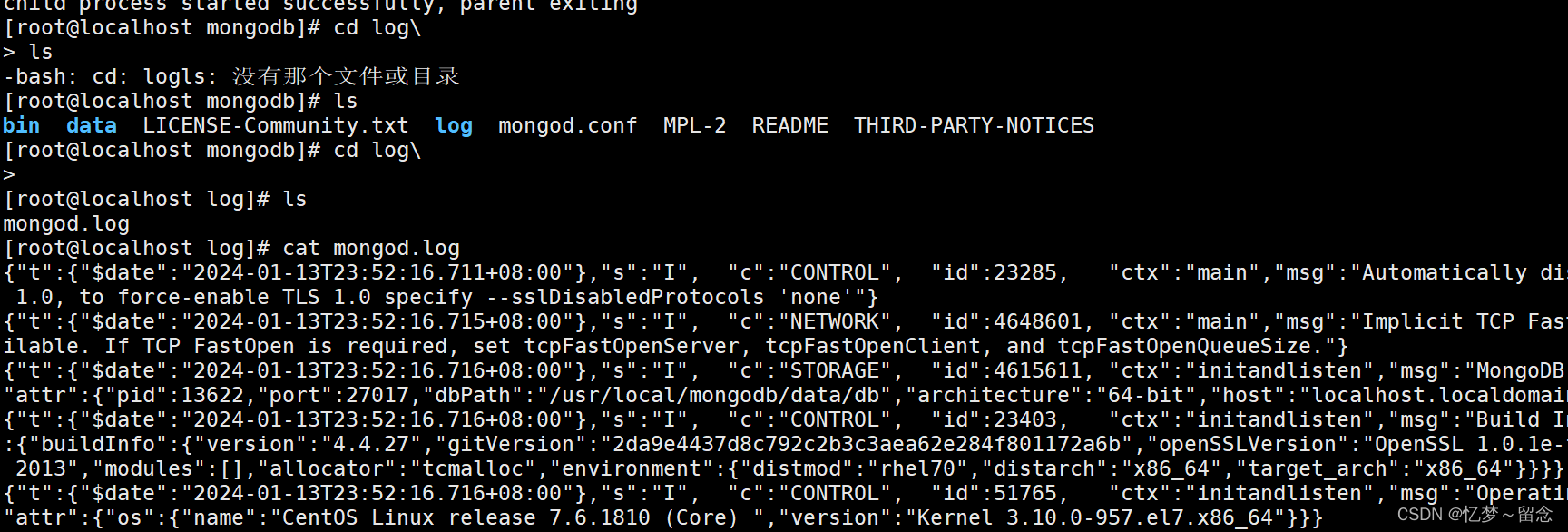
查看进程mongodb是否启动
ps -aux|grep mongod
创建启动文件

 ?关闭mongodb
?关闭mongodb
连接mongodb
./mongo --port 27017 use admin
use admin
db.shutdownServer()
关闭成功并退出

查看进程
ps -aux|grep mongod
MongoDB使用
本地window连接
黑窗口中在mongodb安装目录的bin目录下输入mongo

如果更改了端口号
mongo --port=27017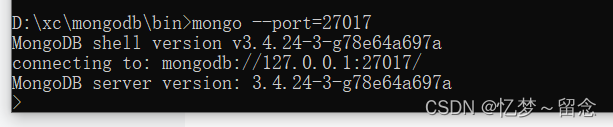
远程连接
mongo --host=127.0.0.1 --port=27017
如果连不上就关闭防火墙试试
检查防火墙
firewall-cmd --state关闭防火墙
?systemctl stop firewalld.service禁止启用
?systemctl disable firewalld.service
启动
云服务连接成功

我这用的虚拟机的也可已连接
 ?接着操作虚拟机的MongoDB
?接着操作虚拟机的MongoDB
先登录进入mongo
./bin/mongo

?指令查看数据库
show databases
show dbs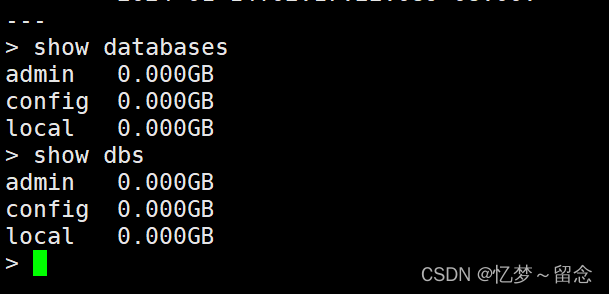
常用命令?
show dbs | show databases 显示数据库列表
use 数据库名 切换数据库,如果不存在创建数据库
db.dropDatabase() 删除数据库
show collections | show tables 显示当前数据库的集合列表
db.集合名.stats() 查看集合详情
db.集合名.drop() 删除集合
show users 显示当前数据库的用户列表
show roles 显示当前数据库的角色列表
show profile 显示最近发生的操作
load("xxx.js") 执行一个JavaScript脚本文件
exit | quit() 退出当前shell
help 查看mongodb支持哪些命令
db.help() 查询当前数据库支持的方法
db.集合名.help() 显示集合的帮助信息
db.version() 查看数据库版本?
db 查看当前数据库
db.dropDatabase() 删除当前数据库
db.createCollection("") 创建表
show tables? ? ?查看当前数据库中表
或者show collections

当库中有数据时就可以显示了
?
命令操作?
插入数据
单条数据插入
插入方法使用 insert() 或者 save() 或者 insertOne() 方法
db.集合名.insert(BSON格式文档内容)
或者
db.集合名.save(BSON格式文档内容)
或者
db.集合名.insertOne(BSON格式文档内容)-
save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
-
insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。 ?
db.student.insert({name:"张三",age:15})默认情况下,MongoDB使用 _id 字段作为主键,自动生成。如果手动指定,则使用手动指定的数据。
_id 字段类型是ObjectId,手动指定id时可以使用ObjectId,也可以使用MongoDB支持的任意类型

?批量插入
db.集合名.insertMany(
[文档1, 文档2...],
{
ordered: 指定MongoDB是否有序插入。可选值
}
)MongoDB的批量插入并不是同时成功或者同时失败。如果在插入过程中有一条数据失败,就会终止插入,但是在此之前的数据都会插入成功。

自定义插入id值
 ?同id进行修改(存在修改不存在插入)(不推荐使用)
?同id进行修改(存在修改不存在插入)(不推荐使用)


批量插入?
db.student.insertMany
(
[
{ "_id" : ObjectId("65a2db55dc4aa5e80ea4f1c0"), "name" : "张三", "age" : 15, "sex" : "男" },
{ "_id" : ObjectId("65a2dc37dc4aa5e80ea4f1c1"), "name" : "李四" },
{ "_id" : ObjectId("65a2dc64dc4aa5e80ea4f1c2"), "name" : "王二", "age" : 14 },
{ "_id" : 1, "name" : "李四" }
],
{
ordered: true
}
)
支持try catch?
插入数据较多的情况下可能会报错,可以在命令前后使用try catch进行异常捕捉
try {
db.集合名.insertMany()
} catch(e) {
print(e)
}try{
db.student.insertMany
(
[
{ "_id" : ObjectId("65a2db55dc4aa5e80ea4f1c0"), "name" : "张三", "age" : 15, "sex" : "男" },
{ "_id" : ObjectId("65a2dc37dc4aa5e80ea4f1c1"), "name" : "李四" },
{ "_id" : ObjectId("65a2dc64dc4aa5e80ea4f1c2"), "name" : "王二", "age" : 14 },
{ "_id" : 1, "name" : "李四" }
],
{
ordered: true
}
)
}catch(e)
{
print(e)
}创建集合语法
db.createCollection(name, options)?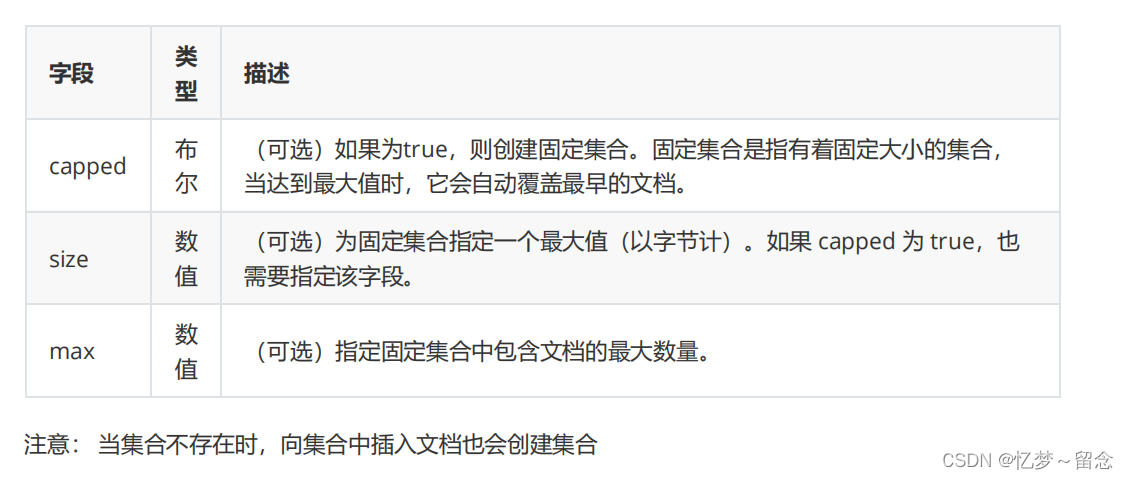
更新文档

?更新文档使用update方法
db.集合名.update(
{BSON格式查询条件},
{BSON格式要更新的内容},
{
upsert: 布尔类型,指定如果不存在update的记录,是否插入。默认false
multi: 默认false,只更新找到的第一条记录。如果为true,则更新查询条件下的所有记录
}
)覆盖修改
将符合条件 "_id":"1"的第一个文档替换为{"name":"dd","age":10}。?
db.student.update({_id:1},{"name":"dd","age":10})局部修改 ?批量修改
db.student.update({"name":"dd"},{$set:{"name":"ss","age":10}},{multi:true})$inc
db.集合名.update(
{_id: "1"},
{$inc: {age: NumberInt(1)}}
)删除文档
db.student.remove({})
2、删除符合条件的文档
db.student.remove({"name":"dd"})查询文档

db.collection.find(query,?projection)db.集合名.find(BSON格式条件)find() 或者
findOne() 方法进行
db.student.find()db.student.find({"name":"dd"})默认情况下,查询的结果是返回所有字段。这样的话性能可能会比较低。一般我们只查询需要的部分字段,就可以使用投影查询
如,只查询name, age字段
db.student.find({"name":"dd"},{name:1,age:1,_id:0})条件连接查询
AND 条件
find() 方法可以传入多个键值对,类似于SQL的AND条件
如,查询性别是男,年龄在18岁的用户
db.stdent.find({sex: "1", age: "18"})OR 条件
MongoDB提供了关键字 $or 用来实现or查询
db.集合名.find({$or: [{key1, value1}, {key2, value2}]})
AND 和 OR 联合使用 ?
db.student.find({sex: 1, $or: [{age: 27}, {age: 29}]})
统计查询
db.集合名.count(BSON格式条件)统计所有性别为男的数据
db.student.count({sex: 1})
分页查询?
使用 limit 读取指定数量的数据, skip 跳过指定数量的数据,二者搭配来进行分页查询。使用逻辑和MySql中的limit一样。
查询返回前三条记录,limit参数默认是20
db.集合.find().limit(3)跳过前3条记录,skip参数默认是0
db.集合.find().skip(3)每页查询2条数据
db.集合.find().skip(0).limit(2)
db.集合.find().skip(2).limit(2)
db.集合.find().skip(3).limit(2)
排序查询
排序查询使用 sort 方法。sort方法可以指定排序的字段,值为1升序,值为-1降序
根据性别升序排序,并根据年龄降序排序
db.student.find().sort({sex: 1, age: -1})
再进行分页,每页5条 ?
db.student.find().sort({sex: 1, age: -1}).skip(0).limit(5)
角色权限操作
查询所有角色权限(仅用户自定义角色)
db.runCommand({rolesInfo: 1})查询所有角色权限(包含内置角色)
db.runCommand({rolesInfo: 1, showBuiltinRoles: true})查询当前数据库中指定角色的权限
db.runCommand({rolesInfo: 角色名})查询其他数据库中指定的角色权限
db.runCommand({rolesInfo: {role: 角色名, db: 数据库名}})查询多个角色权限
db.runCommand({rolesInfo: [角色名...., {role: 角色名, db: 数据库名}]})常见角色

安全认证
?关闭数据库
mongo --port 27017
use admin
db.shutdownServer()添加用户和权限
./usr/local/mongodb/bin/mongod -f ./usr/local/mongod.conf登录数据库
./usr/local/mongodb/bin/mongo根据实际路径合理操作
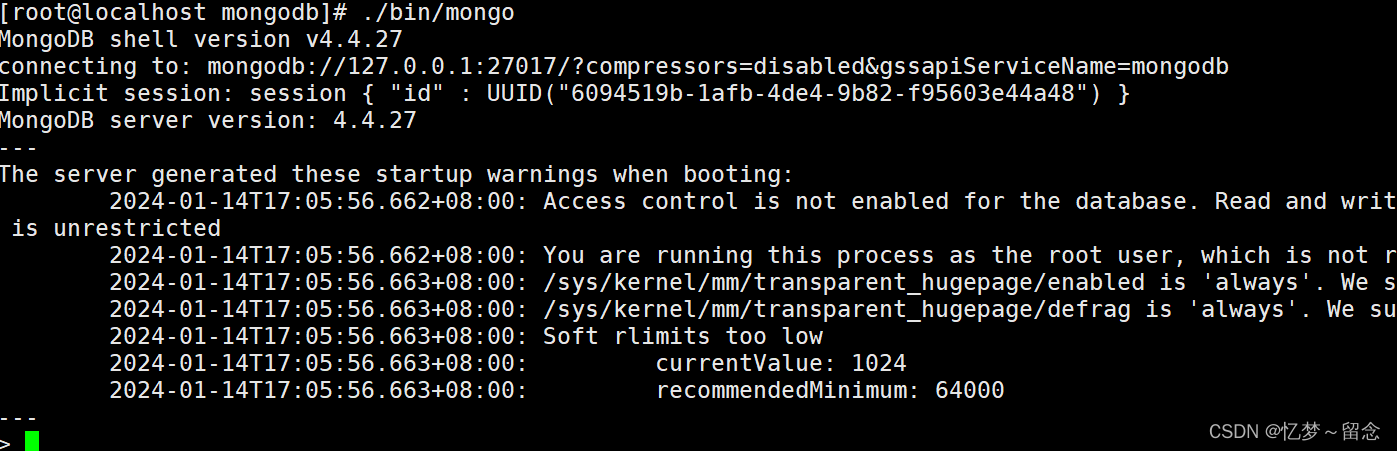
创建系统超级管理员mongoroot和admin数据库的管理用户mongoadmin
# 切到admin
use admin
# 创建系统超级用户mongoroot,密码123456,角色root
db.createUser({user: "mongoroot", pwd: "123456", roles: ["root"]})
# 创建admin库的管理员
db.createUser({user: "mongoadmin",pwd: "123456", "roles": [{role: "userAdminAnyDatabase", db:"admin"}]})
# 查看已经创建的用户
db.system.users.find()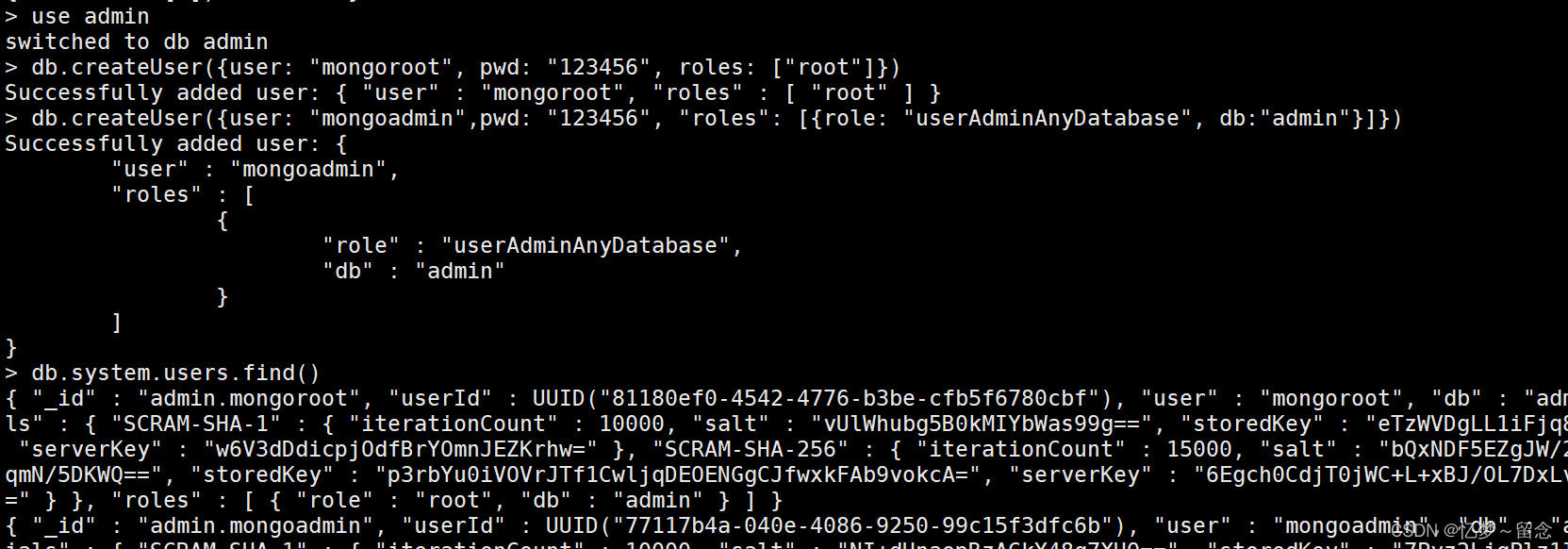
MongoDB默认把用户信息存放到 admin 数据库的 system.users 表中
创建用户如果不指定数据库,则创建的用户在所有数据库上有效
认证测试
先关闭数据库
use admin
db.shutdownServer()重新启动mongodb,开启认证
参数方式
./usr/local/mongodb/bin/mongod -f ./mongodb/mongod.conf --auth根据目录合理操作
我这目录位置

./bin/mongod -f ./mongod.conf --auth
配置文件方式
编辑配置文件
vi /mongodb/mongof.confsecurity:
#开启授权认证
authorization: enabled正常启动
./usr/local/mongodb/bin/mongod -f ./mongodb/mongod.conf?我这里
./bin/mongod -f ./mongod.conf连接时认证
/usr/local/mongodb/bin/mongo --host 127.0.0.1 --authenticationDatabase=admin --port 27017 -u mongoroot -p 123456-u 用户名
-p 密码
-- authenticationDatabase:指定要登录的数据库
我用的

./bin/mongo --host 192.168.80.100 --authenticationDatabase=admin --port 27017 -u mongoroot -p 123456暴力关闭数据库补救
暴力关闭数据库
ps -aux|grep monogodb
kill -9 进程号暴力关闭后,可能会存在数据的损坏,导致mongodb无法启动,可以通过下面的操作恢复
删除lock文件
rm -f /mongodb/data/db/*.lock修复数据
/usr/local/mongodb/bin/mongod --repair --dbpath=/mongodb/data/db索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文档并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
MongoDB中使用 B树 数据结构存储索引,B树在本次课程中不作讲解。
索引分类
单字段索引
MongoDB支持在文档单个字段上创建用户定义的升序/降序索引,称之为 单字段索引
复合索引
MongoDB还支持多个字段的索引,称之为 复合索引
复合索引中对字段顺序也有要求,如果复合索引是由 {age: 1, sex: -1} 组成,就会先按照age正序排序,再按照sex倒序排序
地理空间索引
为了支持对地理坐标的有效查询,MongoDB提供了二维索引和二维球面索引
文本索引
MongoDB提供了文本索引,支持在集合中搜索字符串内容。
?哈希索引
为了支持散列的分片,MongoDB提供了散列索引,它对字段值的散列进行索引。哈希索引只支持 = 条件查询,不支持范围查询。
索引操作
创建索引
单字段索引:对 age 字段建立索引 ?
db.student.createIndex({age: 1})复合索引:对 age 和 sex 同时创建复合索引
db.student.createIndex({age: 1, sex: -1})
查看索引
返回一个集合中所有的索引
db.集合名.getIndexes()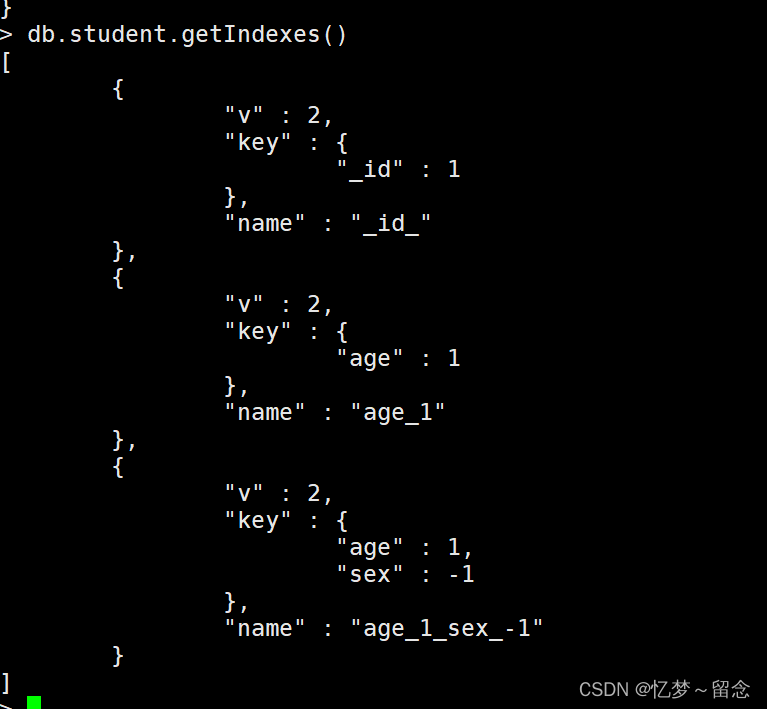
其中,_id 是默认的索引。
MongoDB在创建集合的过程中,在_id字段上创建一个唯一的索引,名称为 _id_ ,该索引可以防止客户端插入两个具有相同值的文档,该索引不可以被删除。
?查看看集合索引大小
db.集合名.totalIndexSize()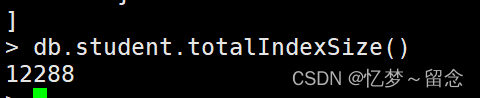
删除索引
删除指定索引
db.集合名.dropIndex(索引名称或索引键值对)如删除age上的升序索引
db.student.dropIndex({age: 1})
或者
db.student.dropIndex("age_1")删除所有索引
db.集合名.dropIndexes()该方法并不会将_id索引删除,只能删除_id之外的索引
查询分析
MongoDB 查询分析可以确保我们所建立的索引是否有效。
查询分析常用的方法是 explain()
explain 操作提供了查询信息、使用索引、查询统计等,有利于我们对索引的优化。
先在user中创建age和sex索引
db.student.createIndex({age: 1, sex: 1})
再使用explain对查询进行分析
db.student.find({age: 18, sex: 1, _id: 1}).explain()
stage:当值为 COLLSCAN 时,表示全集合扫描,这样的性能是比较低的。当值为 IXSCAN 时,是基于索引扫描,创建索引后我们需要保证查询是基于索引扫描的
indexOnly:为true时表示使用到了索引
覆盖索引查询
覆盖索引查询和MySQL中的类似。当查询条件和所要查询的列全部都在索引中时,MongoDB会直接从索引返回结果。这样的查询性能非常的高
SpringDataMongoDB
项目搭建
创建数据库 及连接账号
./bin/mongo
use mydbs
use admin
db.auth("mongoroot","123456")
use mydbs
db.createUser({user: "cqhshr",pwd: "123456",roles: [{role: "readWrite",db: "mydbs"}]})如果出现这种错误

?试试验证登录
mongo --host 127.0.0.1 --authenticationDatabase=admin --port 27017 -u root -p root?
(1)创建项目 bbs,pom.xml引入依赖

<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
(2)application.yml中加入以下配置
spring:
#数据源配置
data:
mongodb:
#主机地址
host: 127.0.0.1
#数据库
database: student
#默认端口是27017
port: 27017SpringDataMongoDB连接认证
当数据库配置了安全认证后,想要使用SpringDataMongoDB连接MongoDB,就需要使用 username:password@hostname/dbname 格式 ,username为用户名,password为密码 ?
spring:
#数据源配置
data:
mongodb:
# 认证时配置
uri: mongodb://username:password@127.0.0.1:27017/student?authSource=admin&authMechanism=SCRAM-SHA-1编写接口与实体类

package com.cqh.entity;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.index.CompoundIndex;
import org.springframework.data.mongodb.core.mapping.Document;
import org.springframework.data.mongodb.core.mapping.Field;
import org.springframework.stereotype.Component;
import java.io.Serializable;
import java.util.Date;
/**
* @author cqh
* @date 2024/1/14
* @Description
*/
@Document("user") //指定集合
@CompoundIndex(def = "{'age': -1}") //指定索引
public class User implements Serializable {
@Id
private String id;
@Field("name")
private String name;
// @Field 当名称与数据库一样时可以省略
private Integer age;
private String address;
private Date createTime;
private Integer state;
private Integer followNum;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public Integer getState() {
return state;
}
public void setState(Integer state) {
this.state = state;
}
public Integer getFollowNum() {
return followNum;
}
public void setFollowNum(Integer followNum) {
this.followNum = followNum;
}
public User() {
}
}
-
实体类需要使用
@Document注解标识为MongoDB文档,并指定集合名。 -
@Id注解指定文档的主键,不建议省略 -
@CompoundIndex注解指定复合索引,可以在Java类中添加索引,也可以在MongoDB中添加 -
@Indexed注解指定单字段索引。
package com.cqh.dao;
import com.cqh.entity.User;
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.stereotype.Repository;
/**
* @author cqh
* @date 2024/1/14
* @Description
*/
@Repository
public interface UserRepository extends MongoRepository<User,String> {
}
(3)启动项目,看控制台是否报错

编写测试类测试方法

package com.cqh;
import com.cqh.dao.UserRepository;
import com.cqh.entity.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.Date;
/**
* @author cqh
* @date 2024/1/14
* @Description
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class MongoDBTest {
@Autowired
private UserRepository userRepository;
@Test
public void testSave(){
User user = new User();
user.setName("张三");
user.setAge(18);
user.setAddress("重庆");
user.setCreateTime(new Date());
user.setFollowNum(0);
user.setState(1);
userRepository.save(user);
}
}
?运行测试类

?查看结果

@Test
public void testFindAll(){
List<User> all = userRepository.findAll();
all.forEach(user -> System.out.println("user = " + user));
}
加上service层

package com.cqh.service;
import com.cqh.entity.User;
import java.util.List;
/**
* @author cqh
* @date 2024/1/14
* @Description
*/
public interface UserService {
void save(User user);
List<User> findAll();
void deleteById(String id);
void update(User user);
User findById(String id);
}
package com.cqh.service.impl;
import com.cqh.dao.UserRepository;
import com.cqh.entity.User;
import com.cqh.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @author cqh
* @date 2024/1/14
* @Description
*/
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserRepository userRepository;
/**
* 保存
*
* @param user
*/
public void save(User user) {
userRepository.save(user);
}
/**
* 更新
*
* @param user
*/
public void update(User user) {
userRepository.save(user);
}
/**
* 根据id删除
*
* @param id
*/
public void deleteById(String id) {
userRepository.deleteById(id);
}
/**
* 查询所有
*
* @return
*/
public List<User> findAll() {
return userRepository.findAll();
}
/**
* 根据id查询
*
* @param id
* @return
*/
public User findById(String id) {
return userRepository.findById(id).get();
}
}
测试成功?
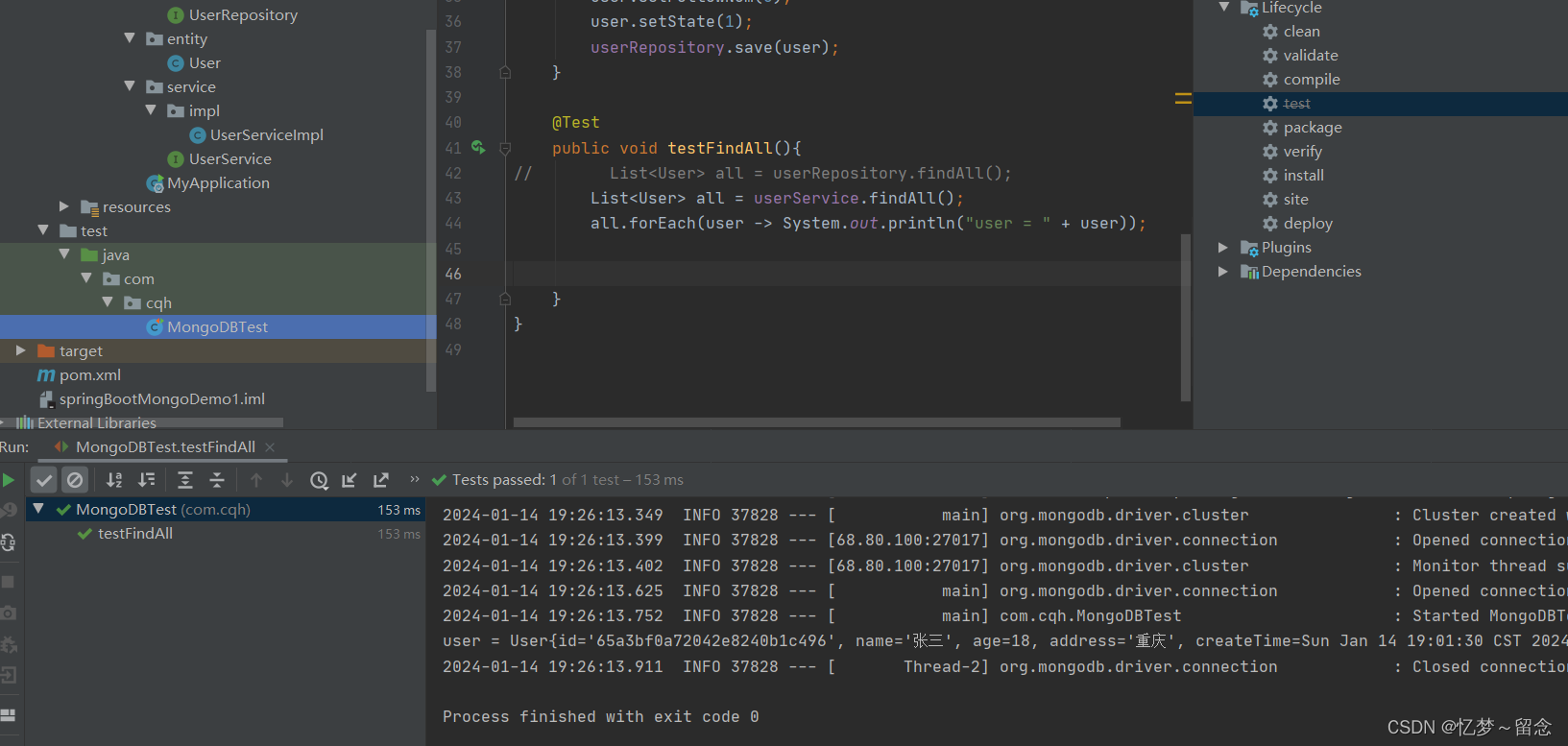
其他的改删都可以

package com.cqh;
import com.cqh.dao.UserRepository;
import com.cqh.entity.User;
import com.cqh.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.Date;
import java.util.List;
/**
* @author cqh
* @date 2024/1/14
* @Description
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class MongoDBTest {
@Autowired
private UserRepository userRepository;
@Autowired
private UserService userService;
@Test
public void testSave(){
User user = new User();
user.setName("张三");
user.setAge(18);
user.setAddress("重庆");
user.setCreateTime(new Date());
user.setFollowNum(0);
user.setState(1);
userRepository.save(user);
}
@Test
public void testFindAll(){
// List<User> all = userRepository.findAll();
List<User> all = userService.findAll();
all.forEach(user -> System.out.println("user = " + user));
}
@Test
public void testFindById() {
User user = userService.findById("65a3bf0a72042e8240b1c496");
System.out.println(user);
}
@Test
public void testUpdate() {
User user = new User();
user.setId("65a3bf0a72042e8240b1c496");
user.setAge(10);
user.setName("ddd");
user.setState(1);
user.setFollowNum(0);
user.setCreateTime(new Date());
userService.update(user);
}
@Test
public void testDelete() {
userService.deleteById("65a3bf0a72042e8240b1c496");
}
}
方法命名规范查询
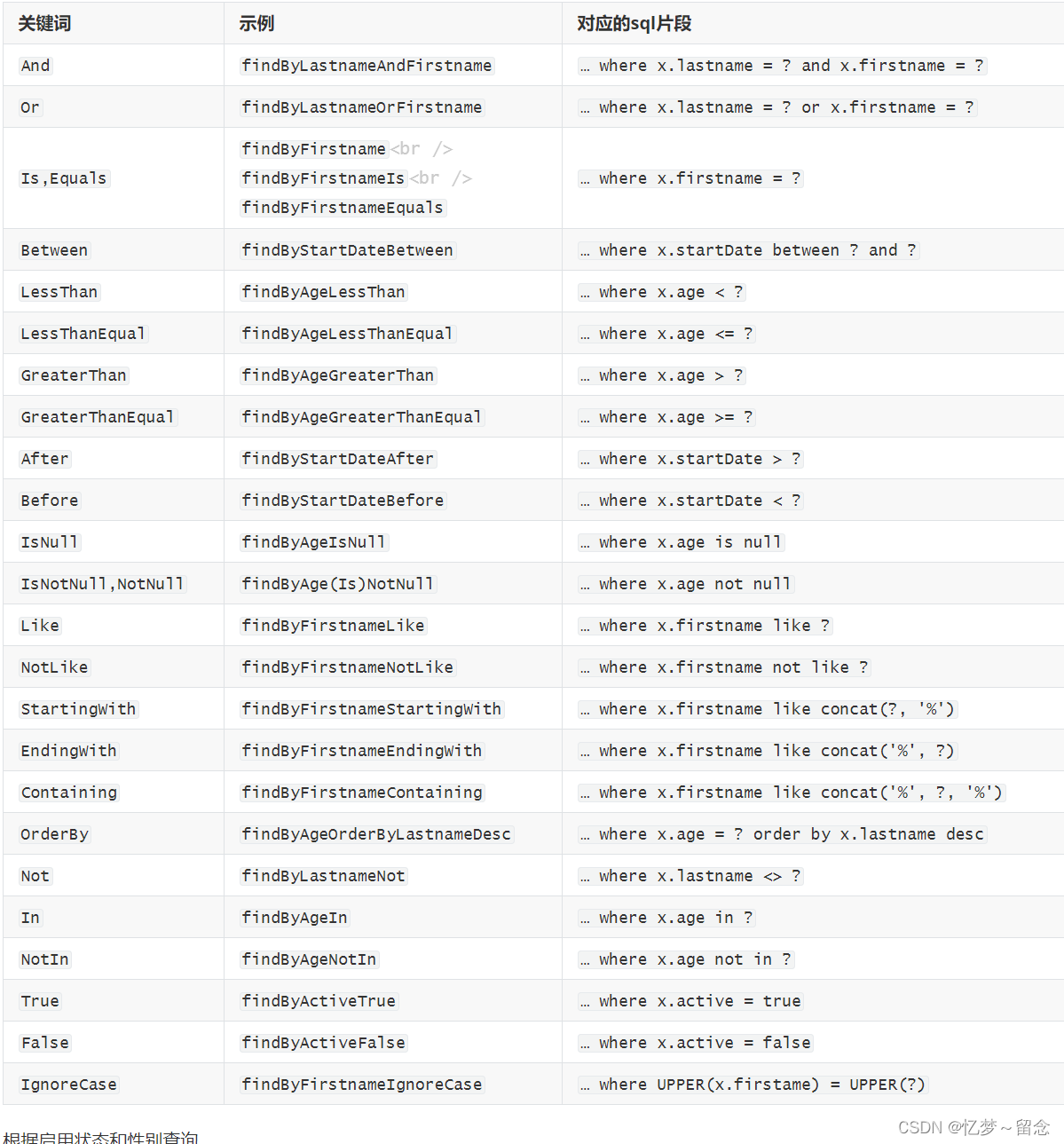
根据启用状态和性别查询
Repository中编写如下代码

Service中添加代码?

ServiceImpl
 ?MongoTemplate
?MongoTemplate
现在有个需求,我们需要给某个用户的关注量+1,下面的代码是实现方案
? ?public void incrFollowCount(String id) {
? ? ? ?User user = userRepository.findById(id).get();
? ? ? ?user.setFollowNum(user.getFollowNum() + 1);
? ? ? ?userRepository.save(user);
? }该方案实现起来虽然简单,但是性能不高。
我们只需要给关注量+1,并不需要姓名、地址等这些数据,因此也就没必要查询出这些字段,甚至于根本就不需要查询操作,直接更新就可以了。
我们可以使用MongoTemplate解决这个需求。
public void incrFollowCount(String id) {
// 构造查询对象
Query query = Query.query(Criteria.where("_id").is(id));
// 构造更新对象
Update update = new Update();
// follow字段+1
update.inc("followNum");
// 执行update
mongoTemplate.updateFirst(query, update, User.class);
}
分页查询
?分页查询主要涉及两个类。一个是Page,一个是Pageable



/**
* 根据名称分页查询
*
* @param age
* @param page
* @param size
* @return
*/
public Page<User> findByAgePage(Integer age, int page, int size) {
// 构造分页对象
PageRequest pageRequest = PageRequest.of(page - 1, size);
return userRepository.findByAge(age, pageRequest);
}
@Test
public void testFindByAgePage() {
Page<User> users = userService.findByAgePage(18, 1, 2);
System.out.println("总条数:" + users.getTotalElements());
System.out.println("总页数:" + users.getTotalPages());
System.out.println("本页数据:");
List<User> userList = users.getContent();
for (User user : userList) {
System.out.println(user);
}
}?实际开发中我们可能会需要能够多条件分页查询,上面的场景可能不满足需求。使用MongoTemplate也可以解决分页问题
/**
* 使用MongoTemplate分页查询
*
* @param page
* @param size
* @param user
* @return
*/
public List<User> findPageByTemplate(int page, int size, User user) {
// 构造一个查询对象
Query query = new Query();
// 设置参数
if (!StringUtils.isEmpty(user.getName())) {
query.addCriteria(Criteria.where("name").regex(user.getName() + ".*"));
}
if (user.getAge() != null) {
query.addCriteria(Criteria.where("age").lt(user.getAge()));
}
if (user.getSex() != null) {
query.addCriteria(Criteria.where("sex").is(user.getSex()));
}
// 跳过多少条
query.skip((page - 1) * size);
// 取出多少条
query.limit(size);
// 构造排序对象
Sort.Order order = new Sort.Order(Sort.Direction.DESC, "age");
// 设置排序对象
query.with(Sort.by(order));
return mongoTemplate.find(query, User.class);
}@Query注解
我们使用SpringDataJpa操作MySql的时候,尽管JPA已经非常强大,仍然避免不了手写sql的场景。
SpringDataMongoDB也存在类似的情况,因此我们可能会需要手写MongoDB的查询语句,使之操作更加灵活。
手写查询语句可以使用 @Query 注解。
需求1:根据 state 和 age 查询
这里我们需要使用 ?数字占位符 表达式来取出参数中指定位置的值,占位符从0开始。
/**
* 根据state和age查询
*
* @param state
* @param age
* @return
*/
@Query("{ state: ?0, age: ?1 }")
List<User> selectEnableUserByAge(Integer state, Integer age);需求2:有时候我们的参数可能过多,条件也可能不同,我们想传入一个实体类进行查询,直接取出实体类中的属性进行条件构造。
这里我们需要使用 SpEL 表达式,格式:?#{} 括号中使用 [下标] 来取出指定位置的参数,如 ?#{[0]} 则取出第一个参数。之后直接取出参数中的指定属性即可,如 ?#{[1].age} 就是取出第二个参数的age属性。
现在我们需要查询 性别为女,或者年龄在18岁以下的所有启用中的用户
/**
* 根据实体类查询
* 根据性别或者年龄,和状态查询
*
* @param user
* @return
*/
@Query("{ state: ?#{[0].state}, $or: [ {sex: ?#{[0].sex}}, {age: { $lt: ?#{[0].age} }} ] }")
List<User> selectByEntity(User user);同时,如果我们只想获取指定的字段,我们还可以使用第二个参数 fields 来进行投影查询
/**
* 根据实体类查询
* 根据性别或者年龄,和状态查询
*
* @param user
* @return
*/
@Query(value = "{ state: ?#{[0].state}, $or: [ {sex: ?#{[0].sex}}, {age: { $lt: ?#{[0].age} }} ] }",
fields = "{ name:1, age:1 }")
List<User> selectByEntity(User user);?副本集
简介
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。复制还允许您从硬件故障和服务中断中恢复数据。
通俗来讲,副本集就是多台机器进行同一数据的异步同步,从而使多台机器拥有同一数据的多个副本,并且能当主库宕机时在不需要用户干预的情况下自动切换到其他备份的数据库作为主库。并且,还可以利用副本访问做读写分离。
副本集的使用可以提供冗余和高可用性,提高系统负载。
MongoDB中的复制
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作更改,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB复制结构图如下所示:
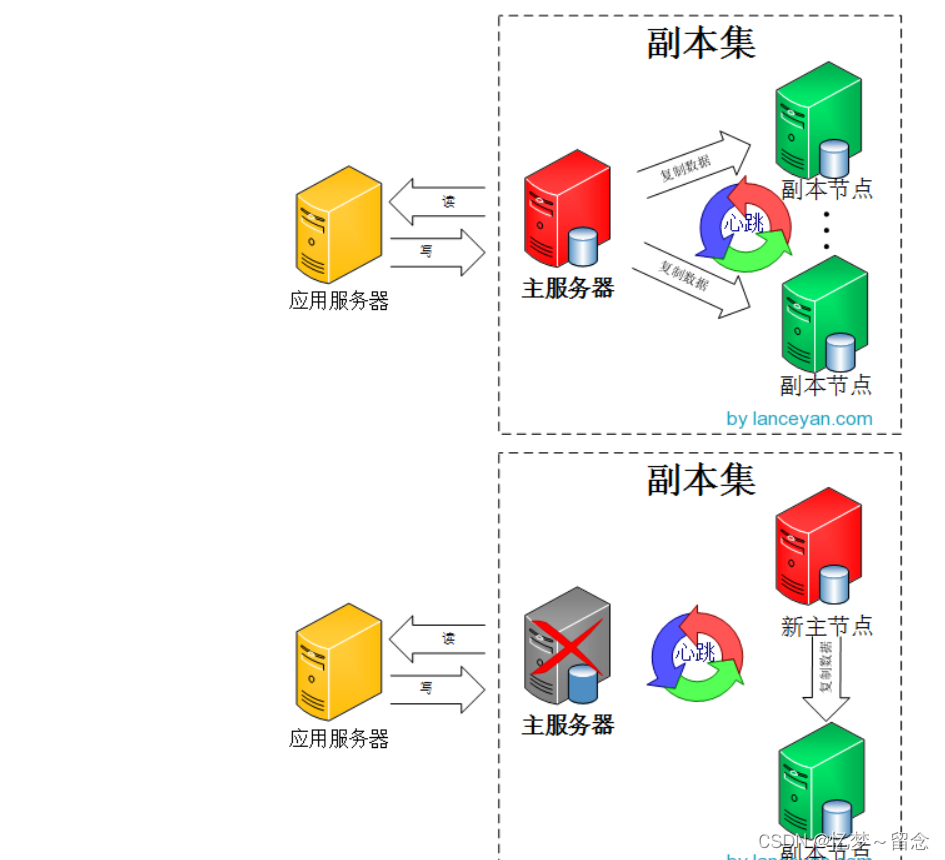
客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
主从复制和副本集的区别
主从复制和副本集的最大区别就是,副本集没有固定的主节点,整个集群会选出一个主节点,当主节点挂掉后,剩下的节点又会选出一个主节点。
副本集的角色
副本集主要有两种类型和三种角色
两种类型:
-
主节点(Primary):数据操作的主要连接点,允许读和写操作
-
从节点(Secondaries):数据冗余备份节点,可以读或选举为主节点
角色:
MongoDB主要有三种角色
主要成员(Primary):主节点,主要接收所有的写操作
副本成员(Replicate):主从节点通过备份操作以维护相同的数据集。只支持读操作,不支持写操作。拥有选举能力
仲裁者(Arbiter):不保留任何数据的副本,只具有选举作用。副本成员也可以作为仲裁者。

仲裁者永远是仲裁者,而主要成员与副本成员之间角色可能会发生变化。副本成员可能会因为主要成员的宕机而转为主要成员。主要成员也可能因为宕机并重新修复后成为副本成员。
尽可能保证主节点+副本的个数是奇数,这样就不需要加仲裁者就可以满足大多数的投票
如果主节点+副本的个数是偶数,建议加一个仲裁者。
分片
MongoDB除了副本集以外,还支持分片集群。分片可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
概念
分片(有时候也叫分区)是一种跨多台机器分布数据的方法,是指将数据拆分,将其分散到不同的机器上,处理更多的负载。
分片有两种解决方案:垂直扩展和水平扩展。
垂直扩展:增加更多的CPU和存储资源来扩展容量。
水平扩展:将数据集分布在多个服务器上。水平扩展就是分片
为什么使用分片
-
复制所有的写入操作到主节点
-
延迟的敏感数据会在主节点查询
-
单个副本集限制在12个节点
-
当请求量巨大时会出现内存不足。
-
本地磁盘不足
-
垂直扩展需要更多的钞能力
分片包含的组件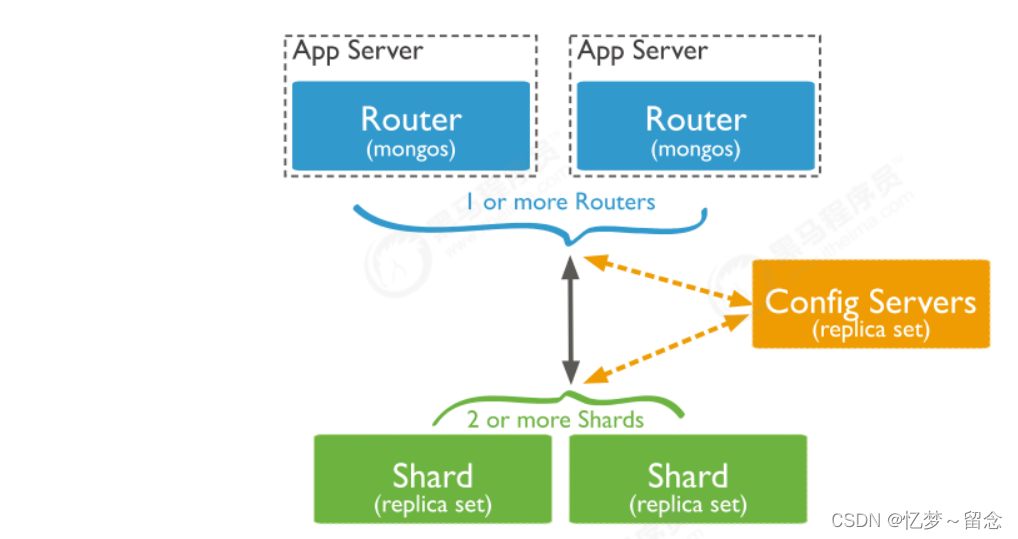
上图中主要有如下所述三个主要组件:
-
Shard:
分片,用于存储实际的数据块,实际生产环境中一个分片可以由多个副本集承担,防止主机单点故障
-
Config Server:
配置服务器。存储几群的元数据和配置。从MongoDB3.4开始,配置服务器必须是副本集
-
Query Routers:
路由,mongos充当查询路由器,在客户端和分片集群之间提供接口
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 提升FTP上传速度的方法(提升FTP下载速度的技巧)
- Halcon基于组件的模板匹配create_trained_component_model
- 六花阵图-第15届蓝桥第三次STEMA测评Scratch真题精选
- python拆分句子、去除句子符号等并分词
- 基于深度学习的停车位关键点检测系统(代码+原理)
- 为什么要禁止除GET和POST之外的HTTP方法
- FPGA 查找表的用途和内部功能
- 数据库的三范式是什么?
- 系列六、Spring Security中的认证 & 授权 & 角色继承
- AJAX初步与原理